Introduction
This article introduces a String.ReplaceMany extension method, which
performs multiple string replacements at one time. A single ReplaceMany
method invocation is equivalent to a sequence of calls to the String.Replace[^]. The following
snippet:
string str = "abab cdecde ab";
string result = str.ReplaceMany(new [] {"ab", "cde"}, new [] {"x", "y" });
will give the same result as:
result = str.Replace("ab", "x").Replace("cde", "y");
Performance is the main difference between
those two methods. In the best (and predictable) scenarios, the ReplaceMany
is up to 10 times faster than the .NET Framework Replace. In the worst-case
scenarios, the ReplaceMany method performs slower for a small number
of replace strings, however it catches up when there are more of them. Generally,
in most scenarios the introduced method's performance is the same or better.
Note: The above code is not an example of the method's application. These snippets
was intended to describe a functionality of the ReplaceMany method.
For actual usage scenarios, see the "Performance Tests" section. More
test results are availible for download in the charts.zip archieve.
The project targets .NET 4.0, but it will compile under .NET 2.0, after removing
the this keyword from the method's signature.
Background
The idea came up while developing a code which took a template text, which contained
markers in form @variable. These markers was then replaced with actual
content, using the String.Replace method. I have realized that performance
had been dropping as the project was developed and I was looking for ways to optimize
the code. One thing which has caught my eye was a sequence of Replace
method invocations.
Using the Code
A full method signature is
string ReplaceMany(this string str, string[] oldValues, string[] newValues,
int resultStringLength = 0)
It is an extenstion method of a String class, which takes two obligatory
parameters and one optional.
oldValues - an array of strings which should be searched for in the
processed string,newValues - an array of replacement strings,resultStringLength - a tip for the method saying how big the result
string will probably be. This parameter should be overestimated. The idea is to
prevent a buffer reallocation and therefore improve performace by removing an unnecessary
copying. If the result string length is not easily predictible, then this parameter
should be omitted.
Remarks
If one symbol is a substring of another then the operation becomes ambigous. In
such cases, symbols are replaced in the same order as they appear in the array.
For example:
"aabab".Replace("a", "x").Replace("ab", "y").Replace("aab", "z");
"aabab".ReplaceMany(new string[] { "a", "ab", "aab" }, new string[] { "x", "y", "z" });
"aabab".Replace("aab", "z").Replace("ab", "y").Replace("a", "x");
"aabab".ReplaceMany(new string[] { "aab", "ab", "a" }, new string[] { "z", "y", "x" });
Another kind of ambigouity occurs, when a replacent is equal to a latter "old value", like here:
"abc".Replace("b", "c").Replace("c", "!");
The .NET Replace method returns "b!!", which is incorrect
in the sense of replacing multiple strings at one time, because "b"
is replaced with "!" instead of "c". The ReplaceMany
method's behaviour is different and the return value is "ac!".
"abc".ReplaceMany(new string[] { "b", "c" }, new string[] { "c", "!" });
Note: this behaviour was introduced in an article's update. A behaviour of the first
version of method was undefined for ambigous cases.
That would be all about a usage of the method. Now let's dig into an implementation.
Implementation
The implementation is a bit tricky and contains a plenty of optimizations, including
unsafe code blocks and calls to native memory management functions. The first version
used fixed blocks[^]
inside a loop, but it caused an unexpected performance drop. In the current version,
strings are pinned at the beginning and freed at the method's exit point. By "pinning",
I mean telling GC (a garbage collector, the .NET Framework memory management engine)
not to move an object around in a memory while operating on it. It is necessary
when using pointers (unsafe code) and can be accoplished by using fixed
statements or a GCHandle structure[^].
For comparing characters, the memcmp function[^]
is used. Memory copying is performed by the memcpy[^].
