Gooder Spelling
When I saw the article Spell Check, Hyphenation, and Thesaurus for .NET with C# and VB Samples - Part 1: Single Threading which was published just a short time ago, I was really pleased to find that there is a DLL that does what I've been trying to do on my own for years. In this article, I'll describe a textbox object which incorporates some of the features which were presented in that article as well as describe some other projects which I've been working on that resemble the Hunspell product, including a tool which helps English speaking readers to decipher the Latin language.
First, the Magic Textbox
I will point you to the above mentioned article for a clearer explanation on how Hunspell is used in your programs, but would like to describe the neat features which this textbox class has garnered with its use. Instantiating the textbox is done like any other dynamically generated object:
classTextBoxSpellChecker txtBox = new classTextBoxSpellChecker();
And then, you add it to your form like:
public formRhymes()
{
InitializeComponent();
Controls.Add(txtBox);
Which I'm sure most programmers are familiar with, so there's really nothing to it. As it is, it has two features, and though both are in English, downloading the language files you want and changing the names of the variables in the class is up to you:
const string en_us_DicFilename = "en_us.dic";
const string en_us_AffFilename = "en_us.aff";
const string th_en_us_idx = "th_en_us_new.idx";
const string the_en_us_dat = "th_en_us_new.dat";
Again, for the URLs and information on where to find these files, refer to the above mentioned article. And, note that these files must be present in the working directory of the project in which you plan to use this textbox and the Hunspell tools.
This textbox has two main features which can be toggled on or off:
bool bolShowSpellChecker = true;
bool bolShowThesaurus = true;
public bool spellChecker
{
get { return bolShowSpellChecker; }
set { bolShowSpellChecker = value; }
}
public bool thesaurus
{
get { return bolShowThesaurus; }
set { bolShowThesaurus = value; }
}
When the Thesaurus is on, and the bolShowThesaurus variable is set to true, the textbox will recognize correctly spelled words and automatically generate a list of synonyms for the word close to the cursor, displaying them on a listbox, at the position where the user is currently typing. If this listbox is clicked with the mouse by the user, then the word previously typed is replaced by the synonymous word selected. This listbox will disappear as soon as the user starts typing another word, even if no selection was used.
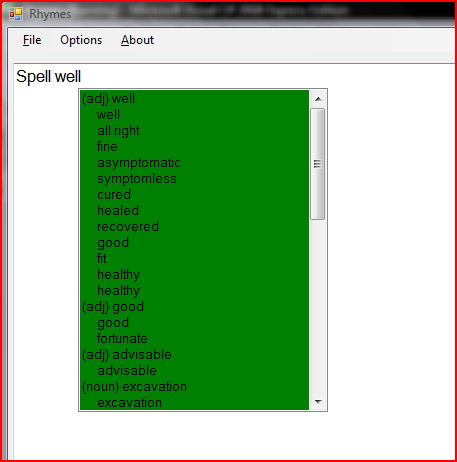
When the spellchecker is on, this same list-box appears near the cursor with a list of alternate spellings which the user may have meant to write. The user can tell the difference between the thesaurus listbox and the spell-checker list-box by the red/green background color which distinguishes one from the other: red for the spell-checker setting off an alarm that the word may be misspelled, and green for the thesaurus if your grammar could use improvement.

And that is about the end of that.
... For the rest of this article, I'll discuss some search trees which don't stand up to Hunspell but were fun to implement. So if all you're looking for is a textbox with a spell-checker under the hood: there it is.
