Abstract
This paper describes a C# program developed in Microsoft Visual Studio for extracting numerical data from Web pages and transferring it to a database. It covers technical issues such as -
- Using an Internet Explorer control for background HTTP communication and text data extraction
- Creating subclasses of IFormattable to handle specialized numerical formats
- Using idle event processing to implement non-blocking processes without using separate threads
- Strategies for developing parsers for Web page contents
- Integration with DMBS systems using native SQL
- Use of the OleDBConnection class
- Specific Visual Studio problem areas such as References across multiple development platforms
All code necessary to build and modify the application is provided, along with this document which details the operation of the system and indicates places where changes can be made to parse different types of data from pages on the WWW.
Introduction
Much has been made in recent years about ripping CDs. There are many good reasons for this, running from the deliberately inferior materials used by manufacturers to the desire of individuals to create their own custom CDs of the songs they want in the order that they want. Many of these same needs and desires can apply to other forms of data, for example the financial data used in this application. Many websites provide public data in proprietary forms, primarily as a mechanism for capturing eyeballs and selling them to advertisers. The means by which this data is provided is often of marginal benefit, i.e. the data is available, but not in the form that supports the most efficient usage. The approach that is less suitable for the functional consumer, the web site visitor, is often the one more suitable for the real consumer, the advertising purchaser.
This is the first in a series of papers I expect to be writing on the construction and use of scraping software, software tools that automatically interrogate web sites for data of interest and repackage the retrieved data into a most useful form. This paper will concentrate on the retrieval of numeric information, as this is often the information in greatest need of repackaging. The next will focus on the recovery of textual information, and the third will focus on the recovery of other types of data for analytical purposes, e.g. shipping networks exposed by package shipment tracking software.
Before proceeding, I would like to comment that I consider such technologies to be for private use, i.e. because an individual feels ill served by the business models that govern the sites they use. While it is certainly possible to strip data from web sites and repackage and resell it, if the data is not public this is theft, plain and simple. My motivation for providing tools such as these is because I feel that much of the promise of the web is being absolutely strangled by business processes that are unimaginative, take no advantage of what the web has to offer, and effectively constrain the future development of web services and software. Scraping technologies such as the ones discussed here only have value because the value proposition behind so much of the web is so unbelievably shallow. If there was more effort paid to trying to understand the web consumer and their needs, there would be no value in approaches such as the one discussed here. By definition, if you've got a good model and thousands upon thousands of customers for that model, then you've got the economies of scale and your customers know it. The problem with the web today is that site visitors, in general, are not customers. They are eyeballs that are repackaged and sold to advertisers. This is a defensive mechanism for victims of that approach. It's also a tool for those trying to assemble new knowledge from bits and pieces floating around on the web, but that's an issue for the third paper.
The Program
This particular program is an example of how to repackage web data to make it more useful to you. While the program processes financial data, inspection of the source code should show how the program and the concepts it represents can be easily modified to acquire other kinds of data, such as product pricing across a wide range of vendors, or any other kind of data provided in tabular form by database backed web pages. Even within individual organizations, poor management and intergroup rivalries can lead to the web being used to present information while still erecting barriers, such that what you need may be there, but you end up working way to hard to get it, or simply not being able to use it in the form you want.
Hence, ripping data on the World Wide Web. In essence, if you confront a problem where data you want is being taken from a database you can't get at and used to make web pages that don't exactly satisfy your needs, you can reverse the process to reconstruct the database on your side of the fence. Accessing financial data on the majority of the sites providing such information is on a company by company basis, i.e. you request the financials on IBM, or MSFT, or XOM, and up comes the page. While this data is certainly useful when examining the performance of a particular company, it's of little use when trying to decide what company you wish to invest in. At times like that you want to see the financials for a wide range of companies, and be able to compare them in a meaningful form. You might even want to use other tools at your disposal to do so, like spreadsheets. You might like to be able to hold onto this data for a while, making it more permanent than the ephemeral web pages you are given. Unfortunately, this isn't something you're getting, because it conflicts with the business model of the site, and you're not their customer. The advertisers are their customers. You're just some eyeballs they're selling.
Architecture
The fundamental architecture of the system can be broken down into four distinct operational areas
- Dispatching the scraping operations in the background
- Retrieving and Parsing data from remote web servers
- Updating a local database with the retrieved data
- Management of the User Interface
The key element is the retrieval and parsing of web page data, and divides naturally into the two indicated tasks
- Determining the URL that produces the needed data and fetching the page
- Stripping the data of interest from the returned page
The following sections will deal with the individual architectural components, explaining how each works and then how they relate to each other in the composite system.
Performing Time Consuming Tasks in the Background
When a computer is expected to perform a long task, its not considered polite to 'lock it up', i.e. make it difficult or impossible for the user to interact with it until the task completes. There are exceptions to this, however in general its a good policy and tends to lead to less annoyed users. Many developers, when confronting this need turn to threads, but often threads introduce far more problems than they solve. If you've ever tracked down race conditions or deadlocks in threads, I'm sure you know exactly what I mean.