public static unsafe string ReplaceMany(this string str,
string[] oldValues, string[] newValues, int resultStringLength)
{
int oldCount = oldValues.Length;
int newCount = newValues.Length;
if (oldCount != newCount)
throw new ArgumentException("Each old value must match exactly one new value");
for (int i = 0; i < oldCount; i++)
{
if (string.IsNullOrEmpty(oldValues[i]))
throw new ArgumentException("Old value may not be null or empty.", "oldValues");
if (newValues[i] == null)
throw new ArgumentException("New value may be null.", "newValues");
}
int strLen = str.Length;
int buildSpace = resultStringLength == 0 ? strLen << 1 : resultStringLength;
char[] buildArr = new char[buildSpace];
GCHandle buildHandle = GCHandle.Alloc(buildArr, GCHandleType.Pinned);
GCHandle[] oldHandles = new GCHandle[oldCount];
GCHandle[] newHandles = new GCHandle[newCount];
int* newLens = stackalloc int[newCount];
int* oldLens = stackalloc int[newCount];
char** oldPtrs = stackalloc char*[newCount];
char** newPtrs = stackalloc char*[newCount];
for (int i = 0; i < oldCount; i++)
{
oldHandles[i] = GCHandle.Alloc(oldValues[i], GCHandleType.Pinned);
newHandles[i] = GCHandle.Alloc(newValues[i], GCHandleType.Pinned);
oldPtrs[i] = (char*)oldHandles[i].AddrOfPinnedObject();
newPtrs[i] = (char*)newHandles[i].AddrOfPinnedObject();
newLens[i] = newValues[i].Length;
oldLens[i] = oldValues[i].Length;
}
int buildIndex = 0;
fixed (char* _strFix = str)
{
char* build = (char*)buildHandle.AddrOfPinnedObject();
char* pBuild = build;
char* pStr = _strFix;
char* endStr = pStr + strLen;
char* copyStartPos = pStr;
while (pStr != endStr)
{
bool find = false;
for (int i = 0; i < oldCount; ++i)
{
int oldValLen = *(oldLens+i);
if (oldValLen > 0 && pStr + oldValLen <= endStr)
{
char* _oldFix = *(oldPtrs + i);
if (*pStr == *_oldFix)
{
find = oldValLen == 1;
if (!find)
{
if (*(pStr + 1) == *(_oldFix + 1))
find = oldValLen == 2
|| 0 == memcmp((byte*)(pStr + 2), (byte*)(_oldFix + 2), (oldValLen - 2) << 1);
}
if (find)
{
int newValLen = newLens[i];
char* newFix = newPtrs[i];
int copyLen = (int)(pStr - copyStartPos);
if (buildIndex + newValLen + copyLen > buildSpace)
{
buildHandle.Free();
int oldSpace = buildSpace;
buildSpace = Math.Max((int)(buildIndex + newValLen + copyLen), buildSpace << 1);
buildArr = ExpandArray(buildArr, oldSpace, buildSpace);
buildHandle = GCHandle.Alloc(buildArr, GCHandleType.Pinned);
build = (char*)buildHandle.AddrOfPinnedObject();
pBuild = build + buildIndex;
}
if (copyLen > 0)
{
memcpy((byte*)(pBuild), (byte*)copyStartPos, copyLen << 1);
buildIndex += copyLen;
pBuild = build + buildIndex;
}
memcpy((byte*)(pBuild), (byte*)newFix, newValLen << 1);
pBuild += newValLen;
buildIndex += newValLen;
pStr += oldValLen;
copyStartPos = pStr;
break;
}
}
}
}
if (!find)
pStr++;
}
if (copyStartPos != pStr)
{
int copyLen = (int)(pStr - copyStartPos);
if (buildIndex + copyLen > buildSpace)
{
buildHandle.Free();
int oldSpace = buildSpace;
buildSpace = Math.Max((int)(buildIndex + copyLen), buildSpace << 1);
buildArr = ExpandArray(buildArr, oldSpace, buildSpace);
buildHandle = GCHandle.Alloc(buildArr, GCHandleType.Pinned);
build = (char*)buildHandle.AddrOfPinnedObject();
pBuild = build + buildIndex;
}
memcpy((byte*)(pBuild), (byte*)copyStartPos, copyLen << 1);
buildIndex += copyLen;
}
}
for (int i = 0; i < newCount; i++)
{
oldHandles[i].Free();
newHandles[i].Free();
}
buildHandle.Free();
return new string(buildArr, 0, buildIndex);
}
The ExpandArray method is used to allocate extra space for a buffer.
public static unsafe char[] ExpandArray(char[] array, int oldSize, int newSize)
{
if (oldSize > newSize || oldSize > array.Length)
throw new ArgumentOutOfRangeException();
char[] bigger;
bigger = new char[newSize];
fixed (char* bpt = bigger, apt = array)
memcpy((byte*)bpt, (byte*)apt, oldSize<<1);
return bigger;
}
The C++ functions exposed by msvcrt.dll are called using P/Invoke[^].
[DllImport("msvcrt.dll", CallingConvention = CallingConvention.Cdecl)]
private static extern unsafe int memcmp(byte* b1, byte* b2, int count);
[DllImport("msvcrt.dll", CallingConvention = CallingConvention.Cdecl)]
private static extern unsafe int memcpy(byte* dest, byte* src, int count);
Performance tests
I have done a lot of testing to ensure that I haven't implemented a method which
is actually slower that sequential calling String.Replace. The results
are approximate, but they reflect a nature of the method. Here are
some interesing results.
