Sample ASP.NET client
Sample Windows Forms client

Introduction
It has never been easier to create applications with search capabilities - open-source DotLucene [dotlucene.net] allows building powerful and super-fast full-text search applications. Moreover, it's easy to use. Let's demonstrate it by exploring Seekafile Server [seekafile.org] - a flexible indexing server with capabilities similar to that of Windows Indexing Service [microsoft.com].
This article is a follow-up of Desktop Search Application: Part 1. In that article, I have discussed indexing and searching Office document using DotLucene [dotlucene.net]. This time we will build a more serious application that can be either used directly or as a studying material for practical usage of DotLucene.
In this article, you will learn:
- How to perform indexing in the background.
- How to update documents in DotLucene index.
- How to create queries for DotLucene programmatically.
- How to use IFilter to parse Office documents, Adobe PDF and other file types correctly (it includes the updated parsing code from Desktop Search Application: Part 1).
Features
Seekafile Server [seekafile.org] is a Windows service that indexes documents in the specified directories and watches them for changes.
- Background indexing
- The indexer runs as a Windows service.
- You specify the directories to be watched for changes in the configuration file.
- Indexer works on the background (it doesn't slow down other operations).
- It recognizes any change within a second.
- Powered by DotLucene [dotlucene.net]
- Super-fast searching.
- The index is stored in DotLucene/Lucene 1.3+ compatible format.
- The index can be accessed directly from other applications (you can search even when the indexing is in progress).
- Access the index from any custom application (ASP.NET, Windows Forms application, Java application).
- Built-in support for common file formats:
- Microsoft PowerPoint (PPT)
- Microsoft Word (DOC)
- Microsoft Excel (XLS)
- HTML (HTM/HTML)
- Text files (TXT)
- Rich Text Format (RTF)
- Supports custom plug-ins written in C# or VB.NET.
- Supports IFilter for searching other extensions:
- Adobe Acrobat (PDF)
- Microsoft Visio (VSD)
- XML
- and other...
- Runs on Windows 2000/XP/2003
How it works
Architecture
The is the overview of the architecture:
The architecture is index-centric. It uses the index to communicate with the client search applications. The index is flexible enough to allow this:
- It is possible to search the index while the Seekafile Server is modifying it.
- There can be multiple clients accessing the index simultaneously.
- The changes are visible immediately to all the clients.
- The only information clients need to know is the index location and the available DotLucene document fields [dotlucene.net].
- The index is compatible with the Java version - you can access it from a Java client as well.
Watching changes
This is an overview of the indexing process:
- When the service is started it checks whether the index was already created at the specified location; if not it creates a new one:
if (!IndexReader.IndexExists(cfg.IndexPath))
{
Log.Echo("Creating a new index");
IndexWriter writer = new IndexWriter(cfg.IndexPath,
new StandardAnalyzer(), true);
writer.Close();
}
- It goes through all the indexed directories and adds all the files to the
IndexerQueue (to ensure that everything is indexed properly):
foreach (string folder in cfg.Items)
{
IndexerQueue.Add(folder);
startWatcher(folder);
}
- It starts the
FileSystemWatcher to watch all file changes in the indexed directories:
private void startWatcher(string directory)
{
watcher = new FileSystemWatcher();
watcher.Path = directory;
watcher.NotifyFilter = NotifyFilters.LastWrite |
NotifyFilters.FileName |
NotifyFilters.DirectoryName;
watcher.IncludeSubdirectories = true;
watcher.Filter = "";
watcher.Changed += new FileSystemEventHandler(OnChanged);
watcher.Created += new FileSystemEventHandler(OnChanged);
watcher.Deleted += new FileSystemEventHandler(OnChanged);
watcher.Renamed += new RenamedEventHandler(OnRenamed);
watcher.EnableRaisingEvents = true;
}
- If there is a change event, it adds the file to the
IndexerQueue:
private void OnChanged(object source, FileSystemEventArgs e)
{
if (Directory.Exists(e.FullPath) &&
e.ChangeType == WatcherChangeTypes.Changed)
return;
IndexerQueue.Add(e.FullPath);
}
private void OnRenamed(object source, RenamedEventArgs e)
{
IndexerQueue.Add(e.OldFullPath);
IndexerQueue.Add(e.FullPath);
}
IndexerQueue
The IndexerQueue works this way:
- It works in a separate thread. There is only a single thread processing a single queue at any moment:
public static void Start()
{
if (instanceDirectory == null)
throw new ApplicationException("You must " +
"initialize the queue first by calling Init().");
lock (runningLock)
{