The C# Form class provides an easy way to implement such behavior without resorting to threads. You can implement an Idle message handler, which is called when your program is getting cycles, and the application hasn't anything better to do. Use of the Idle message requires that you factor your task appropriately, i.e. you wouldn't want to dispatch your idle method and then take an hour to process everything. Instead, you make this function responsible for handling one step at a time, and implement logic that guides it in moving from step to step, or more appropriately, from state to state.
One issue to be alert to in this approach is the internal logic used by the Form class to invoke Idle operations. In general, the idle method is only invoked if the cursor is contained within the interface, and is over an active field, i.e. one that has data changed by the idle routine. This is meant to cut down on extraneous calls to the idle function. To get the idle function to run more regularly, simply call Invalidate at the end of the processing cycle, which will trigger an update and cause the idle function to run once more, after everything settles down again. Note that the call to Invalidate does not request that the children be invalidated (the false parameter) which prevents the form from flickering madly on the display.
The idle method is defined like most other message handlers, accepting a sender object and event arguments as parameters. In this particular application we ignore both, but you could theoretically use these in multiple form applications to have a common idle method deal with the needs of more than one form. The idle method for the WebScraper has been implemented in doOperatingCycle, and is responsible for starting statement processing, handling retrieval of individual records, and cleaning up and deciding what to do next.
Inspection of the code shows that the first test determines if there is anything at all to do, i.e. if the WebScraper is stopped or paused, it simply returns without comment. For those with a sense of humor, it's conditions like this where you can have the system maintain some basic count and complain at the user to 'just do something, anything!' if this count exceeds a certain preset. In more practical applications, especially when security is an issue, this is an excellent means for automatically terminating unused applications that shouldn't be left open.
If the WebScraper is running, the idle handler will first update some of the forms eye candy, specifically the status message that slowly moves across the information display field on the form. This kind of display is useful in time consuming applications because it provides visual feedback on the performance characteristics of the application, i.e. your eye tells you a lot about how quickly or slowly the process is running, and how smooth it is. While the display also contains a number of numeric fields that give more precise measurements, many studies have shown that our visual cognition is vastly superior to our numerical cognition, and this is a simple means of taking advantage of those capabilities.
Inspection of the case statement that appears after the update message shows that there are three states that the idle method must successfully transit. These states handle the initiation of a specific scraping operation, the acquisition of scraping data, and the termination of the scraping operation respectively. We'll now address each of these individually.
Initiating Scraping
When initiating scraping, the first task is to reset certain display fields to a known state. While these fields may already be initialized when the application starts, the flow of control in the system does not guarantee that this remains the case, so we take the time to make sure all of the fields are initialized correctly. Once the common display elements are reinitialized we need to update the operating states that will be used by this idle dispatch method so that it 'does the right thing'.
If you drop down for a moment and look at the InStatement case, you'll see it doesn't differentiate directly between scraping operations, instead it uses information set in the StartStatement case as parameters for calls to scrapeFinancialInformation, the root of the real scraping logic. Therefore, the StartStatement case uses a nested case statement to determine which statement is currently being scraped, and initialize these variables accordingly.
One item of note is the need to deal with the fact we don't know in advance what elements the user has selected for scraping. This leads to the conditional test that wraps each of the case elements, causing the system to automatically advance to the next statement type if the user hasn't selected the current statement for scraping. This is also the reason for the duplication of m_scraperOperatingState = ScraperOperatingState.InStatement in each case handler, as the operating state can't be changed until we've found the next valid state. There are other ways to do this, but sometimes the laziest way is also the easiest to understand, and hence to maintain.
Performing Scraping
InStatement is the main workhorse of the system, and uses information set in the previous StartStatement state to properly dispatch to the scrapeFinancialInformation function, which is the root of the scraping system itself. A test to determine if the current record index exceeds the maximum record count is made initially to determine if all records have been scraped, and if they have, the system advances automatically to the EndStatement state.
Ending Scraping
The EndStatement state must do one of two things. If there are more statements that could be scraped, then it must return to the StartStatement state for the next possible statement. If there aren't any more statements to scrape, then it terminates the main state handler by advancing the global state of the WebScraper to stopped.
One special concern to note in this context is that both EndStatement and StartStatement must check to see if the scraping process needs to be stopped, as they both have the capability to advance through potential scraping targets. In the latter case, EndStatement advances because a statement has just been scraped, and in the former case StartStatement may advance because a statement is not selected for scraping. In either case, they may end up advancing past the end of potential scraping candidates and would therefore need to terminate the scraping process.
Retrieving and Parsing Data from Remote Web Servers
As I said earlier, this element naturally divides into two clear parts, the identification and retrieval of web page data, and the parsing of the retrieved data. In this program, the implementation associates the two halves of each operation together, however in a more advanced system this knowledge could be represented explicitly in the architecture. This would add considerable flexibility to the system, but would also introduce additional complexity beyond the scope of this paper.