The ReplaceMany method performs best when small strings are replaced
with big strings. In a test environment, I'd been using 10-character long strings
as "old values" and 100-character strings as "new values". The
variable parameter was a number of replace strings, aka a number of String.Replace
invocations. The results were as following:
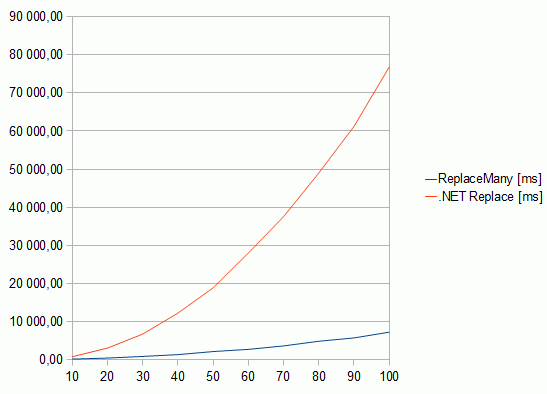
Replacement count, ReplaceMany, .NET Replace
1 43,26 0,69
2 108,26 2,77
3 4,33 6,44
4 5,30 11,87
5 6,65 17,95
6 7,53 26,05
7 8,87 38,90
8 10,03 49,83
9 11,39 59,98
10 12,14 72,69
20 24,57 289,05
30 39,17 638,13
40 62,23 1 135,73
50 79,46 1 769,71
60 105,82 2 562,58
70 128,08 3 493,79
80 148,00 4 540,07
90 176,70 5 752,98
100 203,57 7 105,83
All results are in miliseconds and multiplied by 1000, for clarity.
The ReplaceMany
method starts to win when there are 3 replacement strings. With 100 strings, there is about a 35x
performance increase compared to a standard .NET code.
The testing code is very striaghtforward. A code which generates problem instances:
old = new string[repcount];
newv = new string[repcount];
build.Clear();
o = new StringBuilder(101);
n = new StringBuilder(101);
for (int i = 0; i < repcount; i++)
{
for (int j = 0; j < oldLength; j++)
{
o.Append((char)r.Next(48, 70));
}
for (int j = 0; j < newLength; j++)
{
n.Append((char)r.Next(48, 70));
}
old[i] = o.ToString();
newv[i] = n.ToString();
for (int j = 0; j < extra; j++)
{
build.Append((char)r.Next(48, 70));
}
build.Append(o.ToString()).Append(" ").Append(o.ToString());
o.Clear();
n.Clear();
}
str = build.ToString();
Actual testing:
stopwatch.Reset();
stopwatch.Start();
for (int i = 0; i < 1000; i++)
str.ReplaceMany(old, newv);
stopwatch.Stop();
TimeSpan me = stopwatch.Elapsed;
Console.Write(" {0}", me.TotalMilliseconds);
stopwatch.Reset();
stopwatch.Start();
for (int i = 0; i < 1000; i++)
{
for (int j = 0; j < repcount; j++)
{
str = str.Replace(old[j], newv[j]);
}
}
stopwatch.Stop();
TimeSpan their = stopwatch.Elapsed;
Some other results:
In this example, replacement strings had the same length as the old ones.
Old strings' lengths: 10
Replacement strings' lengths: 10
Extra characters added to test string: 0
Replacement count, ReplaceMany, .NET Replace
1 1,46 0,09
2 1,78 0,30
3 2,67 0,78
4 4,43 1,58
5 4,78 1,86
6 5,20 2,79
7 6,27 3,94
8 7,00 5,13
9 7,81 7,29
10 9,38 7,92
20 19,32 30,88 <<< ReplaceMany starts to win
30 31,37 68,43
40 48,19 119,84
50 66,90 187,91
60 83,35 266,79
70 105,66 378,26
80 131,70 498,32
90 156,60 614,43
100 177,36 759,50
150 333,09 1 721,25
200 510,63 3 002,31
250 776,97 4 727,57
300 1 049,78 6 716,75
Here the Replace was figuratively dead.
