Introduction
The Adaline Word Network is an experimental network of my own. It came about when I was wondering if a network could be made to understand words. Not as in being able to give a dictionary definition, well not yet anyway, but as separate items of data. Of course, the main problem with this was that the networks all function through numbers. So I had to come up with a way of getting words to be represented by unique numbers. The idea I came up with was that each character of the word is represented on the computer as an ASCII value, so all I had to do was use the value for each letter. But then, there was the problem that certain words would amount to the same value, which required a way of changing the letter value enough so that no two words could arrive at the same value. The way I did this was to multiply each letter in the word by the value of its position in the word. So the first letter would be its character value multiplied by one and so on. I still think it's possible that two words will come up with the same value, but it gives me a starting point to try some experiments and see where it ends up.
The Adaline Word Network
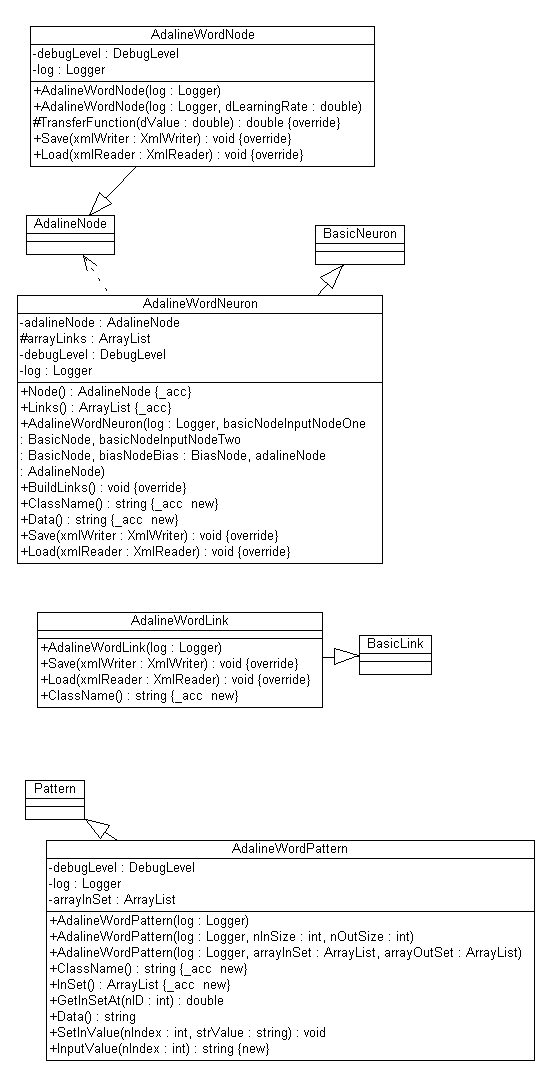
The Adaline Word Node Class
The AdalineWordNode class inherits from the AdalineNode class and overrides the Transfer function changing the test value to test if the total value generated by the Run function is less than 0.5. Other than this (and the saving and loading code), the AdalineWordNode uses the code from the AdalineNode class.
if( dValue < 0.5 )
return -1.0;
return 1.0;
The Adaline Word Link Class
The AdalineWordLink class inherits from the AdalineLink class and apart from the saving and loading code, the class makes one change and that is to set the starting weight for the link to a random value between 0 and 1 instead of between -1 and 1. ( See Fun And Games section for an explanation )
arrayLinkValues[ Values.Weight ] = Values.Random( 0, 1 );
The Adaline Word Neuron Class
The AdalineWordNeuron class inherits directly from the BasicNeuron class and the only changes are to allow it to use the AdalineWordLink and AdalineWordNode classes.
The Adaline Pattern Class
The AdalinePattern class inherits directly from the Pattern class and slightly changes the way in which the class works. This is necessary as the pattern array now holds words and not values. These words need to be converted to values and this is done through the GetInSetAt function which contains the code:
double dValue = 0;
string strTemp = arrayInSet[ nID ].ToString();
for( int i=0; i<strTemp.Length; i++ )
{
dValue += strTemp[ i ] * ( i+1 );
}
dValue = dValue / 10000;
which gives me a double value for the word which will be mostly unique.
