Abstract
Over the last years XML has grown in importance when it comes to storing data on stream-oriented media. In most cases, DOM-API implementations are used to handle storing and manipulating data in memory. This article shows how to use an alternative API - the SAX-API - in a generic way with an application to automated code generation from XML schema definitions in mind. A C# implementation of a simple to use yet flexible framework for interaction with SAX parsers is presented.
1 Introduction
This article assumes the reader to be familiar with general XML processing and especially with the classes from the System.Xml namespace of .NET. Some familiarity with C# programming is also expected. The rest of this section will first give some motivation and then outline the main characteristics of SAX parsers, followed by an overview of a possible interaction framework with SAX parsers.
The second section introduces a C# implementation of such a framework and explains its overall design principles. Some hints on porting to other languages are given. The third section concludes this article by showing some examples on how to use the framework and, finally, gives some outlook on the second part article which will introduce a mapping to XML schema definitions to the framework.
The solution provided contains several VS projects. Of these, "SaxParserSupport" builds the framework. The other projects contain the examples from section 3.
1.1 Motivation
Over the last years XML has considerably grown in importance when it comes to serialize and deserialize data in a portable, platform-independent way. Many people use DOM to access XML content in favour to SAX. This is especially true for reading access. They avoid the burden of implementing the processing of data in the context of the XML parser, which is done by DOM automatically. However, on closer inspection it becomes evident that much of the source code for this processing work can be done in a generic way. More important, it can be automated as is shown in the follow-up article, making use of SAX quite benign to the programmer.
Another way read or write XML data is use of System.Xml.Serialize.XmlSerialization implementations. This interface takes an instance of a suitably designed class and serializes or deserializes it into XML. .NET SDK contains a tool that can autogenerate C# classes from schema definitions. For details, refer to MSDN documentation on xsd.exe.
The generated classes, however useful in many scenarios, suffer from two serious drawbacks: First off, they don't allow for behavioural customization by inheritance. Instead, class instances are hardwired as members into the generated classes. Dynamic behaviour, e.g. consistency checks, cannot be performed during parsing. As a consequence, XML data always is represented in a tree-like structure much like the way DOM does. Secondly, as there is no XML parser involved, they don't allow for on-the-fly validation the way XML parsers do.
1.2 The outset: DOM vs. SAX
To read XML content into memory, programmers often rely on DOM. DOM is a simple, easy to use and, most important, out of the box way to get data from XML content into a memory representation. Likewise, DOM implementations usually provide some means to transform such a memory representation into XML content.
However, this ease of use comes with a price tag. First of all, DOM parsers create an in-memory tree, whose nodes are instances of a well defined, finite set of classes. While sufficient in most situations, there might be cases where a tree representation is not adequate or one might want a more refined view of data-node relationship than the one DOM provides.
The second drawback with DOM is that the complete XML content is included in the DOM tree, regardless of whether it is of actual interest. For large amounts of XML contents this might lead to an unacceptable large memory footprint.
An alternative to DOM, SAX or "Simple API to XML", does not suffer from this limitations. Instead of creating a tree in memory, SAX provides a forward-only iterator view of the XML content. Each time certain conditions are met, SAX implementations enable the client application to take appropriate action in response to that condition. These conditions being true can be interpreted as firing an event. In fact, SAX is sometimes referred to as event-driven XML parsing.
Examples of such events are: Start of document, start of XML element, end of XML element etc. Each event is attributed with some set of data, that describe the event. An event indicating an opening tag of an XML element, for example, carries the tag name and the set of attributes. Two things are important to note: The complete stream of events along with their accompanying data is sufficient to fully describe the XML content, i.e. at any time the XML content can be reconstructed up the point the SAX parser has most recently read. Secondly, and even more important, the structure of the event stream is independent from the actual XML content. I.e. the first event always indicates start of the XML content, each event indicating the opening tag of an XML element is matched by an event indicating the element's closing tag implicitly or explicitly, and so on.
