Introduction
As a part of a quite large project I am working on, I needed a fast tokenizer.
I could have used 'lexx', but it produces quite ugly C code. So I decided to write
a tokenizer myself - this project.
The project is a fast lexical analyzer/tokenizer and should be quite easy to use.
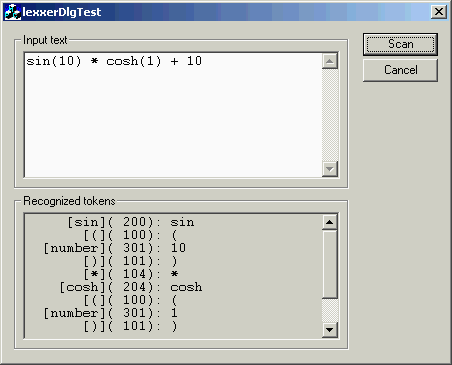
The demo application lets the user enter some text and scans it for a predefined set of
tokens which could be used by a calculator.
The code makes use of the STL and should compile neatly under warning level 4.
Unicode compiles should also work - all projects in the downloads have the build
configurations 'Debug'/'Release' as well as 'Debug Unicode'/'Release Unicode'
defined.
If you find bugs, please - in addition to posting a comment to the forum on this
article - send me an email: alexander-berthold@web.de.
The project
The project workspace contains three sub-projects (two in the source code only
download, lexxerDlgTest is omitted there):
- lexxer - the main project
- tkCommon - contains some shared base classes used by lexxer
- lexxerDlgTest - the sample MFC dialog based application
The lexxer project compiles to a static library, but the classes could
also be used directly. Because the project is part of a larger one, you may
find some parts a little bit 'overcoded' - but mostly the performance won't
suffer from that.
Usage
The explanation of the classes is better to understand I think after a piece of
code showing how to use the package. The output of the tokenizer goes to a callback
class of type cooLexxerListener, so let's start with that:
class cooMsgBoxListener : public cooLexxerListener
{
public:
virtual bool fCheckValid() const { return true; };
virtual bool fShouldDelete() const { return false; };
virtual void vRegisterToken(const std::tstring& strTokenText,
const cooLexxerTokenRule* pptrRule)
{
CString strTemp;
if(pptrRule!=NULL)
{
strTemp.Format("(%d): %s",pptrRule->nGetIDValue(),strTokenText.data());
::MessageBox(NULL,strTemp,_T("Token recognized"),MB_OK);
}
else
{
::MessageBox(NULL,strTokenText.data(),_T("Token not recognized"),MB_OK);
}
}
};
As you can see, this class does nothing but simply show a message box for each
token. Now the rules for the tokenizer:
void test()
{
std::tstringstream strm(_T("[seperators]\n")
_T("100:,\n")
_T("101:;\n")
_T("[tokens]\n")
_T("200:empty\n")
_T("201:blank\n")
_T("[rules]\n")
_T("300:strings\n")
_T("301:numbers\n")
cooLexxerMap map(strm);
This means:
- The tokens ',' and ';' can appear anywhere in the input stream
- The tokens 'empty' and 'blank' can appear only as whole words
- 'strings' and 'numbers' refer to predefined rules.
The numbers are the ID's the tokens are assigned. The argument pptrRule of
vRegisterToken carries this ID, by pptrRule->nGetIDValue().
The next part does the actual work:
cooLexxerTextInputStream tis(_T("100,empty,blank;blanky"));
cooMsgBoxListener lis;
cooLexxer lexxer(&tis,&map,&lis);
map.vLoadFromStream(strm);
while(!tis.fIsEofReached())
lexxer.vParseCharacter();
}
This would result in six message boxes with the caption "Token recognized" -
one for each of "100", ... , "blank" , ";" followed by one "Token not recognized"
message box.
More details on the tokenizer setup string
As you can see in the example above, the lexxer map is initialized from a string.
The format is like this:
[seperators]
{id}:{text}
...
[tokens]
{id}:{text}
...
[rules]
{id}:strings and/or
{id}:numbers
The number in front of each token, {id}, can later be used by the
cooLexxerListener - derived class to identify the type of the tokens,
See the sample code above (pptrRule->nGetIDValue).
The section [seperators] lists all tokens which can appear anywhere
in the input stream and thus act as seperators. To mention some of C++'s, this
could be "++" or "+=" or "?".