The OnDoAdaline2 Function
As they both use the same algorithm, the OnDoAdaline2 function is very similar to the function that creates the first Adaline network.
FileInfo info = new FileInfo( "Neural Network Tester.xml" );
if( info.Exists == true )
{
info.Delete();
}
log = new Logger( "Neural Network Tester.xml", "NeuralNetworkTester", true );
ArrayList patterns = LoadAdaline2TrainingFile();
AdalineWordNeuron neuron = new AdalineWordNeuron( log, new BasicNode( log ),
new BasicNode( log ), new BiasNode( log ),
new AdalineWordNode( log, dLearningRateOfAdalineTwo ) );
int nIteration = 0;
int nGood = 0;
while( nGood < nNumberOfItemsInAdalineWordFile )
{
nGood = 0;
for( int i=0; i<nNumberOfItemsInAdalineWordFile; i++ )
{
netWorkText.AppendText( "Setting the Node Data to, Pattern "
+ i.ToString() + " word 1 = "
+ ( ( AdalineWordPattern )patterns[ i ] ).InputValue( 0 ) +
" value = "
+ ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ).ToString()
+ " word 2 = "
+ ( ( AdalineWordPattern )patterns[ i ] ).InputValue( 1 )
+ " value = "
+ ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ).ToString()
+ " output value = "
+ ( ( AdalineWordPattern )patterns[ i ] ).OutSet[ 0 ].ToString()
+ "\n" );
neuron.InputNodeOne.SetValue( neuron.Node.Values.NodeValue,
( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ) );
neuron.InputNodeTwo.SetValue( neuron.Node.Values.NodeValue,
( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ) );
neuron.Node.Run( neuron.Node.Values.NodeValue );
if( ( ( Pattern )patterns[ i ] ).OutputValue( 0 )
!= neuron.Node.GetValue( neuron.Node.Values.NodeValue ) )
{
log.Log( DebugLevelSet.Errors, "Learn called at number "
+ i.ToString() + " Pattern value = "
+ ( ( Pattern )patterns[ i ] ).OutputValue( 0 ).ToString()
+ " Neuron value = "
+ neuron.Node.GetValue( neuron.Node.Values.NodeValue ), "Form1" );
netWorkText.AppendText( "Learn called at number " + i.ToString()
+ " Pattern value = "
+ ( ( Pattern )patterns[ i ] ).OutputValue( 0 ).ToString()
+ " Neuron value = "
+ neuron.Node.GetValue( neuron.Node.Values.NodeValue ) + "\n" );
neuron.Node.Learn();
break;
}
else
nGood++;
}
log.Log( DebugLevelSet.Progress, "Iteration number "
+ nIteration.ToString() + " produced " + nGood.ToString()
+ " Good values out of "
+ nNumberOfItemsInAdalineWordFile.ToString(), "Form1" );
netWorkText.AppendText( "Iteration number " + nIteration.ToString()
+ " produced " + nGood.ToString() + " Good values out of "
+ nNumberOfItemsInAdalineWordFile.ToString() + "\n" );
nIteration++;
}
for( int i=0; i<nNumberOfItemsInAdalineWordFile; i++ )
{
neuron.InputNodeOne.SetValue( neuron.Node.Values.NodeValue,
( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ) );
neuron.InputNodeTwo.SetValue( neuron.Node.Values.NodeValue,
( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ) );
neuron.Node.Run( neuron.Node.Values.NodeValue );
netWorkText.AppendText( "Pattern " + i.ToString() + " Input = ( "
+ ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 0 ]
+ "," + ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 1 ]
+ " ) Adaline = " + neuron.Node.GetValue( neuron.Node.Values.NodeValue )
+ " Actual = "
+ ( ( AdalineWordPattern )patterns[ i ] ).OutSet[ 0 ].ToString()
+ "\n" );
}
FileStream xmlstream = new FileStream( "adalinewordnetwork.xml",
FileMode.Create, FileAccess.Write, FileShare.ReadWrite, 8, true );
XmlWriter xmlWriter = new XmlTextWriter( xmlstream, System.Text.Encoding.UTF8 );
xmlWriter.WriteStartDocument();
neuron.Save( xmlWriter );
xmlWriter.WriteEndDocument();
xmlWriter.Close();
FileStream readStream = new FileStream( "adalinewordnetwork.xml",
FileMode.Open, FileAccess.Read, FileShare.ReadWrite, 8, true );
XmlReader xmlReader = new XmlTextReader( readStream );
AdalineWordNeuron neuron2 = new AdalineWordNeuron( log, new BasicNode( log ),
new BasicNode( log ), new BiasNode( log ), new AdalineWordNode( log ) );