1.3 Observations on using SAX
As pointed out in the last subsection, the XML content can be reconstructed from the sequence of events generated by the SAX parser. Of course, one is not limited to simple construct XML from this sequence. Instead, any data processing can take place as required by the client application. Not surprisingly, the basic framework of client interaction with the SAX parser is of a quite simple structure. For example, consider the following chunk of XML content:
="1.0"="UTF-8"
<root someAttr="someValue">
<child />
</root>
When encountering the closing bracket of the root-starttag, a client application would be notified by the SAX parser. In response, it would then instantiate a class suitable for representing the data from the root element (following on, the terms "element" and "tag" are used interchangeably) and some representation of the someAttr attribute to the value someValue , which is provided by the SAX parser.
The parser will continue to read XML content and thus encounter the child tag next. Again the client will be notified, but this time it instantiates a class suitable for representing the child element in the context of the root element. This is an important detail - in contrast to its structure, the semantics of a XML element are determined by its enclosing element, if such one is present. Consider the following XML content:
<root>
<child />
<otherchild>
<child />
</otherchild>
</root>
The second instance of the child element may well have the same structure as the first. In fact, it might even have the same interpretation of its data. But because the first one is in the context of the root element and the second in the context of the otherchild element, information collected or synthesized by their respective parent elements might differ significantly. For example, the root element (or rather its representing class) may interpret the child element as data, while otherchild may want to ignore it altogether.
A XML element has been completely parsed when its endtag is encountered. SAX parsers reflect this by generating an endelement event for the current element. On receiving this event, the client application can trigger processing data by the class instance representing the current element or its parent element.
1.4 A Simple Parsing Algorithm
With all this in mind, a simple algorithm for XML parsing with SAX can be laid out:
- Set up some SAX parser implementation. Instantiate some class representing the root element of the XML content to be parsed. The root element is the first XML element in the content. Set up some stack implementation with an empty stack.
- Start the parsing process on the XML content
- On a
startelement event, if the stack is empty push the instance representing the root element. Otherwise use the top element of the stack to look up the class representing the current element by the current element's qualified name and push this instance on the stack. Set attributes in the stack's top element according to the values provided by the parser.
- On an
endelement event, pop the top element from the stack and process it by the new top element, if there is one. If the stack is empty, parsing is finished.
- On a
text event, process text as the stack's top element sees fit.
- Likewise for
whitespace and significantwhitespace events.
This algorithm isn't all bells and whistles - for example, entity resolving isn't covered - but it should be sufficient to show the general direction an implementation might go. One word of caution though - there are two approaches to implementation of SAX parsers: The first one is commonly referred to as SAXReader. It uses direct callbacks into the client to indicate events. Xerces of the apache project is an example of this approach. The second flavor is known under the name XMLReader. System.Xml.XmlReader from the .NET framework is an example. XMLReader implementations use a pushmodel to parse sequences of XML content under the control of the client application. Therefore, they are slightly more efficient.
Note that the System.Xml-namespace does not provide SAXReader. There are some small differences in their respective APIs, which shouldn't pose much trouble, though. For the rest of this article, System.Xml.XmlReader is used.
2 Implementation Overview
This section introduces a sample implementation of a framework for interaction with SAXParsers. At first, the structure of the framework is explained, i.e. the implementing classes. After that the two main issues in SAX parser interaction - how to map XML elements to representing classes and how to store XML attributes - are discussed. Interspersed, there are some notes on using other languages than C# for implementation.
The information presented shows just an overview. For detailed method descriptions refer to the documentation contained inside the source code.
2.1 Structure of the Framework
The framework for SAX parser interaction is called SaxParserSupport. It defines two namespaces, SaxParserSupport and SaxParserSupport.Impl. While the former defines the API, the second contains a sample implementation. Two wrapper classes for System.Xml.XmlReader are contained as well as implementing classes to represent XML elements. These implementations should be sufficient to act as a base for day-to-day use. Of course, they can be replaced by customized implementation at any time.
