Introduction
When you open Windows Explorer to view the files on your computer the window does not simply present a list of file names in the folder. Next to the file name there is other vital information; the file size, type and the date it was created and the contents last changed. From that you can assess at a glance the state of the list as a whole, without needing to examine the detailed properties and contents of individual files. In this article I'm going to argue that a similar idea could be usefully applied to database tables and develop a query on Sql Server metatdata and statistics views which can provide similar information to Windows Explorer. Finally I shall present a simple explorer-like table-viewer application based around an extended version of the query.
Background
Consider this: if Windows Explorer listed only the file name and no other columns how much less effective would it be to manage the computer files and systems? I'm sure that users absorb the size and date information listed with the files almost unconsciously and use it to monitor the health of their systems. An unexpected zero byte file would raise alarm bells, as could a system file with a suspiciously recent modification date. Would having access to size and date information about database tables have a similar benefit; and can we obtain that information and present it in a useful format? Probably, and yes! I'm positive about this because I have personally benefited a lot from adding this information to my open source Database explorer application DbViewSharp.
How You Might Benefit from Extra Database Table Data
The following list suggests the sort of problems in a database you might spot at a glance from the date and row count data associated with a table. I'm not necessarily suggesting that this is the best way of finding the problem if you already suspect it. It is more that by knowing what to expect to see and spotting anomalies you have a chance to detect the problem much earlier and before so much potential damage is done.
- A configuration table with an unexpected zero row count could indicate an incomplete system upgrade.
- Likewise a table with an older than expected schema-modification date.
- A table in a logical group that has an older data-update date than the others might not be updating correctly.
- A more recent than expected schema or data update date on a configuration table could point to unauthorised modifications to that table.
- Sorting by row count can reveal a table to capture debug messages mistakenly installed on production containing a huge number of rows and consuming disk space faster than expected (real-life experience).
- Unexpected zero row counts on a development database could indicate that a developer is performing unit tests, which set up and tear down data, on the wrong database (another true story).
Developing a "Table Explorer" Query
Before we start to develop the query let's firm up the analogy a little. In Windows Explorer the most common columns on view are: filename, type, size and modified date. In applying these properties to a database table I am making the following mapping:
| File Property | : | Table Property |
| File name | : | Table name |
| Type | : | Schema |
| Size | : | Row count |
| Modified date | : | Last data update date |
The name and modified date properties are reasonable direct analogies, however the other two require a little justification. For size it would be possible to discover and display the physical size of the table, but in database terms it is much more useful to know the row count. It is natural to think of a zero byte file as empty and similarly a table with no rows. The mapping of the file type to the table schema is a lot less obvious. I've selected the schema name because at least it performs some table grouping function. If the database under scrutiny only ever creates tables under dbo then ignore this column.
There are, then, four pieces of information about the database tables to discover. The table name is easy. There are many means to obtain it in SQL Server. I'm going with a query of sys.objects because there is information in that table for other columns. A further decision to be made is whether to fetch information for user tables only or include system tables. I've opted for user tables only in order to exclude all the noise tables created by replication.
The schema name can be obtained from the view sys.schemas and associated with the table name as in the following query:
select o.name as [Name], sc.name as [Type]
from sys.objects o
left join sys.schemas sc on sc.schema_id = o.schema_id
where o.type = 'U'
order by sc.name, o.name
Obtaining the row count requires either querying sys.dm_db_partition_stats or sys.partitions. Many articles on the web query sys.dm_db_partition_stats, but I've selected to use sys.partitions because it requires fewer permissions to access. You need a little care interpreting the table contents. Each table may have a number of rows associated with it in sys.partitions depending on the indexes there are attached to the table. There will always be a row (or rows) for either index_id = 0 or index_id = 1 determined by whether or not a table has a primary key. Where a table or index to a table is partitioned the total row count will be split over a number of rows in sys.partitions.
The MS documentation and almost all pages on the web that mention the row count column in this view, stress that it is approximate. However it is my assessment that the count is only inaccurate while an insert or delete command executes in a transaction. Fairly lengthy experience using DbViewSharp bears this out.
Obtaining a row count requires adding a sub-query to the main query. Note the aliasing of row count to size to emphasize the file analogy.
select o.name as [Name], sc.name as [Type], s.row_count as [Size]
from sys.objects o
left join sys.schemas sc on sc.schema_id = o.schema_id
left join (select object_id, sum(rows) as row_count from sys.partitions
where index_id < 2
group by object_id) s on o.object_id = s.object_id
where o.type = 'U'
order by sc.name, o.name
Finally to add the date on which data was last modified create a query on sys.dm_db_index_usage_stats. A table will maintain a row in this view with an index_id of 1 or 0 depending on whether or not it has a primary key. Sourcing the field like this presents a couple of problems though:
- There is a limitation on the data available for the last update date field because statistics are not preserved if SQL Server is stopped and re-started. This may be more of an issue running SQL Express on a local desktop machine than a production server, but it is certainly something to bear in mind.