neuron2.Load( xmlReader );
xmlReader.Close();
for( int i=0; i<nNumberOfItemsInAdalineWordFile; i++ )
{
neuron2.InputNodeOne.SetValue( neuron.Node.Values.NodeValue,
( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ) );
neuron2.InputNodeTwo.SetValue( neuron.Node.Values.NodeValue,
( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ) );
neuron2.Node.Run( neuron.Node.Values.NodeValue );
netWorkText.AppendText( "Pattern " + i.ToString() + " Input = ( "
+ ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 0 ]
+ "," + ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 1 ]
+ " ) Adaline = "
+ neuron2.Node.GetValue( neuron2.Node.Values.NodeValue )
+ " Actual = "
+ ( ( AdalineWordPattern )patterns[ i ] ).OutSet[ 0 ].ToString() + "\n" );
}
As you can see, the code here is very similar to the code that generates the first Adaline network. The code loops through the number of words in the Adaline word file and trains the network by calling Learn if the Run does not get the answer correct.
The next section runs the training variables through the code again to make sure that it has learned its task properly. The reason I did this was because, originally, the code was running till it got everything correct, but then getting everything wrong when I loaded the file and ran it again. The reason for this was to do with the loading of the file, not loading the link values correctly. Finally, the code will save the network and then load the network into a new neuron and run the data through the new neuron, outputting its responses to the display window.
Training
As mentioned before, the Adaline word relies heavily on the Adaline network, so the picture that depicts the training for the Adaline network is valid here.

This shows the way in which the Run function processes its data by going through the input data and multiplying it by the weight value.
The above shows the transition function for the Adaline network, but apart from the comparison being for less than 0.5, there is no difference.
Saving And Loading
As with the rest of the Neural Network Library, the Adaline Word Network is saved as an XML file to the disk, so that once trained, it can be used and loaded at will.
="1.0"="utf-8"
<AdalineWordNeuron>
<BasicNeuron>
<BasicNode>
<Identifier>0</Identifier>
<NodeValue>0.2175</NodeValue>
<NodeError>0</NodeError>
</BasicNode>
<BasicNode>
<Identifier>1</Identifier>
<NodeValue>0.114</NodeValue>
<NodeError>0</NodeError>
</BasicNode>
<BiasNode>
<BasicNode>
<Identifier>2</Identifier>
<NodeValue>1</NodeValue>
<NodeError>0</NodeError>
</BasicNode>
</BiasNode>
</BasicNeuron>
<AdalineWordNode>
<AdalineNode>
<BasicNode>
<Identifier>3</Identifier>
<NodeValue>-1</NodeValue>
<NodeValue>0.223333</NodeValue>
<NodeError>-2</NodeError>
</BasicNode>
</AdalineNode>
</AdalineWordNode>
<AdalineWordLink<
<BasicLink>
<Identifier>4</Identifier>
<LinkValue>-3.70488132032844</LinkValue>
<InputNodeID>0</InputNodeID>
<OutputNodeID>3</OutputNodeID>
</BasicLink>
</AdalineWordLink>
<AdalineWordLink>
<BasicLink>
<Identifier>5</Identifier>
<LinkValue>5.06800087718808</LinkValue>
<InputNodeID>1</InputNodeID>
<OutputNodeID>3</OutputNodeID>
</BasicLink>
</AdalineWordLink>
<AdalineWordLink>
<BasicLink>
<Identifier>6</Identifier>
<LinkValue>0.184749753453698</LinkValue>
<InputNodeID>2</InputNodeID>
<OutputNodeID>3</OutputNodeID>
</BasicLink>
</AdalineWordLink>
</AdalineWordNeuron>
Testing
For the purposes of testing, the Adaline word class appears as the Adaline 2 network on the menus. Its option on the train menu is the Train Adaline 2 option which will run the code listed above. When it comes to the Generate menu, there is an option to generate an Adaline working file that is saved as AdalineWordWorkingFile.wrk. This generate operation reads all the words from the adaline word file which is just a text file that contains words that the Adaline will use.