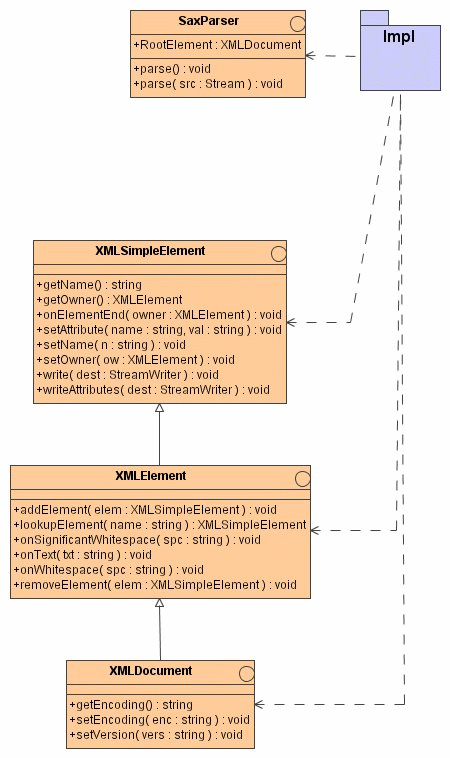
Fig.1
The interface classes from namespace SaxParserSupport are shown in Fig.1 as a UML Class Diagram.
Namespace SaxParserSupport
The interface class SaxParser defines the API of a wrapper class for a SAX parser instance. It exposes two methods
void parse();
void parse( System.IO.Stream src );
that start the parsing process. The first one uses the current setup of the instance, the second one the given System.IO.Stream instance to read from. The details of set up are left to the implementation. The start or root element is determined by the property RootElement, an instance of XMLDocument. Both methods may throw exceptions related to IO issues and/or XML parsing.
XML elements are modelled by a hierarchy of three interface classes, XMLSimpleElement, XMLElement and XMLDocument respectively. The basic behaviour of XMLElements is modelled by interface XMLSimpleElement:
public interface XMLSimpleElement {
void setAttribute( string name, string val );
string getName();
void setName( string n );
void onElementEnd( SaxParser.XMLElement owner );
SaxParser.XMLElement getOwner();
void setOwner( SaxParser.XMLElement ow );
void write( System.IO.StreamWriter dest );
void writeAttributes( System.IO.StreamWrite dest );
}
The characteristics of an XML element are element name and the parent XML element. Access to the getters and setters for name and owning element is public because of C# language requirements. However, they should be in a protected context, only.
Method onElementEnd is the callback to be called by a SaxParserInstance on encountering the closing tag of an element. Implementations should provide at least an empty method. Note that this method should be treated as if declared protected.
write and writeAttributes write the XML element to the given StreamWriter. The latter one is meant to be protected, again. Implementations are expected to perform any required transcoding of characters, e.g. '&' to '&', on their own.
Use write to write an instance of XMLSimpleElement to a StreamWriter.
setAttribute is called to set the value of a XML attribute. It is up to the implementation to provide a means to map XML attribute names to data structures for storing.
Interface XMLElement refines XMLSimpleElement by adding support for child XML elements:
public interface XMLElement : XMLSimpleElement {
void addElement( SaxParser.XMLSimpleElement elem );
void removeElement( SaxParser.XMLSimpleElement elem );
SaxParser.XMLSimpleElement lookupElement( string name );
void onSignificantWhitespace( string spc );
void onText( string txt );
void onWhitespace( string spc );
}
addElement and removeElement establish or destroy a parent-child relationship with the child XML element specified by parameter elem. Typically, they will also set the owner of elem as indicated by elem.getOwner().
Lookup of possible child element representing classes is done by method lookupElement, based on the qualified name as specified by System.Xml.XmlReader. If there is no namespace available for the XML element in question, i.e. its local name equals the qualified name, the local name prepended with an ':' is used. Both SaxParser and XMLElement implementation are tightly linked together here, because the name to be matched is generated by the SaxParser implementation. Apart from that, implementations are free to use other mapping schemes.
Callback methods onSignificantWhitespace, onText and onWhitespace are to be called by the SaxParser implementation. Again, they are supposed to be used in a protected context.