In this program there are four basic retrieval tasks for balance sheet, cashflow, income, and equity information respectively. The first three records all come from a common source and use the ItemParseDirective structure to define items of interest. The last element, equity information, is retrieved from an alternate source using a different parsing mechanism. While some effort could be expended to unify these two parsing mechanisms, one central characteristic of any tool like this is the fact that it must allow for the easy development and alteration of parsing methodologies. This is not only because the web sites providing the data in the parsed format are under no obligation to provide the data in a consistent format, they may indeed perceive it to be in their benefit to change the format regularly. For this reason, I've left two distinct parsing mechanisms in place, so that you can see how to mix and match a series of unique parsing approaches into a common architecture.
In essence, the enumerator FinancialStatements is the key to pairing these two related tasks. In several methods, most notably processRecord, you can see how this is used to match the recovery of web data with the appropriate parsing logic. The method takes a FinancialStatements value as a parameter and uses a set of back to back switch statements to first call the correct retrieval method and then to call the correct parsing method. It is possible that some sites might have an apparently non-deterministic way of selecting a returned data format, and in such cases you'd end up adding logic in the middle to determine the format of the data returned and then call the parser. On the other hand, there's no need to go to that level of complexity unless you absolutely have to.
High Level Organization of the Scraping Process
The scrapeFinancialInformation method provides a single dispatch location for all scraping operations, accepting parameters that provide a browser instance, the class of information to be scraped, and the index of the record in that class that is to be scraped. The browser object is used to handle the tasks involved in obtaining the raw page and stripping out it's textual content and the other two parameters will control the behavior of the lower level scraping functions as they retrieve, parse, and store the scraped data.
The scrapeFinancialInformation method also handles basic update of the display, using the updateProgressMonitorFields method. This routine will ensure that all of the runtime status display fields are updated so that the user can monitor the process of the scraper.
The scrapeFinancialInformation method calls processRecord to handle the actual retrieval and processing of information from the target websites. This could actually be rolled into the scrapeFinancialInformation method, but for the purposes of this article has been left separate, to provide a break between the high level dispatch driven by the idle method and the low level operations of the scraping process.
Retrieving Data from Remote Web Servers
There is a method provided for each class of data we wish to retrieve that allows us to know where to retrieve it from. Since any attempt at retrieval will produce some kind of response from the server, if nothing else than a 401 error, we pair the attempt to retrieve the data with a simple test to determine if the data we want wasn't successfully retrieved. Note that distinction carefully - I'm not saying we have a test to know we got what we want, we instead have a test to know we didn't get what we want. The only true way to know you got what you want is to inspect the result in detail, there is nothing that says that the server couldn't have simply dropped dead halfway through the process of returning legitimate data to you. On the other hand, there is probably a pretty easily established criteria that tells you that you absolutely didn't get what you want. In this specific case if you examine the condition for entering the second switch statement in processRecord you can see it's wrapped in a conditional that tests to see if the size of the returned page is at least 1500 bytes. If not, it's impossible for this page to contain enough data to satisfy us, and we can safely assume it doesn't contain what we want. On the other hand, if it does contain more than 1500 bytes, that doesn't necessarily mean that it's got all the data we want, it only means its worth spending further effort to see if the data we want is there.
Therefore, our retrieval task is one of generating the URL from which we wish to retrieve data, the act of actually retrieving the data, and a simple test to determine if we most certainly failed in the attempt. In terms of generating the URL itself, this calls for some research on the developers part. In general, even when some effort has been made to obfuscate things, there is a one to one pairing between some key identification criteria and parameters coupled to a URL that return the correct data. In other words, in order to retrieve the data you want, you need to tell the server what it is you want, and the result of all that usually turns into a parameterized URL that nets you the data of interest. In this particular program that is exactly the case.
If you examine the parameters passed to processRecord, you will see that one of them is a string,sym, which contains a ticker symbol identifying the company for which we are attempting to retrieve financial information. The first switch statement selects one of four URL generators based on the FinancialStatements enumerator value passed to processRecord. The sym value is passed to the selected URL generator so that it may be used to parameterize the generated URL.
Generating a Parameterized URL
Examining one of the URL generators, balanceSheetURL, shows how a client side system can generate specific URLS for interrogating a remote web server for data of interest. If you examine the function you will see it's quite simple. Inspection of the operation of the target site during manual browsing provided the data necessary to construct this function. To inspect a site to determine this information, you go to it's query page where it allows you to provide your selection criteria, and then you inspect the URLs of the pages you get. Using only a few keys you can often determine exactly how your query data is combined with static site data to produce a new page address, which you are then automatically redirected to. To verify that you have correctly determined how this process works, you then fire up your browser and manually create a page address using a new query value you know to be legal. In this case, if you've used MSFT and SUNW as your test queries, and you think you know how things are going, then try manually creating the page address to get you data on IBM. If that works, you've found the logic for constructing any URL.