Old strings' lengths: 10
Replacement strings' lengths: 1000
Extra characters added to test string: 100
Replacement count ReplaceMany .NET Replace
1 4,87 7,51
2 8,83 30,85
3 20,28 70,18
4 30,21 124,02
5 40,42 192,79
6 52,00 276,55
7 69,28 365,53
8 79,49 478,08
9 97,92 605,11
10 114,78 748,88
20 386,18 3 015,35
30 817,37 6 701,57
40 1 294,36 12 204,29
50 2 099,41 18 854,68
60 2 662,90 27 963,31
70 3 574,89 37 529,65
80 4 803,84 49 003,12
90 5 677,84 61 244,01
100 7 182,78 76 841,37
This is the worst-case scenario, and the .NET code wins. Extra characters added
to a test string ensure that there are no buffer reallocations. It seems that the
.NET's Replace uses a slow algorithm for that. A difference decreases
as a number of replacement strings increases but still the ReplaceMany
method is slower.
Old strings' lengths: 10
Replacement strings' lengths: 10
Extra characters added to test string: 100
Replacement count ReplaceMany .NET Replace
1 2,45 0,47
2 4,45 1,81
3 10,19 4,97
4 17,20 7,27
5 21,53 10,65
6 31,20 16,17
7 38,30 22,71
8 57,25 31,58
9 54,21 34,68
10 84,23 47,56
20 256,46 189,46
30 568,25 409,81
40 913,33 693,08
50 1 363,18 1 084,12
60 1 918,29 1 549,88
70 2 615,43 2 111,76
80 3 320,37 2 755,09
90 4 193,21 3 484,52
100 5 164,74 4 306,08
When replacing 10-character strings with single characters, ReplaceMany
looses, too.
Old strings' lengths: 10
Replacement strings' lengths: 1
Extra characters added to test string: 0
Replacement count ReplaceMany .NET Replace
1 1,27 0,06
2 2,38 0,12
3 3,80 0,17
4 4,51 0,25
5 6,19 0,38
6 5,68 0,79
7 7,00 0,68
8 9,44 0,87
9 10,71 1,49
10 9,58 1,59
20 22,00 5,50
30 34,80 9,15
40 45,64 15,61
50 62,99 27,36
60 88,32 33,80
70 96,93 45,69
80 115,93 60,93
90 140,77 77,02
100 162,57 95,69
150 290,59 200,42
200 453,33 348,31
250 662,53 540,45
300 884,62 783,57
350 1 153,41 1 047,60
400 1 473,32 1 363,51
450 1 810,70 1 782,50
500 2 208,63 2 186,38
550 2 691,38 2 635,10
600 3 367,29 3 149,86
650 3 959,81 3 655,76
700 4 585,45 4 260,98
750 5 176,85 4 854,98
800 6 012,21 5 769,26
In this example, single characters was replaced with two-character strings. The
String.Replace crashed every time! It was also very
unstable.
Old strings' lengths: 1
Replacement strings' lengths: 2
Extra characters added to test string: 0
Replacement count ReplaceMany .NET Replace
1 1,20 0,11
2 1,46 0,22
3 3,02 14,07
4 4,51 1,08
5 5,92 193,21
6 7,67 99,14
7 8,88 5,08
8 11,39 7,68
9 12,78 8,48
10 14,98 10,62
20 36,87 579,65
30 64,54 <<< String.Replace crashes
Unhandled Exception: OutOfMemoryException.
Similarily, when 2-character pairs was replaced with 4-character strings:
Old strings' lengths: 2
Replacement strings' lengths: 4
Extra characters added to test string: 0
Replacement count ReplaceMany .NET Replace
1 2,26 0,08
2 2,37 0,23
3 2,79 0,48
4 3,54 0,85
5 4,59 1,10
6 4,99 1,31
7 6,04 2,00
8 6,90 2,39
9 8,37 2,90
10 8,43 3,68
20 18,10 13,87
30 29,36 230,67 <<<
40 51,07 64,50
50 58,87 100,51
60 81,64 156,22
70 99,94 2 415,98
80 115,88 289,54
90 135,12 1525,4413
100 159,60 24 188,11 << 24 seconds WTF? (reproducable)
Summary
Concluding, the ReplaceMany is best when you have to replace many different
short strings with long strings. Filling a script template with data is a good example
of a practical application. Moreover, using the ReplaceMany method
seems to be safer in some scenarios, when the .NET method either crashes or behaves
unstable.
History
- 16 Jan 2012 -- defined a behaviour in ambigous cases, changed class name to ReplaceManyExtensions.
- 04 Jan 2012 -- the first version posted.
My name is Jacek. Currently, I am a Java/kotlin developer. I like C# and Monthy Python's sense of humour.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 But above all I hope someone will read this and give me some constructive criticism and/or new ideas. Please comment!
But above all I hope someone will read this and give me some constructive criticism and/or new ideas. Please comment!