In contrast to DOM parser behaviour, there is no need to create special classes for test and (significant) whitespace. If sufficient, the string instances given to the three methods can be stored in the instances representing the respective parent elements.
Interface XMLDocument, finally, models the start or root node of XML content. For the time being, this is limited to representing XML version and encoding:
public interface XMLDocument : XMLElement {
string getEncoding();
void setEncoding( string enc );
void setVersion( string vers );
}
When writing to a System.IO.StreamWriter, implementations should take care that the encoding of the StreamWriter instance and the one given by the getEncoding method do match.
Namespace Impl
This subsection describes a sample implementation of the API described above. In Fig.1, it is contained in the package Impl which maps to a C# namespace Impl. As before, the discussion is centered on the principles of design. For implementation details, refer to the source code documentation. The contents of namespace Impl are shown in Fig.2:

Fig.2
Classes SaxParserImpl and SaxValidatingParserImpl both implement the SaxParser interface. Both use instances of System.Xml.XmlReader to do the actual parsing, with the latter one using a System.Xml.XmlValidatingReader instance set up to perform XML schema validation.
The interface classes for XML elements are implemented by classes XMLSimpleElementImpl, XMLElementImpl and XMLDocumentImpl, respectively. Creating a class representing a given XML element is done by derivation from one of these classes. The way these classes work might impose some limitations on how to derive such classes.
The main purpose of class XMLSimpleElementImpl is to store an element's tag name and attributes. The tag name is stored in its qualified form, that is, for
<element/>
<NS:element2 xmlns:NS="http://www.foo.com/bar"/>
XMLSimpleElement.getName() will yield element resp. NS:element in these two cases. Implementations may provide means to lookup the namespace from the alias.
Attributes are implemented as follows: If an attribute name starts with "xmlns:", it is assumed to be a namespace alias declaration. Namespaces and their aliases are stored for internal mapping.
The attributes xsi:schemaLocation and xsi:noNamespaceSchemaLocation are ignored as they are only relevant to a validating parser. However, they are stored to be included if the instance is written to a System.IO.StreamWriter.
All other attributes are tried to be mapped to a C# property with the same name as the attribute. If the attribute name contains a ":", the name of the C# property has a "_" at the corresponding position(s). If the mapping fails, implementations may choose whether to ignore the attribute or throw an exception.
Attributes, whose name would lead to an invalid property declaration because of reserved words in C#, are treated in a special way - they are mapped against a property name with a leading "@". That is, an attribute of name base will be mapped to a property of name @base.
On successfull lookup of a C# property, an instance of the property's class is created from the attribute's value string (this string is equal to the System.Xml.XmlReader's Value property at this point). Creation is done via a constructor with one string parameter. If this constructor cannot be found or the property is readonly or non public, an exception is to be thrown.
Lookup is done by reflection. Languages that don't support reflection (e.g. unmanaged C++) must use some other means to perform lookup - dictionaries may be a good choice here. Reflection is also used in locating the constructor.
When executing writeAttributes, the XMLSimpleElementImpl iterates through all properties, converts their values to string and writes these pairs to destination after performing necessary transcoding of attribute names and values.
XMLElementImpl maintains a collection of XMLSimpleElement instances. Specifically, when executing onElementEnd, a XMLSimpleElement instance may remove itself from its parent. Details are left to the implementation.
The second role of XMLElementImpl is to implement lookup for child XML elements. The sample implementation uses a simple mapping of the qualified element name to a C# class name. The mapping is done on a per-class basis, i.e. in
<root>
<bar>
<foo>
</foo>
<bar/>
</root>
bar is mapped to two distinct classes for representation, albeit the XML elements are the same (assuming same definition of the bar tag in both cases). If local and qualified names are the same, the (local) name must be prepended by ":". This is caused by the implementation of SaxParserImpl.