Some sites will go to some trouble to prevent this, using one of two potential approaches. The first approach is some kind of obfuscation of the query parameter. For example, you may enter a ticker symbol, and they may use the record index of that ticker symbol to generate the relevant page address. There are a number of ways of dealing with this. For the more analytically minded, you can attempt to determine their indexing scheme, i.e. you may be able to determine that their indices are based on the sorted order of all items. If you don't wish to go to that effort, or they've managed to obfuscate it successfully, you can always use a brute force approach, feeding in the set of all legal query symbols and then recovering and saving the returned URLS. You'd then use table driven logic to reconstruct the proper URLS from the source queries. You'd of course want to analyze that set of URLS and keep only the differentiating information, there's no need to save anything beyond what makes them distinct from each other.
The second approach some site may use is the generation of pages at fixed addresses. While there are more graceful solutions to this problem, you can elect here to simply exploit the nature of the web against them. If you examine the explorerRead function, you will see it performs a very simpleminded retrieval of data from the computed URL address. You could modify this function, and the URL address generator to simply generate a response as if a user had manually filled out the query page, and then recover the returned page, following any embedded auto forwarding link it may contain. This approach will in fact work on just about anything, we don't use it here because it's the most inefficient way of doing things. However, in any situation you confront where you can't establish the destination URL, then it's always safe to simply automate the query response itself and let the host site do all the work.
Retrieving the Raw Page Data
In many cases, retrieved pages come with a lot of eye candy of zero interest to you, and even potentially of less than zero interest, for example the infamous 1 pixel images used to monitor Internet users. Anytime you use Internet Explorer as an active control with a visible display, the default behavior of the system is to go get everything on the page, which probably doesn't mesh with your needs. Often, all you need access to is the basic textual information on the page, you don't need to retrieve any of the embedded images, run the javascript mouseovers, and so on. Examining the explorerRead function, you will see it's a pretty simpleminded affair in this implementation. It uses the Navigate function of the InternetExplorer object passed to it to cause the InternetExplorer object to download the contents of the URL passed as a parameter, and if all goes well, it returns the body of the downloaded HTML document.
As the Web is not always reliable, the attempt to read the page is wrapped to catch exceptions. The more obvious use of this is to catch exceptions thrown by the InternetExplorer object itself, i.e. if you're on a dialup and pulling down 10K records, your dialup may suddenly disappear underneath you, and the next attempt to download a page is going to produce a certain amount of complaining. The less obvious, but more common issue deals with sites that sometimes don't return your page request, either because they lost it, the response never made it to you, or the site just disappeared off the web. In all these cases we are using a 5 second timer to automatically trigger an exception (see timer1_Tick) if the page is not received and the timer reset before this period expires. This type of logic is commonly known as a watchdog timer and is used to prevent the system from waiting for something that isn't ever going to happen.
Given this logic, the attempt to retrieve a page, given an InternetExplorer object and a URL, will produce either a string giving the body of the retrieved page, or null indicating no page data was retrieved. In more problematic cases such as those mentioned above, this page retrieval logic can be augmented to deal with issues like redirection, or even recovery of images and reprocessing them to convert an image of textual information to the textual information itself.
Parsing Data from Remote Web Servers
Once you've retrieved a page of data from a remote server that may contain data of interest to you, the next step is to rip the page apart and try and get at the data of interest. The fact that you have access to the Document Object Model (DOM) makes your life considerably simpler, as you don't need to make sense of a raw HTML document, you just need to know how to pick out the bits that you want from the readable text on the page.
In general, you can break your parsing needs down into two major categories. The first are those that you can generalize, and that you benefit by generalizing. In the real world, these two issues tend to travel together, in that it's often tough and certainly pointless to try and generalize with only a single case. In this specific application we have three classes of information (balance sheet, cash flow, income) that come from a common source and have a common overall format. Hence, we have enough data to generalize, and by generalizing, we make our lives easier. Later on we will examine the parsing of equity information, which comes from a different source, and there is no such benefit in generalizing, at least for the purposes of this little application.
If you examine the processBalanceSheetRecord method, you'll see that the bulk of the method is not code, but the instantiation of a large number of instances of ItemParseDirective. If you then scan processCashFlowRecord and processIncomeRecord you can see that the primary differentiation between these functions is in fact the parameters fed to the functions they call and the large number of ItemParseDirectives they define.
The ItemParseDirective instances are used to control the behavior of the processGenericRecord method. They effectively customize it on each call to indicate where it should search, and for what. Delving into the ItemParseDirective, there are three essential elements, the key, the pattern, and the datatype. The key is what we use to identify the data we are retrieving and give it a unique identity, the pattern indicates how to find it, and the datatype indicates how to convert it to internal form. The entire effort is aided by organizing the ItemParseDirectives in the order in which items are found in the page body, which allows us to use patterns that may possibly repeat through the page.
