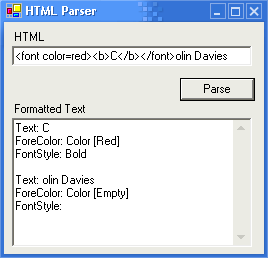
Introduction
Around the second week of May, Christian came up with a great feature for the
screensaver. It would be great for it to parse the HTML contained in some people's names.
Since he was busy adding other features I took up the task.
My first thought was to use some regular expressions with named references to
pick out the tags and use the group to do it again and again until I had nothing
but text in the group.
This, as it turns out, is a lot of work for doing something the .NET
Framework already does. First a little background on the type of HTML that
we will be parsing at the end of the article.
Structure of an HTML fragment
A fragment consists of zero or more tags and zero or more strings. It
is perfectly valid for a fragment to consist of an empty string.
A single tag has three parts: opening, value, and closing. The
opening part of the tag consists of the tag name, and zero or more
quoted-attributes. The value part of the tag can contain more tags, text,
or nothing. The closing part of the tag consists of just the name prefixed
with a forward slash (/name).
We will not allow one tag to start inside another tag, but end out side of
it. So this is not valid <b><i>f</b>oo</i>
notice that the 'b' tag ends before the 'i' tag.
Here is an example of a valid HTML fragment.
<font color='blue'>M<b>y</b> <i>name</i></font>
<b>i</b>s....
Here is the breakdown of the above fragment
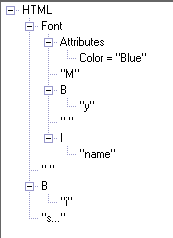
The tree nodes that are in quotes are the actual values that get output in
the text. In this example the only tag that has an attribute is the Font
tag, and you'll notice that the attribute is named "color" with the value of
"blue".
Parsing the HTML fragment
To produce the resulting formatted document you start at the top and work
your way down following each node as you come to it building up styles as you
go. When you reach some plain text, you take the current format and
package it with the text storing it for later use. When you reach a node
you cache the current format, so when you go into the next child node you don't
have formatting from the first child node.
So how does one actually go about doing this? The fragment structure I
have described above is really an XML fragment, so we can use .NET's XML parser
to do the dirty work and we can just step through the resulting "tree".
There is one small problem that we need to fix before we can let .NET do the
work for us. A valid XML document has one root tag, our HTML fragment
doesn't require everything to be contained in one tag. The remedy is to
place the fragment inside of a tag, such as <html> & </html>.
Formatting structure
In our simple parser there are only several different formats that are
supported. Text color, bold, italic, underline, superscript, and subscript
are the only formats in this parser; adding additional formatting is just a
matter of looking for more tags and attributes.
Since formatting is built-up I have created a class called TextStyle, which
is responsible for keeping track of the current format. It has two
constructors; one that creates a default TextStyle with no formatting, and
another that copies a TextStyle.
Parsing the HTML (XML) document
In this code it uses recursion to parse each node as it comes up. Text
placed in the open has an XML node created for it by the framework, it is named
#text.
Rather than copy and paste all of the code here, I will refer you to the
source; I will describe the key parts of the code.
Determining font color
XmlNode node;
switch(node.Name.ToLower())
{
case "font":
if( node.Attributes != null )
{
foreach( XmlAttribute attribute
in node.Attributes)
{
switch(attribute.Name.ToLower())
{
case "color":
ParseColor(attribute, style);
break;
}
}
}
break;
}
private void ParseColor(XmlAttribute a, TextStyle style)
{
if( attribute.Value[0] != '#' )
style.ForeColor = Color.FromName(attribute.Value);
else
{
try
{
int r, g, b;
r = Int32.Parse(attribute.Value.Substring(1,2),
System.Globalization.NumberStyles.HexNumber);
g = Int32.Parse(attribute.Value.Substring(3,2),
System.Globalization.NumberStyles.HexNumber);
b = Int32.Parse(attribute.Value.Substring(5,2),
System.Globalization.NumberStyles.HexNumber);
style.ForeColor = Color.FromArgb(r, g, b);
}
catch
{ }
}
}
In ParseColor you'll notice that I'm not using the Convert class to convert the
color values to hexadecimal RGB value to Int32's. This is because I need to
specify the HexNumber NumberStyle for the Parse() call so that it
converts the hexadecimal number and not throw an exception. I wrapped the code in a
try/catch block just in case the color value isn't valid.
That's the only interesting bit of code I see in the parsing (its also the
only one that is more than 2 lines long).
As you are building up styles, eventually you will run across a node named
"#text". This node contains the text that is inside of all the tags at
that point. With that knowledge in hand we can now take the text contained
inside it, and the current formatting and add it to the list of formatted text
we have already created.
Displaying the formatted text
Displaying the text is relatively easy, assuming the enumerator for your
collection retrieves items in the same order they were added in. Using the
foreach looping method you can iterate through each TextStyle and format the
text as needed.
Common problems
Unquoted-attributes
Depending on who wrote the HTML, the attributes may or may not be quoted.
This is a problem because XML requires them to be quoted. This results in
having to pre-parse the HTML to ensure that all attributes are quoted.
It turns out that regular expressions work quite well for this job. I
have to use a two-step process in quoting the attributes because I couldn't find a
way to use the named references in the string that is used to replace the
selected attribute name/value pair.
The regular expression (RE) for finding the attribute name/value pairs follows
\<(?<tagName>[a-zA-Z]*) (?<attributeName>[a-zA-Z]*)( )*=( )*(?<attributeValue>[#a-zA-Z0-9]*)?>
There is a bug in the RE above (and in the code that does the actual
replacement); it will only work on tags that have one
attribute. Soon as I figure out how to go about fixing it I will post the
updated code and explain it here. Since the parser only parses one tag
that has attributes this isn't likely to be a problem. Because of the bug
I'm going to wait until I fix it before the second part to quoting
unquoted-attributes.
Malformed XML
In the event that the HTML is malformed, the Parser will throw an exception.
Fear not though, I have supplied a method to remove all XML like tags from a
string that is passed in. It uses a very simple RE to find a tag, then
replaces it with an empty string. <.*?> is the RE for finding a tag.
Conclusion
There are a few improvements I would like to the code. Mike Dunn
suggested fixing up the HTML so that it becomes valid XML before trying to parse
it as an XML document. It doesn't seem like it would be too difficult to
do; but time doesn't allow me to implement it. Maybe I'll get to it next
week.
The demo program parses the HTML then displays the resulting collection of
TextStyles that it built up. If there is an Exception while parsing it
will just string the HTML from the text and stick it into a default TextStyle.

