Introduction
This article explains a new class library I developed to internalize XML-like documents into classes. For brevity, I didn't use the assembly to extract tag contents from a document. I only try to show that the assembly does work consistently. In time, I will add new Windows Forms projects using this assembly. In fact, what this assembly does is to extract HTML or XML tags, attributes, and texts from document. You can see in this image, Count of _seq (938): This is the cell number of the page (tag number).

Using the Code
First of all, to use the DLL, you must add a reference and then add using ddm.Html. Now, it's ready to use. You first read the text from the document file and give this string to the constructor. The main class for parsing the HTML is HtmlDDM. It has two constructors. One takes a string argument, the other does not. You use the main class like this:
StreamReader file = new StreamReader(@"HtmlFiles/page.html", true);
HtmlDDM doc = new HtmlDDM(file.ReadToEnd());
doc.Fill(pbFill);
Here, pbFill is a ProgressBar object. HtmlDDM takes it and runs its PerformStep() method. Now, let me explain what Fill() does. It reads all of the opening, closing, self closing, DOCTYPE, CDATA tags, and sets variables for each of them. And then, it fills the main structure to extract data from the document: blocks. I developed a nested block structure. There is a Block class. This class has a Childs property of List<Block> type. As you can predict, this structure is like an HTML block structure: tags in tags, tags around tags. Tags in tags finds itself in nested blocks. The block object has a StartCell and a EndCell property set in the Fill() method; nested blocks can be easily identified with two cells: start and end. The nested block in the parent block starts and ends inside. For tags around tags (like self closing, CDATA, DOCTYPE, etc.), blocks are also identified. But this time, startCell is equal to endCell, and each of them is the type of self closing cell. I named all kinds of tags with a "<" at the beginning and a ">" at the end. Here, we expand the properties of the Cell class:
public Attributes Attrs { get; set; }
public int x { get; set; }
public int y { get; set; }
public int alpha { get; set; }
public int beta { get; set; }
public int Index { get; set; }
internal int iBgn { get; set; }
internal int iEnd { get; set; }
internal string Name { get; set; }
internal string Type { get; set; }
Attrs is an object of the Attributes class which implements IList<Attribute>. That Attributes object is a list of Attribute objects. x, y, alpha, beta are very important for the workflow of the program. They're signers for border tags (opening and closing tags). If during FillSequence(), the program counts an opening tag, it increments x, else y. That flow is forwards. The other type of flow is backwards, and changes alpha and beta. When backward flow runs, the program increments alpha for opening, and increments beta for closing tags. Next is FillBlocks(). It fills rootBlock with Block objects, each of them with a Childs list of List<Block> type. So, a block can contain child blocks (like an HTML block that contains head and body blocks), and these children may also contain children. That is the Document Digest Model I propose. In this image, you can see this clearly:
Now, here are the methods and properties of the CellSequence class:
FillBackAndForth() here makes the forwards and backwards flow of x, y, alpha, and beta. And after that method, Methods.IsCellBalanced() takes the first cell and checks if there is imbalance. If not, the sequence is intact. If yes, the program throws an exception with a message stating that documents with deficient tags are not allowed. But how does the program see the tag structure is deficient (like an unclosed td tag or a wrongly used self closing schema)? That is done by this calculation: when the program fills x, y, alpha, beta, the structure becomes meaningful; because, an arbitrary cell's x is the opening tag count till that cell, and y is the closing tag count till that cell from the beginning. And, that cell's alpha is the opening cell count from the end, and beta is the closing tag count from the end. To make sense, I will give the first and last cell's values in a two cell simple document:
firstCell:Open
lastCell:Close
firstCell: x=1, y=0; alpha=1, beta=1;
lastCell: x=1, y=1;alpha=0, beta=1;
Here, as you can see, for open cell, x-y = beta-alpha + 1, and for close cell, x-y = beta-alpha - 1. That makes the cell balanced. If all of the structure of the border cells (open and close) is intact, the balance check of any cell will be successful, if not, it won't be successful ever. Here, it's time to emphasize that the sequence of cells is represented by the CellSequence class. As you can see, it implements IList<Cell>. That is important because the Add() method must increase the Index property of the cell. By the way, the cell includes a property named Index. This property is available for all cells. But x, y, alpha, beta are available only for border cells. Above, GetCorrespondingCell() is important too. It finds the end cell of the start cell, and the start cell of the end cell. But how? Using this calculation: as I mentioned before, border cells have four values (let's call them track signs). With a little calculation over track signs, you can find the corresponding signs. If you have a method to find the depth of cell, you can compare other cells' depths with firstCell, and when you find a match, take it as endCell and stop. Let me show you how:
As you can see, the depths of the start and end cells are the same. But, how do we find the depth of an arbitrary cell from only track signs: it's simple: if the open tag: x-y-1; if the close tag: x-y. You can try it on the two cell document examples given before: 1-0-1 (firstCell) == 1-1 (endCell). You can trust it works on a 938 cell document in the w3.org page.
Now, I will explain the library for interested audience:
The Base namespace is for the base class and its dependencies. The base class is DDM_Base. It's an abstract class. The base class is in Base.Classes. There is one more class: Block. The Enumerations, Exceptions, and Methods classes are present in the ToolBox namespace. Methods is a static class because it encapsulates some necessary methods that will be used in the program, but unnecessary to contain in instances for performance reasons. The Exceptions class contains the exceptions of Base. The namespace I most like is the Settings namespace. It contains extra delimiter settings for the program. In a future version, I plan to make the program get its settings from an external settings file. So, for example, if you want to add a new delimiter for HTML 4.0 (let's say, DELIM), you simply edit the XML settings file and when the program starts, it's there. I think it's time to talk about it. In Settings, there is a Delimeter.cs file:
internal class Delimeter
{
public Delimeter()
{
}
internal string Begin { get; set; }
internal string End { get; set; }
internal string Type { get; set; }
}
internal class StandartDelimeter : Delimeter
{
public StandartDelimeter()
{
}
public StandartDelimeter(string begin, string end, string type)
{
Begin = begin;
End = end;
Type = type;
}
}
In this file, there are two classes. One is for extra delimiters like CDATA, DOCTYPE, etc. These delimiters are not open or close type. They're extra. And, each of them takes its own type. The standard delimiters are "<", ">", and "Standart". I made the program extendible so that you can change standard delimiters. In the Delims static class, there is a static constructor that reads delimiters (standard, borders, extra) and fills the Standart, Borders[], and Extra variables. Then, in the program, they're used in various places.
The Cells namespace is about the Cell class and its dependencies. Attribute is a simple class with name and value properties. The Attributes class is an implementation of IList<Attribute>. CellSequence is an IList<Cell>.
Points of Interest
I made several attempts to find a good solution. At the beginning, I made a text search based document parse library. But to parse a medium level HTML document with it took 7 minutes. So I quit and started this project.
History
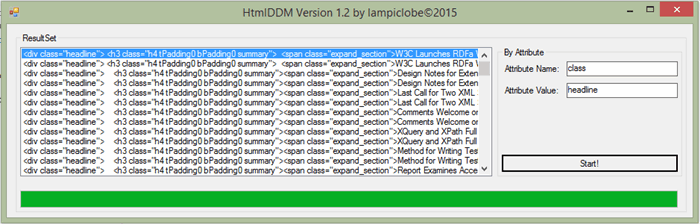
This version runs better; it also lets the user to search in page.html with the specified attribute names and the corresponding values.
I am a software developer emphasizing algorithm side of development.