One other item of note is the decision as to exactly what data you wish to retrieve. If you inspect the WebScraper, you will notice that it only collects data elements that it cannot calculate, i.e. values returned on the scraped page that are computed from other elements on the page are not parsed out of the returned data. Arguments can be made for or against this practice. In some cases, pages will usually but not always provide numbers that are calculations, and you may then calculate values that would not agree with the source page. In other cases, the need for having extremely reliable data could lead to a decision to pull down all calculated values and then check each retrieved value against an internal computation of that value.
Generic Matching
The processGenericRecord is called with two parameters, the raw body text of the HTML document, and the set of ItemParseDirectives to use in extracting data from the body. Given the nature of things, we know that all of the HTML markup information has already been stripped from the body, therefore we are only dealing with the actual informational text of the web page. Various initialization tasks are performed such as getting the line break style we want and the variables we need initialized, and then the method begins applying the ItemParseDirectives in the order in which they were given.
For each directive processed, it numbers them as they are processed, and then pulls out the key and pattern from the ItemParseDirective. This information is passed to the grabData method, along with a reference to the current search position, which is automatically advanced by the grabData method as information is pulled out of the raw text. The reason for doing this is to simplify the pattern matching process by allowing for duplicate patterns to be distinguished by context. Consider if you were retrieving a page that contained records for Part #, various miscellaneous other stuff, and then some other Part# that you also needed to track. If you had no contextual reference, then the pattern for the second part # would have to include additional distinguishing information, as otherwise the search, beginning at the beginning of the text each time, would return the first part # twice. If instead, you do as is done here and maintain an offset showing what text has already been recognized, you know that while the Part# patterns are identical, the positional context you are maintaining will make the right thing happen each time.
If the grabData method succeeds, it returns a non-null result, which must then be converted to usable internal form. This is done by very specialized parsing elements for numerical and date information. These primitive item parsers deal with two critical factors, the conversion of data from some outside format, and handling situations where there may be more than one discrete item of data.
Custom Matching
The processEquityRecord was written in a different form than the other three record handlers. In fact, the other three handlers originally looked something like this method, and were then rewritten into generic form, but the equity record hasn't been improved on, so I could leave a roadmap of how to go about this. When you're actually decomposing a page and extracting the data from it, this is an exploratory process with many fits and starts. It's very unlikely that the page designer has gone out of their way to be helpful to you, the best you can hope for is that they haven't gone out of their way to make your life difficult.
The processEquityRecord method uses the grabData method to handle actual recognition and extraction of patterns, it differs only in how these patterns are organized. If you were to try to jump immediately to parsing a new page using the generalized architecture, you're not likely to get it right the first time, and the very generality of the solution is likely to interfere with your attempts to track down the problems. The most basic benefit provided by a custom parsing method then, is the fact that the logic is 'unrolled', and it is a lot easier to see what's going on. You're not trying to track loop indices into tables of patterns, you're just watching the program move forward through explicit instructions.
If you look closely, you'll even see operations that make sense only in the context of the generalized parser being performed here, such as the constant assignment to vars[]. Yes, the elemental reason is that the code that you're seeing here was lifted from somewhere else and that just came along for the ride. However, there's no real harm in leaving it there, and when considering a rewrite to get this in generalized form, it will disappear quietly. And right before it disappears it may perform one last useful function, making us go 'oh yeah, need a unique name for each of these data variables'.
In this recognizer, you'll see there's a lot more tolerance for missing data. Items are processed one at a time, and if it turns out one is missing, the code simply provides a default value. Once all of the items have been gathered together, then the code converts the easiest ones straight across to internal form via calls on the FinancialValue formatter. Finally, the system deals with any reported stock splits, which requires a certain amount of additional effort. In any conversion of this parser to more general form, this logic would have to be pulled out and implemented in some supporting method, and the general parser would have to be modified so that the method was called when appropriate.
Finally, there's a loop that updates a number of records in the database with this information. In this particular case this is done because we only really have one sample of data, but one of the items in that sample is a date that's important (the last time the stock split) in some of our calculations. We're not doing the greatest job here, but it works well enough for the calculations we need, and it ensures that our fundamental database architecture has a certain level of consistency.
Low Level Pattern Matching
Consider that you have some page that contains data of interest to you. In many cases, data is organized by providing some kind of label, and then one or more data values, all on a single line. Your goal in automating the recovery of this data is to find the label that indicates the start of the data and then read the one or more values of interest that follow this label. If we examine a single pattern used in the processBalanceSheetRecord, we can see the pattern "\s*Cash And Cash Equivalents(?<CASH>.+)" is used to pick out this line of information from the web page. Using documentation on regular expressions, we can decompose this pattern to see that it
- Recognizes and drops one or more white space characters
- Matches exactly the text "Cash And Cash Equivalents"
- Acquires the remainder of the line and places it in the named variable CASH
The exact syntax for regular expressions in .NET is available in 'Regular Expressions Language Elements' on the MSDN site. In general, the regular expression support in .NET is well worth familiarizing yourself with, you will find a number of tasks that would otherwise require implementation of fairly complex algorithms can be vastly simplified through the use of regular expressions.
