Introduction
XMI (XML Metadata Interchange) is a standard way of describing a UML class diagram. Most modern UML modeling tools now feature XMI support. In this article, I will demonstrate how to use the XMI-CodeDom Library I have created.
Thanks
First, I want to thank those who helped me build this library. It is not yet finished, but it has been an enjoyable hobby. First, I would like to thank Diana Mohan who provided me with a rather large XMI document (~8 megs) and some good feedback on the early stages of development. The large document helped me track down a lot of performance problems. Next, I'd like to thank the guys over at ArgoUML for making a free UML editor with import/export of XMI. Finally, thanks goes to www.zvon.org for their very helpful (although incomplete) XMI reference.
Example Windows Application
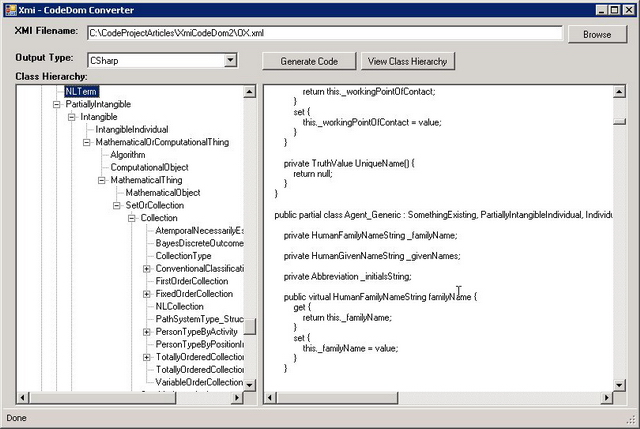
Included with the source code is an example application that allows the user to read an XMI document (pictured above). A CodeDom graph is created from that XMI which can then be used to determine the class hierarchy or generate code in a number of languages. This application really doesn't need much explanation. One thing that has to be recognized is that CodeDom allows multiple inheritance and so does XMI, but that doesn't mean it will compile in .NET.
Notes on XMI
There are two XMI versions covered by this library: 1.0 and 1.2. The two versions are substantially different and made for an interesting challenge. Here is an example of a small model done with version 1.0:
<XMI xmi.version="1.0">
<XMI.header>
<XMI.documentation>
<XMI.exporter>Novosoft UML Library</XMI.exporter>
<XMI.exporterVersion>0.4.20</XMI.exporterVersion>
</XMI.documentation>
<XMI.metamodel xmi.name="UML" xmi.version="1.3"/>
</XMI.header>
<XMI.content>
<Model_Management.Model xmi.id="xmi.1"
xmi.uuid="-64--88-1-3--a14cac0:10ab9466697:-8000">
<Foundation.Core.ModelElement.name>untitledModel</Foundation.Core.ModelElement.name>
<Foundation.Core.ModelElement.isSpecification xmi.value="false"/>
<Foundation.Core.GeneralizableElement.isRoot xmi.value="false"/>
<Foundation.Core.GeneralizableElement.isLeaf xmi.value="false"/>
<Foundation.Core.GeneralizableElement.isAbstract xmi.value="false"/>
<Foundation.Core.Namespace.ownedElement>
<Foundation.Core.Class xmi.id="xmi.2"
xmi.uuid="-64--88-1-3--a14cac0:10ab9466697:-7ffe">
<Foundation.Core.ModelElement.name>ClassA</Foundation.Core.ModelElement.name>
<Foundation.Core.ModelElement.visibility xmi.value="public"/>
<Foundation.Core.ModelElement.isSpecification xmi.value="false"/>
<Foundation.Core.GeneralizableElement.isRoot xmi.value="false"/>
<Foundation.Core.GeneralizableElement.isLeaf xmi.value="false"/>
<Foundation.Core.GeneralizableElement.isAbstract xmi.value="false"/>
<Foundation.Core.Class.isActive xmi.value="false"/>
<Foundation.Core.ModelElement.namespace>
<Foundation.Core.Namespace xmi.idref="xmi.1"/>
</Foundation.Core.ModelElement.namespace>
</Foundation.Core.Class>
</Foundation.Core.Namespace.ownedElement>
</Model_Management.Model>
</XMI.content>
</XMI>
And here is the exact same model, only done with version 1.2:
<XMI xmi.version = '1.2' xmlns:UML = 'org.omg.xmi.namespace.UML'>
<XMI.header>
<XMI.documentation>
<XMI.exporter>ArgoUML (using Netbeans XMI Writer version 1.0)</XMI.exporter>
<XMI.exporterVersion>0.20.x</XMI.exporterVersion>
</XMI.documentation>
<XMI.metamodel xmi.name="UML" xmi.version="1.4"/>
</XMI.header>
<XMI.content>
<UML:Model xmi.id = '.:0000000000000720'
name = 'untitledModel' isSpecification = 'false'
isRoot = 'false' isLeaf = 'false' isAbstract = 'false'>
<UML:Namespace.ownedElement>
<UML:Class xmi.id = '.:0000000000000721' name = 'ClassA' visibility = 'public'
isSpecification = 'false' isRoot = 'false'
isLeaf = 'false' isAbstract = 'false'
isActive = 'false'/>
</UML:Namespace.ownedElement>
</UML:Model>
</XMI.content>
</XMI>
There is definitely a difference. A lot more of the data is stored in attributes instead of elements, which significantly reduces file sizes. Coincidentally, that 8 meg XMI file I was talking about earlier is in version 1.2, so there's a lot of data in it.
