Introduction
One of the questions frequently asked on the forums here on CodeProject is how does one add elements to an XML file. At first read, this seems like a trivial task, but it's really not. The quickest way to do it is to open the XML file in an XmlDocument object, add the rows, and call the Save method. But how much memory does it take to do this and how fast is it? This article explores the options available when appending to an XML file.
I've recently updated this article to show what happens when using .NET 2.0. There really is a big difference in speed and memory usage between .NET 1.1 and .NET 2.0.
Setup
To test, we'll need a large XML file, some idea of how much memory we're using, and a timer. The timer is pretty simple since we don't really need a low-level performance timer if our XML file is big enough. Getting a big XML file is pretty easy:
XmlTextWriter xtw = new XmlTextWriter("Test.xml", System.Text.Encoding.UTF8);
xtw.Formatting = Formatting.Indented;
xtw.Indentation = 3;
xtw.IndentChar = ' ';
xtw.WriteStartDocument(true);
xtw.WriteStartElement("root");
for (int i = 0; i < 500000; i++)
xtw.WriteElementString("child", "This is child number " + i.ToString());
xtw.WriteEndElement();
xtw.WriteEndDocument();
xtw.Close();
Now we have a file called test.xml with 500,000 rows in it. The file will probably come out to 23 megs. The next thing we need is an idea of how much memory is being used. We can use WMI to grab the amount of heap memory being used for our process. That is accomplished with this class:
public class MemorySampler
{
private static PerformanceCounter _Memory;
static MemorySampler()
{
string appInstanceName = AppDomain.CurrentDomain.FriendlyName;
if (appInstanceName.Length > 14)
appInstanceName = appInstanceName.Substring(0, 14);
_Memory = new PerformanceCounter(".NET CLR Memory",
"# Total committed Bytes", appInstanceName);
}
public static long Sample()
{
long currMemUsage = _Memory.NextSample().RawValue;
return currMemUsage;
}
}
Please note that the code is written in .NET 1.1. So all you pattern-nazis out there ready to write in about not using a static class can calm down.
Getting an idea of how much memory you're using in .NET is pretty difficult. The CLR has grabbed a big chunk of memory and manages internally how your program uses it. This is why we need to use a big XML document because we want to make sure that the CLR is grabbing memory. Any readings from this performance counter have to be taken with a grain of salt because there is always that buffer zone and you never know when garbage collects are happening. This makes the testing environment a bit unstable, so we can't run one test right after another without closing the application.
Option 1: XmlDocument
The first approach we'll take is the simplest approach. We simply open the existing XML file in an XmlDocument object, append the row(s), and save it to the original filename. The code would look something like this:
XmlDocument doc = new XmlDocument();
doc.Load("test.xml");
XmlElement el = doc.CreateElement("child");
el.InnerText = "This row is being appended to the end of the document.";
doc.DocumentElement.AppendChild(el);
doc.Save("test.xml");
.NET 1.1 Results
Total committed bytes before opening XmlDocument : 663472
Total committed bytes after opening XmlDocument : 56794936
Total committed bytes after writing XmlDocument : 66146104
Time to append a row : 4.187634
The XmlDocument object is using 62 megs of memory to hold the 500,000 row document.
.NET 2.0 Results
Total committed bytes before opening XmlDocument : 1454072
Total committed bytes after opening XmlDocument : 63479800
Total committed bytes after writing XmlDocument : 63479800
Time to append a row : 2.902363
As you can see, they've improved the speed and memory usage in .Net 2.0.
Option 2: Copy to Memory, Add Row(s), Write to File
In this approach, we will use a MemoryStream to hold the XML document. We'll read from the current file until we get just before the end and simultaneously write into the MemoryStream. Then we add the rows, stick the end element tag for the document element on the end, rewind the stream, and write the whole thing out to the original file. The gist of it is in this code:
FileInfo fi = new FileInfo("test.xml");
XmlTextReader xtr = new XmlTextReader(fi.OpenRead());
MemoryStream ms = new MemoryStream((int)fi.Length);
XmlTextWriter xtw = new XmlTextWriter(new StreamWriter(ms));
Copy(xtr, xtw);
ms.Seek(0L, SeekOrigin.Begin);
xtr.Close();
Stream s = fi.OpenWrite();
s.Write(ms.GetBuffer(), 0, (int)ms.Length);
s.Close();
xtw.Close();
The Copy is the one doing all the work. This is actually why most people stick with the XmlDocument approach. Copying an XML document is not clear cut. The copy method I came up with may not be able to handle all XML documents, but it should handle a significant majority of them fairly well:
string docElemName = null;
bool b = true;
while (b)
{
xtr.Read();
switch (xtr.NodeType)
{
case XmlNodeType.Attribute:
xtw.WriteAttributeString(xtr.Prefix,
xtr.LocalName, xtr.NamespaceURI, xtr.Value);
break;
case XmlNodeType.CDATA:
xtw.WriteCData(xtr.Value);
break;
case XmlNodeType.Comment:
xtw.WriteComment(xtr.Value);
break;
case XmlNodeType.DocumentType:
xtw.WriteDocType(xtr.Name, null, null, null);
break;
case XmlNodeType.Element:
xtw.WriteStartElement(xtr.Prefix,
xtr.LocalName, xtr.NamespaceURI);
if (xtr.IsEmptyElement)
xtw.WriteEndElement();
if (docElemName == null)
docElemName = xtr.Name;
break;
case XmlNodeType.EndElement:
if (docElemName == xtr.Name)
b = false;
else
xtw.WriteEndElement();
break;
case XmlNodeType.EntityReference:
xtw.WriteEntityRef(xtr.Name);
break;
case XmlNodeType.ProcessingInstruction:
xtw.WriteProcessingInstruction(xtr.Name, xtr.Value);
break;
case XmlNodeType.SignificantWhitespace:
xtw.WriteWhitespace(xtr.Value);
break;
case XmlNodeType.Text:
xtw.WriteString(xtr.Value);
break;
case XmlNodeType.Whitespace:
xtw.WriteWhitespace(xtr.Value);
break;
}
}
xtw.WriteElementString("child", "This row is being" +
" appended to the end of the document.");
xtw.WriteEndElement();
xtw.Flush();
One thing you'll want to take note of if you're copying this code is that it looks at the name of the document element and then tries to find an end element with the same name. That is the indicator which tells the code it's close to the end of the file and needs to begin appending rows. It is entirely possible that your document element name is used for another element within your XML file. If I wasn't so lazy, I'd create a counter that would be incremented every time I see a start element with a name matching the document element and decremented in similar fashion.
.NET 1.1 Results
Total committed bytes before opening file : 663472
Total committed bytes after creating MemoryStream : 663472
Total committed bytes after writing to MemoryStream : 30433160
Total committed bytes after writing to file : 30433160
Time to append a row : 3.156351
The MemoryStream approach uses 28 megs of memory to store the entire file. Which is pretty understandable because the XML file generated is about 23 megs and the MemoryStream is simply a stream wrapped around a byte array.
.NET 2.0 Results
Total committed bytes before opening file : 1454072
Total committed bytes after creating MemoryStream : 1454072
Total committed bytes after writing to MemoryStream : 28729336
Total committed bytes after writing to file : 28729336
Time to append a row : 2.659330
Once again, a speed and memory usage improvement in .NET 2.0. Notice that the speed advantage between this approach and the XmlDocument approach has narrowed.
Option 3: Writing to a Temporary File
The MemoryStream from the previous option is kind of like a temporary file, but in memory. So, if we instead just write to a temporary file, then we can get rid of the extra memory usage. We can also eliminate an extra run through the document because the temporary file can be renamed to match the original file's name.
The code for this is below. Compare it to Option 2 to see the differences mentioned above:
FileInfo fi = new FileInfo("test.xml");
XmlTextReader xtr = new XmlTextReader(fi.OpenRead());
XmlTextWriter xtw = new XmlTextWriter(fi.FullName + "_temp", xtr.Encoding);
Copy(xtr, xtw);
xtw.Close();
xtr.Close();
fi.Delete();
File.Move(fi.FullName + "_temp", fi.FullName);
.NET 1.1 Results
Total committed bytes before opening files : 663472
Total committed bytes after opening files : 663472
Total committed bytes after writing to file : 5513136
Time to append a row : 2.578208
Not only is this faster than both the previous methods, it also has an extremely small memory footprint. We're looking at less than 5 megs of committed memory.
.NET 2.0 Results
Total committed bytes before opening files : 1454072
Total committed bytes after opening files : 1454072
Total committed bytes after writing to file : 5832696
Time to append a row : 1.582042
We actually have a slightly larger memory footprint with this approach. But the speed has increased by almost a second.
The downside of all this is that it can be hard to control temporary files. You want to make sure a file does not already exist with the same name and you need permissions to create, delete, and rename files in the directory you're working in. To make your appending code robust, you have to take into account all the problems that go with using a temporary file. Plus, it feels kinda kludgy.
Option 4: Custom Xml Serializable Classes
Another way to handle this is to use a custom class that serializes to XML using the XmlSerializer. This was suggested to me by CP'ian BoneSoft. To handle the records, I created a very simple custom class that looks like this:
using System;
using System.Collections.Specialized;
using System.Xml.Serialization;
namespace XmlAppending
{
[XmlRoot("root")]
public class Root
{
private StringCollection _ChildTexts;
[XmlElement("child")]
public StringCollection ChildTexts
{
get { return _ChildTexts; }
set { _ChildTexts = value; }
}
public Root() {}
}
}
While custom classes can come in all different shapes and sizes, this was pretty much the simplest way I could come up with of storing the data. The XmlSerializer class will automatically fill in the StringCollection with the inner text of each child node. Here's how the code looks for the test:
XmlSerializer xs = new XmlSerializer(typeof(Root));
FileInfo fi = new FileInfo("test.xml");
Stream inStream = fi.OpenRead();
Root r = xs.Deserialize(inStream) as Root;
inStream.Close();
r.ChildTexts.Add("This row is being appended to the end of the document.");
Stream outStream = fi.OpenWrite();
xs.Serialize(outStream, r);
outStream.Close();
.NET 1.1 Results
Total committed bytes before deserialization : 663472
Total committed bytes after deserialization : 54046560
Total committed bytes after writing to file : 54046560
Time to append a row : 3.500112
As you can see, this method is faster than the XmlDocument and uses less memory. However, it still does not compete with the other two options. But don't take me as saying you should not pursue something like this. Memory consumption could be a lot less as the XML gets more complicated. A custom class could have an enum or flag that converts into a much larger piece of XML or could compress child nodes into a much smaller space. The memory consumption could go below that of the MemoryStream in this case. The best way to put it: Your results may vary.