Parsing Very Low Level Data
In this program there are two low level parsers for dates and numbers respectively. The low level parsers are responsible for breaking down a source data string into a fixed number of items of data, and for converting each of the items to internal form. The number of items expected is given in the call to the parsing function and comes from either the ItemParseDirective for a generic parser, or directly from a coded constant in the case of custom parsers.
The structure of the iteration logic allows for less than the expected number of items to be found in the source string, but it does assume that the missing values are always at the end of the sequence, not at the beginning. This is a reasonable assumption when dealing with tabular data, as there are usually markers present in the tables to indicate missing data in the beginning.
Parsing Dates
One nice thing about .NET is it's native support for textual data as parameters for many constructors, such as those for DateTime. Since it was discovered that the dates in the source pages matched a format recognized by the DateTime constructor, the bulk of the parsing job can be handed off to the DateTime constructor. In this situation we need only come up with a pattern that defines what a date looks like, and then use the regular expression system to match this pattern against the one or more dates in the source string. Once the match is complete, we simply iterate through the results and pass each matched substring to the DateTime constructor to convert the values to internal form.
Parsing Numbers
Parsing numbers is a more complex exercise for several reasons. Foremost, the fundamental numeric parsing routine provides support for more than one recognition task, e.g. it handles both straight numbers and financial numbers. This requires that it recognize the potential existence of currency markers (dollar signs in our case) and multiple means of representing negative values (leading - or enclosed in parentheses). Furthermore, it must deal with a special string 'N/A', which must be recognized and treated as analogous to 0. Lastly, it must also deal with the presence of commas. If you inspect the code, you will notice it does not deal with floating point numbers, in fact it will throw an assertion in debug mode if it encounters a decimal point.
Although the routine is much larger than the date parser because it cannot use the regular expression logic, it's overall function is the same. It takes a source string and a maximum item count, iterates through the string to break it down into individual items and converts each of these items to internal form. It then returns an array of doubles to the caller representing the values discovered in the string.
Updating the Local Database
There are two routines used to write data to the local database named writeGenericRecord and writeCustomEquityRecord respectively. The first handles writing any of the three generically processed records, balance sheet, cash flow, and income. The last handles writing the equity data. This reflects the decisions made in implementing the parsing operations, where we're using a general purpose method for the first three records and a custom method for the fourth record.
In this program, both routines use the SQL INSERT statement to update the database, without checking for the existence of a previous record. As the SQL standard requires the use of an UPDATE statement to change information in a table when the key already exists, this is a lazy and somewhat inefficient means of updating the database, but it does ensure we don't end up with duplicate records. If you were to run the scraper and abort it half way through the process, on restarting it would simply silently ignore all of the attempts to update existing records. Not necessarily the greatest SQL programming, however the time wasted is a mere fraction of the time spent in acquiring the pages in the first place. As there's no way to determine if a record would be duplicated without recovering the page in the first place, there's little point in optimizing this. You can see how we deal with this in the error handler for each of the database update routines, by specifically testing for this error code (-2147467259) and ignoring the error, if present.
All of these routines use very simple SQL based interfaces to update the database. While there are a wide range of mechanisms available from Microsoft for supporting database integration, many of the more sophisticated techniques are implemented in more than one package in more than one way. Microsoft has released and provides some level of support for Active Data Objects (ADO), Remote Data Objects (RDO), ODBC, OleDB, and a horde of other acronymed technologies. Figuring out which one is the technology du jour is difficult, and the only given over time seems to be that it's always a changing landscape. For this reason, where transactional efficiency isn't of paramount concern, it's often easier to simply pick the technology that offers the quickest access to straight SQL and use that to communicate with the database. This allows for a certain amount of consistency, as Microsoft may change the interface parameters, but they can't change the SQL standard quite so easily.
We use the OleDBConnection class to support connection to the database in this application. This allows us to bypass setup operations associated with ODBC, and provides a pretty straightforward mechanism for issuing direct SQL commands to the database. We do use the parameterized SQL support provided by this class, as it's both easy to use, and easily changed when Microsoft elects to modify or break it.
One other general item of note in our use of the database is the nature of our record keys. We pair two items together in many tables to form a key, the ticker symbol for a particular company and the date for the information recorded. This is a far more acceptable way of keying data uniquely in the database in situations where we know the union of these two keys will produce a unique key.
For those that don't wish to use a database, it's fairly easy to change the database record update functions to emit the data in some other format, for example as tab or comma delimited files for import into excel. If you want to import the data into custom systems which present some type of COM based import interface, this can also be done by modifying the export routines.