At first, XMI doesn't seem all that bad. The namespaces and classes look pretty straightforward. How hard could it be? That's what I thought until I really got into it. Once you start dealing with multiplicities, associations, generalizations, abstractions, and specifications you realize that there is a lot going on in XMI. I could go into a lot of the implementation details of XMI, but it seems that not many people are really interested in that part. So I won't bore anyone with the details.
Understanding the Code
To handle the different versions and to make parsing the documents fast, easy-to-program, and use a small memory footprint, I chose an interesting design for the library. I'll try to write out how I arrived at this particular solution.
XMI Interfaces?
If you take a look at the version 1.0 XML, you can see some similarities between a class and a namespace. Both of them have child elements starting with "Foundation.Core.ModelElement" and "Foundation.Core.GeneralizableElement". The class definition has an added "Foundation.Core.Class" child element. This led me to believe that perhaps ModelElement and GeneralizableElement could be considered interfaces which are implemented by both Model and Class. Properties of these classes or interfaces can map into either an attribute or a specifically named child element.
Version 1.2 has a very different style, but I think the same rules still apply. A similar pattern reveals itself as you work with more complex documents. The placing of the attributes makes parsing the two versions quite a bit different.
Reflection
My first approach was to grab an XmlReader and just start going through the document element by element. I divided each important piece, like namespace and class, into its own class that was responsible for handling the parsing. This was going quite well, but was quickly becoming very tedious.
The logical next step was to encapsulate the code that gets repeated in each method. Unfortunately, this code was just different enough to give me a headache, so I turned to using reflection. The XMI CodeDom Library code included with this article uses that reflection-based parsing.
By using reflection, I could pull out all the actual XML reading code and just leave the classes as data containers. This ended up greatly improving the speed of development and cut out a lot of tedium. Here's an example of one such data container:
[XmiParser("UML:Association")]
public class XmiAssociation : XmiBaseClass, IModelElement, IGeneralizableElement
{
private List<XmiAssociationEnd> _Connection = new List<XmiAssociationEnd>();
public List<XmiAssociationEnd> Connection
{
get { return _Connection; }
}
#region IModelElement Members
private string _Name = string.Empty;
private bool _IsSpecification;
private string _Visibility = string.Empty;
[XmiAttribute]
public string Name
{
get { return _Name; }
set { _Name = value; }
}
[XmiAttribute]
public bool IsSpecification
{
get { return _IsSpecification; }
set { _IsSpecification = value; }
}
[XmiAttribute]
public string Visibility
{
get { return _Visibility; }
set { _Visibility = value; }
}
#endregion
#region IGeneralizableElement Members
private bool _IsRoot;
private bool _IsLeaf;
private bool _IsAbstract;
[XmiAttribute]
public bool IsRoot
{
get { return _IsRoot; }
set { _IsRoot = value; }
}
[XmiAttribute]
public bool IsLeaf
{
get { return _IsLeaf; }
set { _IsLeaf = value; }
}
[XmiAttribute]
public bool IsAbstract
{
get { return _IsAbstract; }
set { _IsAbstract = value; }
}
#endregion
}
Notice that there is an attribute on the class that tells the parser that this class holds data for "UML:Association". The parser will look at all the classes in a given namespace to find those with XmiParserAttribute attributes. When an element is encountered while parsing the XMI, the parser looks at its table of data containers to see if there's a match. It then uses reflection to fill in the properties of that container. The XmiAttributeAttribute marks properties that appear as attributes instead of as child elements.
Also in the above code, you can see that there is a list of XmiAssociationEnd objects. When the parser sees this, it will look in the "connection" element and attempt to parse the children of that element as XmiAssociationEnd objects. Those parsed objects are then added to the list.
Using the API
Using the library is pretty simple. All you have to do is use the XmiRoot class and provide it with a XmlReader. For example, let's grab a XmlTextReader on a file:
XmlTextReader xtr = new XmlTextReader("MyDiagram.xmi");
Now create an instance of XmiRoot and invoke its Parse method:
XmiRoot root = new XmiRoot();
root.Parse(xtr);
Now, the XmiRoot object contains a representation of the XMI model and can convert that into a CodeCompileUnit:
CodeCompileUnit ccu = root.GetCodeCompileUnit();
Or you can directly create code:
string s = root.GetParsedCode(CodeOutputTypes.CSharp);
As you can see, the API is straightforward. Parsing errors are simply bubbled up as exceptions. If there are nodes that the parser does not recognize, it will skip over them.
Summary
The way XMI is designed lends itself to make it easy to read using the method I've described above. With the parsing code written as it is, it will be easy to expand on the capabilities of the system. Reading other XMI objects is as simple as adding a new class to the project.
Take a look at part 2 to see how I improved upon the Reflection-based parsing by using CodeDom to dynamically create types.
Xmi CodeDom Library, Part 2 - Using dynamic types to increase performance[
^]
History
- 0.1 : 2006-05-23 : Initial version
XMI versions 1.0 and 1.2 are handled for one namespace with classes, data types, generalizations, associations, multiplicities, class attributes, and class operations. The system uses a Reflection-based parser.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




