Introduction
In both Windows and UNIX like platforms, the shared memory allows two unrelated processes to access the same logical memory. It is a very efficient way of transferring data between two running processes. However, shared memory does not provide any synchronization facilities by itself. There are no automatic facilities to prevent a second process starting to read the shared memory before the first process has finished writing to it. Because of the extra efforts of implementing the synchronization access, we normally use the shared memory as accessing a large area of data rather than making it an events queue driven solution.
The loop buffer presented in this article is an event queue like solution that supports multiple writes and single read access. The loop buffer partitions the shared memory as a header section and a data section. The header section keeps the loop buffer management data (such as Write Index) for synchronization control, while the data section is carefully organized as a loop buffer composed of zero or more data blocks.
The loop buffer keeps the "fast" characteristics of the shared memory. And it is a very portable and simple solution. The loop buffer keeps all the control and information data into the shared memory. The LoopBuffer::Read and LoopBuffer::Write are the only two functions to keep the wheel running. With slight modifications, the loop buffer can be used in various OS platforms and programming frameworks. For my recent practice purpose, I wrote the attached Linux version of the loop buffer solution. However, my initial loop buffer is actually for the Windows NT platform to support the continuous data transfer between kernel device drivers and an user level application. My other use case is to inspect Win32 API calling situation, for which I injected a DLL in to all the Win32 processes to hook certain APIs. The hooked functions use the loop buffer (shared with the central monitor process) to report the required information to the monitor process. All those use cases share identical loop buffer data structures and access algorithms.
Design
This section will explain the two core steps to implement the loop buffer: the shared memory partition and the access (read/write) functions design. Figure 1 shows the partition of the shared memory.
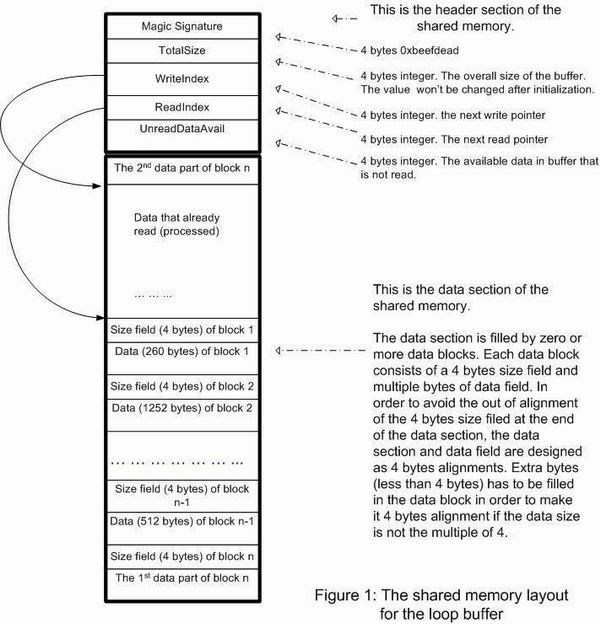
The shared memory is partitioned as a header section and a data section. The header section has the following fields:
Magic Signature: a 4 bytes integer field to identify if the shared memory is for the loop buffer access.
TotalSize: a 4 bytes integer. The TotalSize is the overall size in bytes of the data section. The loop buffer initialize function will configure this value. And the value won't be changed afterwards.
WriteIndex: The next write offset against the starting address of the data section. The 'Write' function will advance the WriteIndex at the beginning of each write operation.
ReadIndex: The next read offset against the starting address of the data section. The 'Read' function will advance the ReadIndex at the end of each read operation.
UnReadDataAvail: The number of data unread in the loop buffer. The 'Write' function will increase the UnReadDataAvail at the the beginning of each write operation, while the 'Read' function will decrease its value at the end of each read operation.
The data section consists of zero or more data blocks. Each data block has a leading 4 bytes of 'size' field following by the data area that stores the data bytes. The data section requires a 4 bytes alignment so that the 4 bytes 'size' field won't be broken into two pieces when it is located at the end of the buffer. Figure 1 clearly shows the loop buffer situation. The data part of the block n is split into two pieces when it is approaching the end of the data section. The first part fills to the end of the data section while the second data part starts at the beginning of the data section.
Now, let us come to the two key functions to run the loop buffer: Write and Read.

Figure 2 shows the write operation. The loop buffer supports multiple threads concurrently for write operations. Each write will run a piece of critical section code (atom operation in the figure 2) to check the buffer's conditions and adjust WIndex and UnReadDataAvail values. The other threads will have to use a different block of memory against WIndex and UnReadDataAvail. The following copy operations are not necessary in the critical section because other threads will write data to different data blocks. This solution minimizes the critical section code as just to adjust the header index values, and has better performance than putting all the data operations into the critical sections.
Figure 3 shows the Read operation which is very straightforward. I will just mention one issue for this part: writes under-run. In figure 2, we can see that the write threads update the UnReadDataAvail before copying the data and filling the size field of the data block. So it is possible that the read thread attempts to read the data block to which the write operation is not completed. This problem can be solved by introducing the writes completion semaphore to synchronize the write and read operations. However, sometimes users don't want to introduce extra synchronization objects in this case. My implementation is to reset all the read area to 0 so that each next read operation will know the write under-run cases if it detects that the data block is available (i.e. the UnReadDataAvail is large than 0) but its size field is 0. The read operation will not fetch the data if it detects the write under-run. This solution takes extra effort to clean up the read buffer. It works well, however, if we don't use semaphore to synchronize the access.
Using the code
I built the attached code in RedHat 7.3 with GCC 2.96. Users can download the code and run gmake or make. Three binary files will be generated under the './bin' directory.
- test_inprocess: The test applications that use the loop buffer for the inter-threads data transfer. Users can simply type './bin/test_inprocess' to run the program. This program generates five write threads and one read thread to run the loop buffer.
- test_ipc_r: The test application that reads the loop buffer shared with 'test_ipc_w'. Please type './bin/test_ipc_r' to launch the program. Users should launch the 'test_ipc_r' before running one or more 'test_ipc_w' programs.
- test_ipc_w: The test application that writes the loop buffer shared with 'test_ipc_r'. Please type './bin/test_ipc_w' to launch the program. Users should launch the 'test_ipc_r' before running one or more 'test_ipc_w' programs.
The attached code is more for demo purpose than practical use. My implementation of loop buffer did not have the semaphore synchronization between read and write functions. Users may add the semaphore synchronization code by writing their own wrapper functions over the CLoopBufIPC::Read and CLoopBufIPC::Write. Thus the program will have better responsiveness and less idle waits.
Others
I purposely wrote the loop buffer for Linux for my recent practice as a beginner in the UNIX like system. I am used to the Windows atom functions such as InterlockedCompareExchange and InterlockedExchangeAdd which are very handy with zero effort of resource maintenance. I could not find the equivalent atom functions in the UNIX like systems. And I have to use something like semaphore for the critical section code and write some buggy code to maintain those resources. I believe that UNIX like systems should have some better solutions for the atom operations and I will make certain improvements on this part in the future.
Richard Lin is senior software engineer of in Silicon Valley.
Richard Lin was born in Beijing and came to US in the fall of 1995. He began his first software career in bay area of California in 1997. He has worked for many interesting projects including manufacturing testing systems, wireless AP firmware and applications, email anti-virus system and personal firewalls. He loves playing go (WeiQi in Chinese) and soccer in his spare time. He has a beautiful wife and a cute daughter and enjoys his life in San Jose of California.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