Because the mapping is done per class, static constructors can be used to set up dictionaries with appropriate tag name/class name pairs. XMLElementImpl defines an abstract method
System.Collections.IDictionary ElementClasses
{
get;
}
that returns a dictionary containing the name pairs. The class name in the dictionary must be the fully qualified class name including namespaces and assembly name.
Method writeSubElements can be overridden to change the way child elements are written. For example, this is the case if mixed content is to be emitted.
Class XMLDocumentImpl implements the XMLDocument interface. Currently, this means managing information about the encoding to use for output and the XML version, which is hardwired to "1.1".
2.2 Contracts
The sample implementation assures that at any time, several invariants summarized as follows will hold:
- When reading XML content from a
System.IO.Stream or System.Xml.XmlReader, error conditions are indicated by throwing an exception.
- While reading XML content, exceptions thrown will be because of IO error conditions, malformed XML content including violation of schema definitions if an instance of
SaxParserSupport.Impl.SaxValidatingParserImpl is used. Additionally an exception is thrown if the RootElement property of the SaxParser instance is not set. Additional exceptions may be thrown if C# properties cannot be looked up or if their representing classes lack required constructors.
- It is in the reponsibility of the representing classes to ensure that properties are initialized as required.
- No exception being thrown during execution of
SaxParser.parse or SaxParser.parse(System.IO.Stream) methods indicates successfull reading of XML content and (possibly) schema validation.
- At any time, encountered child XML elements shall be mapped against an instance of a representing class. If such a class cannot be found, an exception is thrown. The context for mapping is the enclosing element representing class. Attributes, whose names are invalid as property names, because they are keywords, will be mapped to property names with a leading "@" (see above).
- At any time, encountered attributes shall be mapped against a C# property of the class representing the current XML element. If such a property cannot be found, an exception will be thrown. The property must be of a class that has a constructor taking one
string instance as parameter. The attribute name might be transcoded to match a property name.
- Text and whitespace are ignored by default. If they are encountered, callbacks
XMLElement.onText, XMLElement.onSignificantWhitespace and XMLElement.onWhitespace, respectively, are executed, however.
- When executing
XMLSimpleElement.onElementEnd, the parameter given to this callback denotes the instance of the class representing the enclosing element. It is thus equal to the result of method getOwner. All attributes have been stored in their respective properties.
2.3 Limitations
As of now, the sample implementation imposes these limitations:
- Currently, declarations for default namespace aliases, i.e. the
xmlns-Attribute, are not supported.
- The namespace alias for the www.w3.org/2001/XMLSchema-instance is assumed to be xsi. This is important for proper recognition of some predefined attributes.
- As the implementation uses C# properties to represent XML attributes, classes derived from
XMLSimpleElementImpl must enforce a strict one-to-one relationship between properties and XML attributes.
- Properties used for XML attributes must be of
public access along with their classes. If this is not the case, NotImplementedException will be thrown when the property is to be set by the framework. Non-public properties are not considered when writing to a stream.
- Classes that are used for C# properties must provide a constructor taking one
string instance as parameter. Moreover, an implementation of System.Object.ToString() must be provided.
- For property lookup, the property's namespace alias - if present - is used, not the actual namespace itself. This is because of difficulties in mapping an URL into a valid C# identifier and needs certainly some attention in the future.
- Hashtables used for child element lookup must contain the complete mapping of child elements for a class. Neither should derived classes use the hashtable of their base class, nor will such base class dictionaries be considered for lookup.
- Currently there is no support for
xsd:any and CDATA content. For CDATA, support will be added in a future release. Whether this is possible for xsd:any remains to be seen due to the vague semantics to of this content type.
3 Examples
This section shows some examples on how to use the framework. Only the key elements are shown. For the complete example source see the project files supplied. All examples will write XML content equivalent to the original except for ignorable white space if the write method for the root element is called.
