Introduction
An Associative Array is one of the most basic and useful data structures in which each value is identified by a key, usually a string. In contrast, values in a normal array are identified by indices (e.g. array[0] gives value at index 0). Associative Array maps keys to values. There is one-to-one relationship between keys and values, such that a key can only be mapped to a single value only. This concept is used by many languages: in PHP it is called Associative Array, Dictionary in Python, HashMap in Java is roughly analogous to it, etc.
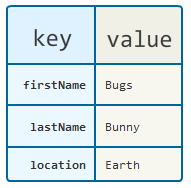
Data Storage in an Associative Array or a Dictionary
In the figure above, if you get the key ‘firstName’, it will return ‘Bugs’. Let's create the above in Python 3:
mydictionary = { 'firstName' : 'Bugs', 'lastName': 'Bunny', 'location': 'Earth'}
print(mydictionary['firstName']); The output is:
$ python3 list.py
Bugs
Note: In this article, I will use the words Associative Arrays and Dictionaries interchangeably. They both mean the same thing.
What Do Associative Arrays Have To Do With Cassandra?
Cassandra follows the same concept as Associative Maps or Dictionaries, but with a slight twist: The value in Cassandra has another embedded Associative Array with its own keys and values. Let me explain. Like an Associative Array, Cassandra has keys which point to values. These top-level keys are called ‘Row Keys‘. The value itself contains sub-keys, called ‘Column Names‘ associated to values. For example, we can store all movies by director in Cassandra sorted by year. To get movie directed by Quentin Tarantin and James Cameron in 1994 and 2009 respectively, we can:
[qtarantino][1994] == 'Pulp Fiction' //tarantino is the Row Key and 1994 is the sub-key,
aka Column Name. The Column Value is 'Pulp Fiction')
[jcameron][2009] == 'Avatar'
Short Summary: A Row Key in Cassandra is analogous to a Key in Associative Array: it points to a value. As it turns out, the value itself acts like an embedded Associative Array and has keys (Column Names) associated with values (Column Values).

Cassandra Data Model
The above picture reminds me of the movie Inception, how it had dream within a dream. I see a Dictionary inside another Dictionary, if you think of ‘Column Name 1' as a sub key with an associated value. I call this the “Inception Concept” and it's present everywhere in the computing world, not just Cassandra (think Recursion).
Column
A column in Cassandra is very much like a Key-Value pair: It has a key, called Column Name which has an associated value. A column in Cassandra has an additional field called timestamp.
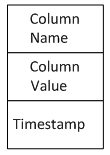
Cassandra Column
To understand the timestamp field, let’s recall that Cassandra is a distributed database running on multiple nodes. Timestamp is provided by the client application and Cassandra uses this value to determine which node has the most up-to-date value. Let us say 2 nodes in Cassandra respond to our queue and return a column. Cassandra will examine the timestamp field of both columns and the one that is the most recent will be returned to the client. Cassandra will also update the node that returned the older value by doing what is called a ‘Read Repair’.
An important point to remember is that the timestamp value is provided by the application: Cassandra doesn’t automatically update this value on write or update. Most applications ignore timestamp values which is fine, however if you are using Cassandra as a real-time data store, the timestamp values become very important.
Cassandra allows null or empty values.
Column Family
Very, very loosely speaking, a column family in Cassandra is like table in RDBMS database like MySQL: it is a container for row keys and their values (Column Names). But the comparison stops there: In RDBMS, you define table schema and each row must adhere to that schema. In other words, you specify the table columns, their names, data types and whether they can be null or not. In Cassandra, you have the freedom to choose whether you want to specify schema or not. Cassandra supports two types of Column Families:
1. Static Column Family
You can specify schema such as Column Names, their Data Types (more on Types later) and indexes (more on this later). At this point, you may be thinking this is like RDBMS. You are right, it is. However, one difference I can see is that in an RDBMS, a table must strictly adhere to the schema and each row must reserve space for each column defined in the schema, even though the column may be empty or null for some rows. Cassandra rows are not required to reserve storage for every column defined in the schema and can be sparsed. Space is only used for the columns that are present in the row.

The client application is not required to provide all Columns.
Note: An application can still insert arbitrary column in static column family. However, it must meet the contract for a column name that is defined in the schema, e.g. the Data Type of the value.
2. Dynamic Column Family
There is no schema. The application is free to store whatever columns it wants and their data types at run-time.
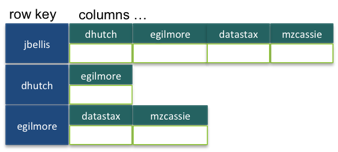
A Dynamic Column Family
Keyspace
A keyspace in Cassandra is a container for column families. Just like a database in RDBMS is a container of tables. Most applications typically have one keyspace. For example, a voting application has a keyspace called “voting”. Inside that keyspace, there are several column families: users, stats, campaigns, etc.
So Far
The picture looks like the following:
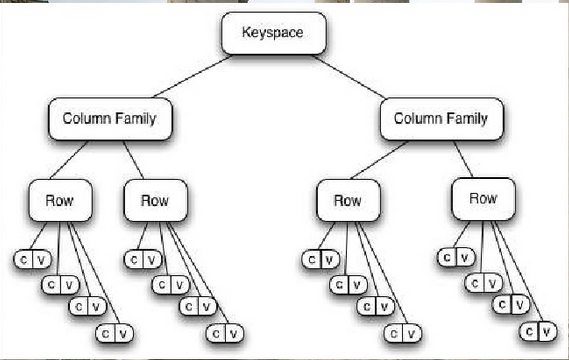
Super Columns: Another Inception Level
Super Columns are yet another nesting inside row key. It groups similar columns together. Back to our inception analogy, starting from the inner most level: Column Families are dictionaries nested inside Super Columns which is another dictionary nested inside the top most dictionary called Row Key. Suppose your row key is the UserID. You can have a Super Column family called Name which contains the Columns FirstName and LastName. When you retrieve the Name super column, you get all the column names within it, in this case Fistname and LastName.
RowKey => Super Column => Column Names
UserID => Name => Firstname, LastName
Counter Columns
If you have used Redis before, you must love the increment feature which lets you increment and retrieve an integer value at the same time. E.g. incr key_name in Redis increments the key_name and returns its value. Cassandra has something similar: Counter Column. A Counter Column stores a number which can be incremented or decremented as you would a variable in Java: i++ or i–. Possible use cases of Counter Columns are to store the number of times a web page has been viewed, limits, etc.
Counter columns do not require timestamp. I would imagine Cassandra tracks this internally. In fact, when you update a Counter Column (increment or decrement), Cassandra internally performs a read from other nodes to make sure it is updating the most recent value. A consistency level of ONE should be used with Counter Columns.
Summary
OK, we have covered a lot of ground here. Let’s summarize:
- Keyspace: Top level container for Column Families
- Column Family: A container for Row Keys and Column Families
- Row Key: The unique identifier for data stored within a Column Family
- Super Column: A Dictionary of Columns identified by Row Key
- Column: Name-Value pair with an additional field: timestamp
Here’s how we will get a value: [Keyspace][ColumnFamily][RowKey][Column] == Column’s Value
Or for a Super Column: [Keyspace][ColumnFamily][RowKey][SuperColumn][Column] == Column’s Value
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