Custom Database Updates
Examining <A href="#writeCustomEquityRecord">writeCustomEquityRecord</A> first, as it's the most straightforward, there are three basic operational elements. The first is the definition of an SQL insert statement, the second is the population of the parameters associated with the statement, and the final element is the execution of the SQL command. This SQL insert statement uses parameterized expressions, which are easy to implement and maintain, at a slight computational cost for parsing the SQL.
You can also see where we catch any possible error returned from the database. As these are relatively infrequent, we simply present the error in a dialog box and give the user the option of either ignoring the error or terminating the application. One problem with our architecture here is that we don't have any means for reporting this failure on up the line. This is an exercise left for the interested reader.
Generic Database Updates
The writeGenericRecord method provides a generalized mechanism for database updates that works in conjunction with the generic parsing mechanism and uses the key information embedded in the ItemParseDirectives to generate the SQL code necessary to update the database. It takes three parameters, a table to be updated, the unique ticker symbol of the company the record is being written for, and a Hashtable of key/value pairs containing the information to be written to the database.
The writeGenericRecord method generates the SQL INSERT statement by first generating the leading element, "INSERT INTO thetable", and then iterating over the contents of the Hashtable to generate the key and value components for the SQL statement. Note that in this process it does not insert the actual value into the SQL statement for each key, instead it inserts a unique parameter based on the name of the component as defined in the ItemParseRecord. This means that we can generate the SQL statement once, and then simply change the parameter values for each of the columns of information we will be processing.
Once the SQL string has been generated, the system then iterates over the collected columns of information, setting the parameter values appropriately for each column and then executing the SQL update command.
Managing the User Interface
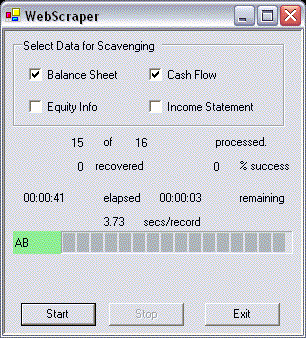
The user interface for the WebScraper is simple, consisting of a set of checkboxes to select what data will be scraped, a few buttons to start, stop, and pause operations, and a collection of controls used to display information on the scraping process as it proceeds. In implementing the interface, a few patterns of common utility were used that are worth calling out.
There's no reason to have the user press the start button when nothing is selected for retrieval, yet there's also no real reason to introduce excessive amounts of overhead to track what the user has selected for retrieval. On commencing the scraping process, it's easy for the runtime to check the state of the various checkboxes directly, so there's certainly no need to maintain separate state selection variables for them. Therefore, we use a common function (GetFinancialStatement_CheckedChanged) called whenever any checkbox has its state changed to keep track of the number of selected checkboxes and update the enable state of the Start button appropriately.
When the user has selected the data of interest and initiated the scraping operation by pressing the start button, it's useful to give them feedback as the operation proceeds. Even on wideband connections, this process can take over an hour, and timeframes like that mean you shouldn't leave users wondering if your system is really working or has silently dropped dead. Much of the user interface for the WebScraper is dedicated to that need, letting the user see what is occurring, how long it's taking, and how long till all is complete.
The first row of output information lets the user know roughly where the program is in the set of records it is processing. The system updates the current record number on each retrieval operation. The second line of information lets the user know how many records have been successfully recovered, which may be less than the number of records in the search, either because information is not provided by the scraped site, or because there were communication problems. It also gives a calculation of the overall success of the download, as a percentage of records successfully obtained in the number of scraping attempts. It then shows the amount of time currently taken by the scraping operation and an estimate of the amount of time remaining. Underneath this it shows the amount of time taken to retrieve the last record.
The last line shows the ticker symbol for the current scraped record, and a progress bar which provides another visual indication of how far along the scraping information is. To provide some dynamic detail on successes and failures, the background of the ticker symbol display is set to green if the record is successfully obtained, or red if it could not be obtained.
The forceFieldUpdate routine is provided to handle the need to dynamically update the display even though the scraper is not allowing the main message pump to run. This routine accepts a control as a parameter, and invalidates the display for the control and then forces it to update. If this were not done, then no control would update until the last record were processed and the message pump began to run again, which would not be the desired result.
Appendices
Why we randomize the keys
If you examine the loadTickerSymbols and randomizeList methods, you will see that the nicely sorted list of equities in tickers.txt is randomly re-ordered before the scraping operation begins. This is done to avoid giving too clear a signature to the destination site that it is in fact being scraped. This is more an indicator of countermeasures that can be taken to deal with sites that are reluctant to provide data in the form you wish than it is actually useful, as the test for sequentially appearing ticker symbols would most likely be one of a number of tests.
Measures and countermeasures to implement and defeat scanners is a broad area, and there is much work taking place at present. In general, scraping is a technique of particular value when dealing with simpleminded sites that have poor business models and a shallow understanding of their customers needs. Most of these sites are based on the idea that they can sell 'impressions' and are structured in such a way to generate as many page downloads as possible, with each page packed full of advertising and often trailing a horde of popover and popunder windows. In such an environment for the personal web viewer, scraping is a defensive mechanism, sparing them from the necessary from dealing with an information channel which contains far more noise than useful data.