- Since
sys.dm_db_index_usage_stats is a statistics table it requires your connection to possess an additional permission: that of VIEW DATABASE STATE. You can give a login this permission as follows:
grant VIEW DATABASE STATE to MyDomain\MyNTAccount
or
grant VIEW DATABASE STATE to MyLogin
Assuming you are on your development box, or have a friendly DBA, and can access the statistics tables, the basic explorer query finishes up as:
select o.name as [Name],
sc.name as [Type],
s.row_count as [Size],
u.last_user_update as [Modified]
from sys.objects o
left join sys.schemas sc on sc.schema_id = o.schema_id
left join (select object_id, sum(rows) as row_count
from sys.partitions
where index_id < 2
group by object_id) s on o.object_id = s.object_id
left join (select database_id, object_id,
max(last_user_update) as last_user_update
from sys.dm_db_index_usage_stats
where index_id < 2
group by database_id,object_id
) u on u.object_id = o.object_id and u.database_id = DB_ID()
where o.type = 'U'
order by sc.name, o.name
Producing output for example like this:
Name Type Size Modified
------------------------------------------------- --------- ------------------------
AWBuildVersion dbo 1 NULL
DatabaseLog dbo 1566 NULL
ErrorLog dbo 1 2012-09-28 08:37:04.233
Department HumanResources 16 NULL
Employee HumanResources 290 2012-09-28 08:37:51.950
EmployeeAddress HumanResources 290 NULL
EmployeeDepartmentHistory HumanResources 296 2012-09-28 08:39:23.807
EmployeePayHistory HumanResources 316 2012-09-28 08:39:48.517
JobCandidate HumanResources 13 2012-09-28 08:39:02.980
Shift HumanResources 3 NULL
Address Person 19614 NULL
AddressType Person 6 NULL
...
While the query above now will fetch all the data or the properties we identified, it is a lot better built into an application that enables searching, sorting and arranging of columns the same way that explorer does. I've developed a demonstration app from some old code that does just that. The source and installer is available in the download, but I'll present a brief run through below to whet your appetite.
Using the TableExplorer Application
When you run the TableExplorer application for the first time you need to enter database connection information.
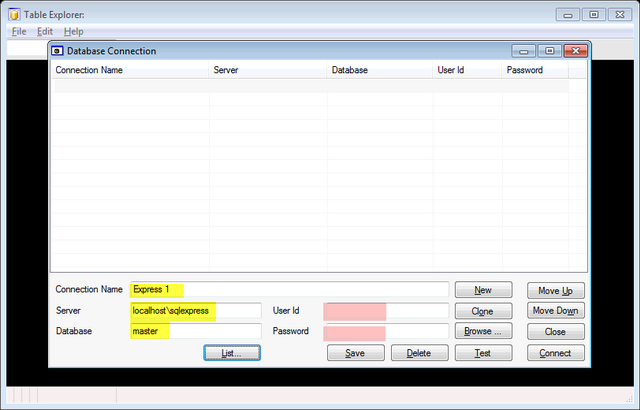
Look at the fields at the bottom of the dialog and enter a brief friendly name to identify the connection. Then enter
the server name (plus instance and port if necessary) and the database to connect to. If you are connecting with NT authorisation that's all you need otherwise enter the SQL login and password. Press [Test], then Save], then [Connect]. This should then display the tables in the database selected.

Notice that in addition to the four items discussed above there are also two columns for the date the table was created and the date it's schema was last changed. The dates seem less useful than the other columns, but may occasionally provide a clue to a problem (think about detecting an upgrade problem or an unexpected developer action on a table). The two dates reside in the sys.objects table so there is no performance cost to adding them.
There are not many menu options for this demo as most of the functionality is implemented in the grid. You can move the columns around, sort on one column in ascending or descending order or right-click on column headings to remove or add them back. Above the grid display is a search bar. This will search the table and schema columns for names containing the text you entered.
If you connect to a database for which you don't have view stats permissions you will see that the Modified column will contain the note "n.a." instead of any date information. In this case you might use the Help, E-Mail DBA menu option to create an E-mail to your DBA requesting the view state permission.
Feel free to examine the C# source, but that is not really the aim of the article. If you have trouble connecting to your database try hacking Connections.cs where the query string is constructed from an object containing the details entered on the screen. You might also be interested in the final form that the query took in order to handle the different combinations of selections. In the download I've converted it to a stored procedure (see TableExplorer.SQL). I've previously written about the techniques it uses.
Conclusion
This article has demonstrated how to start to build an application that provides explorer-like information about tables in your SQL server database. The real Windows Explorer performs many more actions on files: copying, renaming, deleting and displaying their content for modification via associated applications. A lot of this is already implemented in the open source application DbViewSharp, where the metaphor has been extended to cover views, stored procedures and other database objects. Look for
DbViewSharp in Codeplex.
References
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