My Latin Project
I've been studying Latin on my own for a couple of years now using a Wheelock's Latin textbook, and I'm still not very good at it, though I've improved considerably with the help of a program I've written that declines and conjugates Latin nouns, adjectives, and verbs. It took me about three months to type a Latin/English Dictionary into a separate database program into my computer. The dictionary database itself is no great marvel of engineering, just three long months of tedious duldrum typing and typing and typing. It consists entirely of text files. Each text file has fields entered sequentially, like 'filename' (a redundant and useless field that caused more problems than it solved), 'heading', 'alt-heading', 'links', and 'main text'. The file's 'heading' field holds the Latin word like 'amo, -are', the latin word for 'love', while the 'main text' contains the definition of the word. Simple stuff. The way the files hold together is with the 'links' field which has a list of filenames that are connected to this one and to which this file points. Using a RecordViewer, each file's content is displayed and the headings of files to which it points via the 'links' field are included on the screen for the user to click and jump to, displaying the files as they are selected.
Database File-Network Out of Text Files
So after I put this database together, I had to organize these files using a search algorithm. There are 24,000 files in the Latin Dictionary, not all of these are Latin word-entries as many are files I call header-files which make the whole network of files easier to navigate; the size of this network of text-files makes publishing this project prohibitive, and the difficulty in finding any entry despite the ease of navigation makes using the project, like you would any other dictionary, far too slow to be worth the while. So I needed a search-engine to make that easier.
Nothing simpler: sample each file in the database in a random order, parse each file's text content out, and insert each word into a binary tree using the words as search keys to go down the tree. When you've found the word already entered into your tree, use a front-end insertion to point to the linked list for that particular word which holds the filenames of all the files in the network that contain this particular spelling.
I don't really want to elaborate on spell trees too much here, but since I mention this and it is a really simple way of making a search-engine, and I think everyone should know how to make one even if they already use SQL or any other database software development kit, I'll ramble on a bit about this at my leisure.
Binary Trees and Linked Lists
A binary tree starts with a root node. Each node has pointers to a left child node and right child node. Initially, these pointers are set to 'null'. Each node also contains something called a 'search key' which is used to navigate down the tree. To find the node you're looking for, you start at the root-node and compare your search word to the search key of that node if the comparison is 'greater' (after in alphabetical order, in the case of lettered search keys), then you fall down to the 'right child node', and alternately, you go left if it is 'lesser', or you're already there if it is neither. You can go right for greater or left for lesser, or either way is fine, whatever way you like. Just remember that with binary trees: you have to be consistent.
In the case of the search engine, you also need another bit of information in each node: a pointer to a linked list. Linked lists are also very useful tools, and if you've never seen these, then I'll have to tell you something about them. Linked lists are similar to binary trees except you might look at them as vines that have no branches. There's a head and a tail, and each node must have a 'next' pointer to another node even if this pointer is set to 'null'. You point to the first one, it points to the next one, and the next one points to the following one, and so on until you reach the last one which points to 'null'. There are many variations of this, like doubly linked lists, which also have a 'previous' pointer, and these items in the list all point to each other. Or, circular linked lists which don't actually end because the last one points to the first one and it goes around and around.
A Search Engine
Getting back to the search engine and putting this bit of thought behind us: each node in the search tree has a pointer to its own linked list. You go down the tree until you find the word you're looking for, retrieve the pointer to the linked list for that word, then move along the linked-list reading off all the names of files in the file-network which contain the word you're looking for. There are an infinite number of applications for this.
OK, so now we (actually 'I' have a Latin dictionary) have a Latin dictionary and a quick way to find what we're looking for. With two separate sets of files for heading search and complete search, to look for words that are either exclusively in the word's heading (like you would a normal desktop dictionary) or a complete search for words that are contained inside the word's definition.
But that doesn't conjugate and decline.
You wouldn't believe the trouble I had in getting that working properly. First of all, I'm a Latin-newbie myself, so I don't actually speak Latin too good, and in the process of learning the language, I was putting together new features for my project to do these conjugations and declensions for every chapter as I learned them, and the final result after two years was a damned mess. But the most difficult part of the whole thing wasn't getting it to actually do the declening, because that's actually the easy part. No, the hardest part was teaching the project to figure out what kind of word it was looking at. So during the first two years of this learning and adding a new patch to my Latin-quilt of knowledge, I went through a constant trial and error of figuring out how to write the code that would consistently resolve the type of word the reader was currently looking at. And so, when I came to rewriting the project and translating it from Visual Basic 2005 to C# 2008, I used the old VB project to copy the entire database, the entire Latin/English dictionary, onto a second directory, and include in each file the type of words I knew them to be, because there was no way I was going to go through another two years of never knowing whether the thing was working properly once I already had it working.