if (!isRunning)
{
indexerThread = new Thread(new ThreadStart(Run));
indexerThread.Name = "Indexer";
indexerThread.Start();
}
}
}
- It processes the items from the queue. It waits if there is nothing in the queue:
while (!shouldStop)
{
if (nextPath != null)
{
lock (items.SyncRoot)
{
items.Remove(nextPath);
}
}
else
{
Thread.Sleep(100);
}
nextPath = next();
}
- If the path is a directory, it goes through it and adds all its content to the queue:
private static void parseDirectory(DirectoryInfo di)
{
foreach (FileInfo f in di.GetFiles())
{
Add(f.FullName, false);
}
foreach (DirectoryInfo d in di.GetDirectories())
{
parseDirectory(d);
}
}
- If the path does not exist, it deletes it from the index (
deleteDocuments) including all subfiles if there are any (deleteDirectory):
private static void deleteDocuments(string fullName)
{
IndexReader r = IndexReader.Open(instanceDirectory);
int deletedCount = r.Delete(new Term("fullname", fullName));
r.Close();
}
private static void deleteDirectory(string fullName)
{
IndexReader r = IndexReader.Open(instanceDirectory);
int deletedCount = r.Delete(new Term("parent", fullName));
r.Close();
}
- If the path is already in the index, it checks whether there is any change in file length, creation time, or last write time. To check whether the document is in the index, we create a query programmatically using
BooleanQuery and TermQuery classes:
private static bool isInIndex(FileInfo fi)
{
IndexSearcher searcher = new IndexSearcher(instanceDirectory);
BooleanQuery bq = new BooleanQuery();
bq.Add(new TermQuery(new Term("fullname",
fi.FullName)), true, false);
bq.Add(new TermQuery(new Term("length",
fi.Length.ToString())), true, false);
bq.Add(new TermQuery(new Term("created",
DateField.DateToString(fi.CreationTime))), true, false);
bq.Add(new TermQuery(new Term("modified",
DateField.DateToString(fi.LastWriteTime))), true, false);
Hits hits = searcher.Search(bq);
int count = hits.Length();
searcher.Close();
return count == 1;
}
- If there are changes it updates the document in the index. Updating requires deleting the old document and adding a new one:
if (isInIndex(fi))
return;
deleteDocuments(fi.FullName);
addDocument(fi);
- When adding a document, we record the following metadata:
- name: file name, e.g. document.doc,
- fullname: path, e.g. c:\storage\marketing\document.doc,
- parent: all parent directories, inserted as multiple fields, e.g. c:\; c:\storage; c:\storage\marketing,
- created: creation time,
- modified: last write time,
- length: file length in bytes,
- extension: file extensions, e.g. .doc.
Document doc = new Document();
doc.Add(new Field("name", fi.Name, true, true, true));
doc.Add(new Field("fullname", fi.FullName, true,
true, false));
DirectoryInfo di = fi.Directory;
while (di != null)
{
doc.Add(new Field("parent", di.FullName, true,
true, false));
di = di.Parent;
}
doc.Add(Field.Keyword("created",
DateField.DateToString(fi.CreationTime)));
doc.Add(Field.Keyword("modified",
DateField.DateToString(fi.LastWriteTime)));
doc.Add(Field.Keyword("length", fi.Length.ToString()));
doc.Add(Field.Keyword("extension", fi.Extension));
Parsing the files
DotLucene is able to index only plain text. Therefore, we need to extract the plain text from the rich file formats like Microsoft Word DOC, RTF, or Adobe PDF. The parsing can be done using a .NET plug-in found in the plugins subdirectory of the Seekafile Server or by IFilter interface (which is available in all Windows 2000/XP/2003 installations).
Read more about IFilter:
Plug-ins
Generally, there are two ways of extending the parsing system:
Read more about custom plug-ins:
There is also a sample plug-in included in Seekafile Server download [seekafile.org].
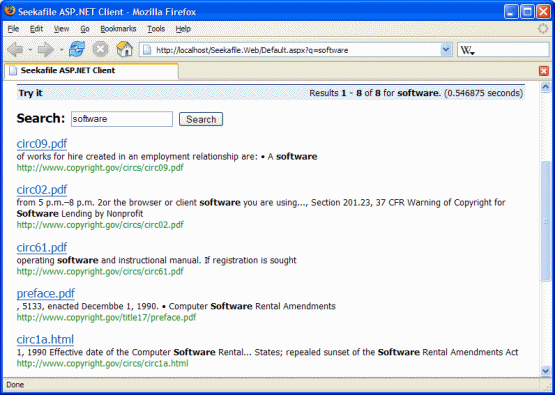
Sample ASP.NET client search application
This ASP.NET application accesses the index directly to search it. It searches the file content only (file and directory names are ignored). It shows a relevant snippet from the document.
Read more about building an ASP.NET client search application [seekafile.org].
Download [seekafile.org] this sample as a part of the Seekafile Server from seekafile.org.
Sample Windows Forms client search application
This Windows Forms application accesses the index directly to search it. It searches the file content only (file and directory names are ignored).
Read more about building a Windows Forms client search application [seekafile.org].
Download [seekafile.org] this sample as a part of the Seekafile Server from seekafile.org.
Features planned for next versions
- Exclude filters.
- Multiple indexes per service.
- Windows Forms client search application.
- Simple GUI management.
- Convenient installer.
- Indexing status and notification support.
- Multi-user desktop search.
Acknowledgements


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