3.1 ParserSetup - setting up the parser
To use the framework, an instance of SaxParserSupport.SaxParser must be set up with an System.Xml.XmlReader or System.IO.Stream instance:
SaxParser parser = new SaxValidatingParser(
new FileStream( args[ 0 ], FileMode.Open ) );
parser.RootElement = new MyRoot();
With an instance of class MyRoot as root element, a simple XML content as shown below can be parsed:
="1.0"="utf-8"
<rootelement>
</rootelement>
The corresponding implementation of MyRoot looks like this:
public class MyRoot : XMLDocumentImpl
{
public MyRoot()
{
}
protected override IDictionary ElementClasses
{
get
{
return null;
}
}
public override void onElementEnd( SaxParserSupport.XMLElement owner )
{
Console.WriteLine( "Finished root element" );
}
}
Note that as MyRoot doesn't have child elements, it can simply implement ElementClasses as null. This will change in the next example.
3.2 ChildElements - Elements with Children
="1.0"="utf-8"
<rootelement>
<childone/>
<childtwo>
<grandchild/>
</childtwo>
<childone/>
</rootelement>
Here rootelement can have two child XML elements, childone and childtwo, the latter one having a child grandchild itself. Therefore MyRoot uses a static constructor to map the element names to the elements' representing classes. Note that because parent-child relationships are modelled on class level, it is sufficient to use static members for storage and setup. MyRoot now looks like this:
public class MyRoot : XMLDocumentImpl
{
static MyRoot()
{
_elementclasses = new Hashtable();
_elementclasses.Add( ":childone",
"ChildElements.MyRoot+ChildOne,ChildElements" );
_elementclasses.Add( ":childtwo",
"ChildElements.ChildTwo,ChildElements" );
}
public MyRoot()
{
}
protected override IDictionary ElementClasses
{
return _elementclasses;
}
public override void onElementEnd( SaxParserSupport.XMLElement owner )
{
Console.WriteLine( "Finished root element" );
}
private static IDictionary _elementclasses;
public class ChildOne : XMLSimpleElementImpl
{
public ChildOne()
{
}
public override void onElementEnd( SaxParserSupport.XMLElement owner )
{
Console.WriteLine( "childone finished" );
}
}
}
Because there are no namespaces used, the names of the element representing classes are prepended with ":". They are used as keys to map against the fully qualified class names of the representing classes. As these classes are instanced from inside another assembly (the SaxParserSupport assembly), the assembly name must be included. The hashtable is accessed via ElementClasses.
ChildOne inherits from XMLSimpleElement. The class is nested inside MyRoot. This has not always to be case, as the class for childtwo, ChildTwo, demonstrates. It is set up in a manner similar to MyRoot.
3.3 Namespaces
This example illustrates how to cope with namespace alias declarations. Consider the following XML content:
="1.0"="utf-8"
<NS:rootelement xmlns:NS="http://www.foobar.com/NS">
<NS:childone />
<NS:childtwo>
<grandchild/>
</NS:childtwo>
</NS:rootelement>
To accommodate addition of the namespace aliases, the only thing to be changed is is the mapping of class names in the static constructors of MyRoot and ChildTwo:
_elementclasses.Add( "http://www.foobar.com/NS:childone",
"Namespaces.MyRoot+ChildOne,Namespaces" );
_elementclasses.Add( "http://www.foobar.com/NS:childtwo",
"Namespaces.ChildTwo,Namespaces" );
Note that namespace alias declarations are attributes that are treated in a special way.