Countermeasures come in two basic flavors, those designed to solve the 'problem' from the perspective of the site business and it's visitors, and those designed to interfere with the scraping process. In the former case, the site may elect to completely change the way that they package data, and to do so using a new vehicle that removes the users motivation to scrape the site for data. For instance, if sites allowed the download of bulk financial data in conjunction with running flash animations, they have both an excellent vehicle for dynamic advertising and a willing participant on the far end. The process is in fact more efficient than the more common page at a time approach, and produces very high quality eyeballs to watch the presentation as the data is delivered, or at least for some of that time period. They may also elect to change the financial basis by which they communicate with their page viewers, for example shifting over to a paid subscription model. While this would not necessarily invalidate scraping, it does change the functional consumer of the sites services from the advertiser to the subscriber, which might cause beneficial changes in thinking, i.e. not having site designs that require the user to request new pages for each data granule they seek.
Other purely technical countermeasures designed to enforce the status quo work about as well as comparable measures in the CD business. They can certainly use Java applets to control data visualization, with the implicit threat of DMCA prosecution for reverse engineering the process, however it is likely that papers exactly like this one will still appear, albeit with one change - they will be anonymous. They can image the data and ship pictures down the line instead of text, however this simply increases the computational load and reduces the efficiency of the communications channel, as you can see by doing a whois lookup on register.com. Furthermore, OCR recognition of clean digitally generated text is child's play.
References in C#
If you look at the Solution Explorer, the entry immediately under WebScraper is named 'References'. The references folder is used to map dependencies to external components used by solution, but not under it's control. A lofty goal to be sure, and in some ways a very good concept. Unfortunately the execution of the ideal is flawed and the documentation leaves much to be desired. Common problems in moving source projects from one machine to another are that the systems normal behavior is to bind absolute paths to each element, which means if you develop on a machine with the Windows OS installed at C:\Windows and your coworker develops on a machine with Windows installed at C:\WinXP, then it's highly likely you can't just chuck the development folder back and forth without breaking things. If you're using source control, you still are confronted by the fact that the solution file on one machine doesn't behave properly on the other machine.
The first and most basic solution is to access the properties of your solution and make sure both OS directories are added to the references path. Sometimes this helps, and sometimes it doesn't, but it's easy to do and at least gets rid of some problems. If you find yourself using a common set of dlls, there is also the option to copy them into a local directory and make that part of your project. This certainly works, but it does mean you have to stay on top of all the upgrades and changes that may affect the DLL.
In general, using .NET assemblies seems more reliable than using .DLL/COM assemblies. I develop on a mixture of Win2K and XP systems, and I've found that more often than not, the XP installations are not all that they could be, for example they often seem to mis-install themselves and loose access to critical tools such as tlbimp.exe, which makes it impossible to use the IDE to add new DLLS as references to your project. In general, it's handy to add a path to the directory containing tlbimp.exe (C:\Program Files\Microsoft Visual Studio .NET\FrameworkSDK\Bin on my system) to your global Path variable to compensate for this. On the other hand, Visual Studio doesn't always seem to pay attention to this system pathing when looking for such tools, so this is only a partial solution as well.
It's a pity that the factoring of functional capabilities is so poor in Visual Studio .NET, but that's the way it is. In another paper I could go into this in considerably more detail, but for now this is just a nuisance in the way of our forward progress. For this specific release, I've simply elected to put the extracted interfaces, packaged as dlls in a local folder called dllimports. This bypasses most concerns, at the expense of potentially mismatching the interface DLL with whatever version of the underlying component is actually installed on your system.
If you attempt to rebuild the application and are informed that things like mshtml or shdocvw are missing, it means that you too have been munched by sloppy work by your tools vendor. It really is hard to believe that with the monstrosity called the registry forced down our throats that Microsoft can't even use it to address these problems. If you examine the contents of the References folder and see little red x's next to some files, this means you'll need to fix up these links before proceeding. Before proceeding with either of the workarounds given below, delete everything with a red X next to it in the References folder.
To do this in the easiest fashion possible, right click on the References folder in your solution, and pick Add Reference... from the menu that appears. Then click on the COM tab in the dialog box that appears, press the browse button, and select both DLLs present in the dllimports directory within the WebScraper solution directory. This should get everything synchronized correctly.
If the first approach doesn't work or leads to some other kind of problem, read this technical note from Microsoft - Walkthrough: Accessing the DHTML DOM from C#. Once you've finished making sure your toolbox contains Internet Explorer (it will appear under the 'General' tab), create a new empty form in the Form Editor, and drag the Internet Explorer component onto the form. This should get everything aligned to your needs and enable you to build the entire project.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