.NET 2.0 Results
Total committed bytes before deserialization : 1900536
Total committed bytes after deserialization : 41680888
Total committed bytes after writing to file : 41680888
Time to append a row : 2.039076
This shows a significant improvement in speed. This approach is now faster than all but option 3. It also uses significantly less memory than in .NET 1.1. Another thing to notice is that the initial memory usage is just a bit higher than the other .Net 2.0 tests. I tested this several times to be sure of it.
Option 5: DataSet
.NET 1.1 Results
We all know that the DataSet is a heavyweight object. It also poses some restrictions on the XML that it can read. But just how heavyweight is it? When doing the testing for this option I found that the typical test XML I was using with 500,000 rows was way too large for the DataSet to handle. It ended up taking on the order of hours to load up. So, I had to decrease the number of rows. The most I could get it to reasonably handle was 20,000 rows. Below are the results for using a DataSet with 20,000 rows but please, please, please don't misinterpret this as being competitive with the other options. If there's one thing you should take away from this article it's that using a DataSet in .NET 1.1 is a bad idea.
Total committed bytes before reading into DataSet : 663472
Total committed bytes after reading into DataSet : 13160368
Total committed bytes after writing to file : 10149808
Time to append a row : 18.359963
These results are for 20,000 records not 500,000 like the other tests.
My experiments showed me that the DataSet gets almost exponentially worse as the number of rows increases. For the 20,000 rows, it ends up using about 12 megs. Multiply that by 25 to estimate 500,000 rows and you get about 300 megs. A 300 meg DataSet compared to a 60 meg XmlDocument is definitely a heavyweight object. It's also slow and clunky. Bottom line, don't use it.
.NET 2.0 Results
Well, whatever it was in .NET 1.1 that made the DataSet unusable has most certainly been fixed in .NET 2.0. Not only is the DataSet now able to handle all 500,000 rows, it can do it in a fairly reasonable amount of time. Granted, it's still slow, but now it's at least an option.
Total committed bytes before reading into DataSet : 1454072
Total committed bytes after reading into DataSet : 140300280
Total committed bytes after writing to file : 140300280
Time to append a row : 13.250085
These results are for 500,000 records.
Suddenly the DataSet doesn't feel so heavy anymore. Sure, it doesn't compare speed wise with the other options, but it's an incredible improvement over .NET 1.1. It is still a memory hog, using about 140 megs to load our 500,000 row XML file, but much less so than in 1.1.
Summary
This graph shows the performance monitor's take on the whole thing for .NET 1.1:
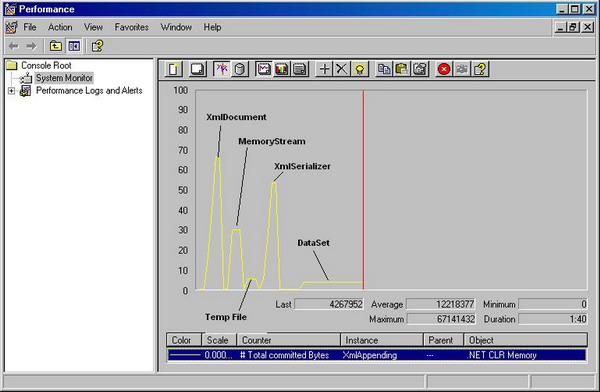
The graph for .NET 2.0 is pretty similar with the big change being that the DataSet actually works now:

Kudos to Microsoft for doing such an excellent job of tuning the code to get such large speed and memory usage improvements in .NET 2.0. Speed improvements on the order of seconds are very significant. They also made the DataSet a lot lighter and faster. Developers should feel less anxiety about passing DataSets around.
This article was not meant to tell you the only correct way to append to a large XML file. It was meant to show you all the different options and explain the pitfalls with real data. A peer might tell you to not use an XmlDocument because it uses too much memory, but they might not know exactly how much. I wanted to know for sure. If you're ever in a forum or having an argument with a colleague about the finer points of appending to XML files, you can link them to this article. The only option here which is not viable is the DataSet in 1.1. The rest depend on your situation and needs.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