3.4 Attributes - Adding attributes to elements
This example demonstrates how to make use of attributes. Let's assume the grandchild element has attributes name and xsi:id with the latter from the XMLSchema-instance namespace. Then an example XML content could look like this:
="1.0"="utf-8"
<NS:rootelement xmlns:NS="http://www.foobar.com/NS"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<NS:childone />
<NS:childtwo>
<grandchild name="martin" xsi:id="bar" />
</NS:childtwo>
</NS:rootelement>
Class ChildTwo.GrandChild now has two properties name and xsi_id that correspond to the two XML attributes. Both properties are of class StringAttribute for convenience, but they could be of any class required provided that a suitable constructor for that class is available. GrandChild's implementation now looks like this:
class GrandChild : XMLSimpleElementImpl
{
public GrandChild()
{
}
public override void onElementEnd(XMLElement owner)
{
Console.WriteLine( "grandchild finished -> name={0} id={1}",
_name.ToString(),_id.ToString() );
}
public class StringAttribute
{
public StringAttribute( string s )
{
_str = s;
}
public override string ToString()
{
return _str;
}
private string _str;
}
public StringAttribute name
{
get
{
return _name;
}
set
{
_name = value;
}
}
public StringAttribute xsi_id
{
get
{
return _id;
}
set
{
_id = value;
}
}
private StringAttribute _name;
private StringAttribute _id;
}
Any C# property to be used as XML attribute representation MUST be public for two reasons: First, they are accessed from inside the framework and, second, being public is used to distinguish properties for XML attributes from others for class implementation. This is done with tools like UML editors in mind who use C# properties for UML attributes. As a consequence, public properties should not be used for other purposes than XML attribute representation. Otherwise, XMLSimpleElement.writeAttributes should be implemented in a appropriate way.
3.5 Text1 - Simple Text processing
The default implementation for XMLElement simply discards any encountered text. This example shows how use the onText method. (Significant) whitespace can be dealt with in a likewise manner. Consider the following XML content:
="1.0"="utf-8"
<rootelement>
The quick brown fox jumps over the lazy dog
</rootelement>
Here the root element contains only text. Consequently, support for child elements is eliminated. Instead, the onText method has been overriden to handle text:
public class MyRoot : XMLDocumentImpl
{
public MyRoot()
{
}
protected override IDictionary ElementClasses
{
return null;
}
public override void onElementEnd( SaxParserSupport.XMLElement owner )
{
Console.WriteLine( "Finished root element - text was: {0}",
_txt.ToString() );
}
public override void onText(string txt)
{
_txt.Append( txt );
}
protected override void writeSubElements(System.IO.StreamWriter ostr)
{
ostr.Write( _txt.ToString() );
}
private StringBuilder _txt = new StringBuilder();
}
3.6 Text2 - Complex text processing
The simple processing pattern from the last example might not be sufficient in more complex cases, for example when dealing with mixed XML content as in:
="1.0"="utf-8"
<rootelement>
The quick brown fox
<child/>
jumps over the lazy dog
</rootelement>
In such a scenario one might implement a custom XMLSimpleElement class to use its instances as pseudo nodes:
class Text : XMLSimpleElement
{
public Text( string t )
{
_txt = t;
}
public void setAttribute(string name, string value)
{
}
public void write(System.IO.StreamWriter ostr)
{
ostr.WriteLine( _txt );
}
public void setOwner(XMLElement se)
{
_owner = se;
}
public XMLElement getOwner()
{
return _owner;
}
public string getName()
{
return "";
}
public void setName(string n)
{
}
public void onElementEnd(XMLElement owner)
{
}
public override string ToString()
{
return _txt;
}
private XMLElement _owner = null;
private string _txt;
}
MyRoot will use this class like this:
public override void onText(string txt)
{
addElement( new Text( txt ) );
}
Note that writeSubElements is not needed in this special case, anymore.
4 Future Directions
The framework relieves the programmer from a great deal of boring infrastructure to be implemented when using SAX parsers. Still, it is somewhat clumsy to use because of the limitations and invariants described above. However, its intended purpose is to be used in conjunction with a tool for synthesizing classes from XML schema definitions (XSD). Except for the issue with xsd:any content, 100% coverage of the rich spectrum of XSD should be possible. Implementation of this tool will be the topic of the second article.
The supplied implementation uses C#, but the framework was designed with other languages in mind, too. In fact, porting it to other OOP languages with reflection support, e.g. Java, should prove quite easy. Languages like unmanaged C++, that don't offer reflection will have to use other means of achieving constructor and property lookup. Cleverly designed dictionary structures may be a good choice here.
Updates
- 05-18-04 - replaced
Hashtable with more general System.Collections.IDictionary for element lookup; replaced method getElementClasses with property ElementClasses


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