The section [tokens] lists all tokens that can appear only as a whole
word. In C++, this would be for example "for", "if" or even "while". Those cannot
appear within other text. In the example "forwhile" would be an undefined token and not "for" followed by "while".
The last section [rules] can currently only have at most two entries: strings and
numbers. strings translates to including
the class cooLexxerStringTokenRule into the tokenizer (see the code for
more remarks on that), while numbers translates to cooLexxerNumberTokenRule.
cooLexxerStringTokenRule recognizes strings in the form "text", where the text can also
consist of escape sequences in the form familiar from C++ (with some exceptions).
cooLexxerNumberTokenRule recognizes only numbers, nothing fancy yet (i.e. no 0x...)
The classes
Firstly: the source code intends to be well-documented, so please forgive me
if some of the information here is a bit too shallow. And please inform me if some
parts are hard to understand.
The main class of the lexxer project is cooLexxer.
It provides the following public methods:
cooLexxer::cooLexxer(cooLexxerInputStream *plisData,
cooLexxerMap *plmTokenMap,
cooLexxerListener *pllReceiver);
void cooLexxer::vParseCharacter();
The constructor takes three arguments. The first one is of the type
cooLexxerInputStream which - the name speaks for itself - feeds
the lexical analyzer with input. For an example on how to implement a class
derived from cooLexxerInputStream see the cooLexxerTextInputStream
class in the lexxer project.
The second argument is more interesting. The cooLexxerMap
contains the map of tokens (which is more like a tree).
Suppose the map is empty, and you add a token like "blank" to it like in the example
above. Then the root level map contains only one node, a 'b'. This node has
exactly one child node, a 'l'. This goes on until the 'k' follows, which is a leaf.
Now you add another token, "blanky". This would follow the same path until the
'k' is hit again, but adds another child node, the 'y'. This node is now also a
'leaf', meaning that this would be a completed token.
Now if the input stream contains a 'b', the tokenizer recognizes that that
is a valid start for at least one token. Continuing with 'l','a','n','k', no
character violates the order, but still both of the two tokens could match
the pattern. The next character would decide if it is the token "blank"
or "blanky" would be recognized.
As you can see, this requires the matching of only one character at a time -
not whole strings.
The last argument is the class 'listening' to the output of the tokenizer.
The pure virtual base class cooLexxerListener (which is itself
derived from ctkCheckValid and from ctkExternalObjectPointer, see below)
defines the method
virtual void cooLexxerInputStream::vRegisterToken(
const std::tstring& strTokenText,
cooLexxerTokenRule* pltrRule) = 0;
and is called by cooLexxer everytime a token has been recognized.
The toolkit classes
The tkCommon project defines the following partially virtual base classes (among a few
others which are not relevant here):
ctkCheckValidctkExternalObjectPointer
ctkCheckValid defines methods for debugging support and consistency
checks. It contains the following methods:
bool fCheckValid() const
Is supposed to return true if the class is in a consistent state.
static bool fRunDiagnostics()
Should run a self diagnosis of the class. As this method is static, it can't
be neither virtual, especially not pure virtual, so it is just a blueprint.
Currently cooLexxer, cooLexxerContext and
cooLexxerMap implement this method correctly.
The other class - ctkExternalObjectPointer - defines only one
method:
bool fShouldDelete() const
This method must return true if the pointer referring to this class
should be deleted on destruction of the object containing it.
More to come ...
The following is a list of to-do's I have in mind right now:
- Currently the project depends on the MFC. They do not use them directly, only
the heap debugging features. I plan to remove the MFC dependency and replace it
by the native API.
- Update the
cooLexxerNumberTokenRule to handle floating point
values and hexadecimal/octal notations correctly. I plan to do that within May 2001. - Add another class to handle character constants ('x') correctly.
- Fix bugs :)
If anyone finds a bug, I'll try update this page here as fast as I can.
I'll also post enhancements (which are to come) here and on my homepage,
absd.hypermart.net.
In the bigger project we are working on, we are right now finishing a
syntactical analyzer like 'yacc' - with some improvements like using C++ and
not being a LARL(1) analyzer - (and one big disadvantage: it's going to have some
more bugs ... :-). It also has the feature of automatically building a parse tree using
precendence rules and more neat features. We can't and won't give that away for free,
but if anyone is interested, we can provide a library w/o source code. You can freely
use that library in freeware projects - and we benefit from bug reports.
If you are interested, please mail me: alexander-berthold@web.de.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