The adalinewordfile.dat file that contains the words that the Adaline sample uses to generate a file can be added to through setting the options for the Adaline 2 program in the options menu although there is nothing to prevent anyone from just opening the adalinewordfile.dat and editing it in Notepad as it is a simple text file.
The generate operation will then read all the words from the file and create the AdalineWordWorkingFile.wrk by randomly selecting two words from the file and calculating the desired output before writing all the information to the file. This information is in exactly the same format at as the adword.trn file that is used to train the Adaline word network, so if you fancy changing the training data to see what happens, simply cut and paste the contents between the files.
The quick guide is
- Menu :- Generate/Generate Adaline Two Working File :- Generates the file that is used for the Adaline Load and run menu option.
- Menu :- Run/Load And Run Adaline Two :- Loads the Adaline Word saved network from the disk and then runs it against the Adaline word working file.
- Menu :- Train/Train Adaline 2 :- Trains the network from scratch using the current adword.trn Adaline word training file and then saves it to disk.
- Menu :- Options Adaline 2 Options :- Brings up a dialog that allows you to set certain parameters for the running of the Adaline word network, as well as containing a facility to allow you to add words to the Adaline word file. (AdalineWordFile.dat)
Options
The main options that can be set for the Adaline Two network are the Number of Items in the file which is set by default at 100 and the learning rate. There is also the provision to allow testing using a bias value which is a value of 1 at the transfer function. There is also the option to add more words to the file that the Adaline two network uses.
Understanding The Output
Training
Pattern ID = 1 Input Value 0.1587 =
metal Input Value 0.0616 = red Output Value metal = -1
Pattern ID = 2 Input Value 0.2215 =
rabbit Input Value 0.114 = slow Output Value rabbit = -1
Pattern ID = 3 Input Value 0.0641 =
cat Input Value 0.1594 = steel Output Value steel = 1
Pattern ID = 4 Input Value 0.1074 =
wood Input Value 0.1611 = white Output Value white = 1
As with the previous Adaline Network, the Adaline Word Network begins by loading the Pattern array with the values to be put to the network with the only difference being that the values in this case are the words. The output shows the word that is being put to the network and its corresponding calculated value.
Iteration number 7 produced 2 Good values out of 100.
Setting the Node Data to, Pattern 0
word 1 = metal value = 0.1587 word 2 = red value = 0.0616 output value = -1
Setting the Node Data to, Pattern 1
word 1 = rabbit value = 0.2215 word 2 = slow value = 0.114 output value = -1
Setting the Node Data to, Pattern 2
word 1 = cat value = 0.0641 word 2 = steel value = 0.1594 output value = 1
Learn called at number 2 Pattern value = 1 Neuron value = -1
The above shows a portion of the training code for the Adaline Word Network as it finishes one iteration and begins another. As with the previous Adaline Network example, on discovering an error, the Learn function is called and a new iteration is started.
Iteration number 250 produced 100 Good values out of 100
Pattern 0 Input = ( metal,red ) Adaline = -1 Actual = -1
Pattern 1 Input = ( rabbit,slow ) Adaline = -1 Actual = -1
Pattern 2 Input = ( cat,steel ) Adaline = 1 Actual = 1
Pattern 3 Input = ( wood,white ) Adaline = 1 Actual = 1
Once the network has successfully trained with the examples, it then saves the network and loads it into a completely new network object and then performs a test with the same data to prove that everything has worked correctly.
Running
Generating Adaline Word File...
Please Wait Adaline File Generated
Pattern ID = 101 Input Value 0.2348 = yellow
Input Value 0.0617 = and Output Value yellow = -1
Pattern ID = 102 Input Value 0.1091 = lion
Input Value 0.1536 = black Output Value black = 1
When you load and run the Adaline Word network, the code generates a new file to ensure that the running data is different from the training data. Once the data is loaded, it then runs it against the network. Note that for the Adaline word network, the data being loaded into the pattern array is not output to the screen, so the only output is the final results of the run.
Fun And Games
Implementation of this network has not been easy from the start. The first problem being how to define a way that a word could create a number that would be unique and then how to crowbar it into the learning algorithm. The original idea behind this was to give each letter a value based on its ASCII value multiplied by its place in the word. This gives me a good starting point but I end up with a number that is something like 631, which is a bit off the testing of between -1 and 1. So the idea from there was just to stick a "0." before the number which can be made to work, sort of, apart from the minor technical detail that, if a value came out at 1100, once it had the "0." stuck in front of it, it would be considered smaller by the code than the value 0.631. This certainly wasn't the desired result and was generally too confusing.
A solution to this was to divide the resulting number by 1000 which would mean that the value 631 would resolve to 0.0631 and the value of 1100 would resolve to 0.11 which would preserve the integrity of the initial values so that the value that was originally the highest value would still be the highest value and the values would remain linearly separable which is of great importance when dealing with an Adaline network as it only works correctly on linearly separable values.
Next, seeing as the transfer values of -1 and 1 were out, as the numbers would never originally be in the negative, the transfer values were changed so that the values were between 0 and 1. The only problem with this though was trying to set the learning rate to a value sufficient to be able to distinguish between two numbers where the difference could be as low as 0.0001. This presents a problem in the training of the network although not in the running of the network. Once the network has learnt what it is supposed to do, it works fine, but it can get stuck in training on numbers that are very close together during training. The quickest solution is to generate a new training file by generating a test file and simply cutting and pasting the contents of the file into the training file (adalineword.trn). Though, I have to admit that this sometimes just takes lots of patience. Unless you are really interested in watching numbers move across the screen, the best way to test this program is use the load and run Adaline two option from the Run menu.
History
- 2nd July 2003 :- Initial release
- 7th July 2003 :- Can't remember
- 30th October 2003 :- Review and edit for CP conformance
References
- Tom Archer (2001) Inside C#, Microsoft Press
- Jeffery Richter (2002) Applied Microsoft .NET Framework Programming, Microsoft Press
- Charles Peltzold (2002) Programming Microsoft Windows With C#, Microsoft Press
- Robinson et al (2001) Professional C#, Wrox
- William R. Staneck (1997) Web Publishing Unleashed Professional Reference Edition, Sams.net
- Robert Callan, The Essence Of Neural Networks (1999) Prentice Hall
- Timothy Masters, Practical Neural Network Recipes In C++ (1993) Morgan Kaufmann (Academic Press)
- Melanie Mitchell, An Introduction To Genetic Algorithms (1999) MIT Press
- Joey Rogers, Object-Orientated Neural Networks in C++ (1997) Academic Press
- Simon Haykin, Neural Networks A Comprehensive Foundation (1999) Prentice Hall
- Bernd Oestereich (2002) Developing Software With UML Object-Orientated Analysis And Design In Practice, Addison Wesley
- R Beale & T Jackson (1990) Neural Computing An Introduction, Institute Of Physics Publishing
Thanks
Special thanks go to anyone involved in TortoiseCVS for version control.
All UML diagrams were generated using Metamill version 2.2.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