Bored yet? How would I say that in Latin? non gaudes? I don't know...
Latin Look-Up Table
Once that was done, actually writing the code to decline the different types of words was actually pretty easy. And, this time around, I knew what I was doing, so I organized the whole C# version much better, and am quite pleased with it.
So that's not the end of it. Once I had it declining and conjugating for all those different types of words, I wanted a Latin look-up table that I could use to figure out what a word is no matter how it is spelled. You see, Latin is a funny language. Let's say I've found the word 'sustulim' in a text I'm translating, and I don't recognize it or remember what it means. I could try to find 'sustulimus' in my desktop dictionary, but find nothing between 'sustollo' and 'susum', and that doesn't help me because it is listed under the 'T's for 'tollo, tollere, sustuli, sublatum'. You see 'sustulimus' is the first person plural perfect active indicative of the verb 'tollo, -ere' as you can plainly see in the dictionary heading (OK, if you don't know anything about Latin, you have no idea what I'm talking about; which is really my point: if you don't know, you'll never find it).
What I needed to do from here was go through every word entry in the dictionary, generate every possible spelling for all of them, and insert them into a look-up table in a fashion similar to what I described for the search engine, keeping track of the means by which that particular spelling is generated.
And that's what I did.
In this image, you can see my LatinExercises project which uses this class_Latin_C#.dll. In action, here is my favorite Latin_LUT. To get these windows up, I first had the cursor on the word 'nautae' in the sentence 'Filium nautae Romani in agris videmus' (we see the son of the sailor in the field) and then pressed the F3 key on my keyboard. The first window to appear is my LUT-Results window, which lists the four different ways in which that particular spelling of the dictionary's word entry 'nauta, -ae' can be reached. The noun is masculine, and there are two singular forms (Genitive and Dative) and two plural forms (Nominative and Vocative). Since they're all different ways to spell the same word, pressing F3 again on any one of these will result in the window on the right which shows us the complete declension along with an Option tab that holds the word's definition. Pressing F1 from the LUT-Results window pops up the last window you see, which gives the user the word's definition (you can see the links underlined at the bottom which the user can navigate along through) as well as two comboboxes which will generate the declension(s) for nouns and adjectives or the several dozen conjugations for verbs.
There Are Trees and Then There Are Sub-Trees
I've included here the LUT's search tree user-defined-type as well as the Linked-List's UDT because they're a bit particular.
public struct udtLUTRecord_Bin
{
public int deaccentLeft;
public int deaccentRight;
public string strDeaccentWord;
public int left;
public int right;
public string strWord;
public int LL;
public bool flag;
}
public struct udtLUTRecord_LL
{
public string filename;
public int next;
public classLatin_C.classLatin_C.enuTypeSolutions typeSolution;
public classLatin_C.classLatin_C.enuCase case_;
public classLatin_C.classLatin_C.enuPerson person;
public classLatin_C.classLatin_C.enuNumber number;
}
The Latin language uses short and long vowels. These are differentiated in the beginner Latin-Reader textbooks using a 'macron' which is a bar that goes over the long characters. Since many forms of any given word may have several variations of macrons here and there, and the difference between one macron spelling and another may alter the phrase altogether, keeping these in order is kind of important. So the search through the LUT's binary tree first uses the 'deaccented' word (word with the macrons removed) until the correct spelling is found. Then, at this point, there is another sub-tree tied to each node of the binary tree, and this 'sub-tree' keeps the macrons (described using accented vowel characters), and a search is made for that particular macron configuration. In showing the results on the LUT-Results form, this sub-tree is traversed in order, and each node of the sub-tree has its own linked list of solutions which are put to the screen.
I think I've gone on long enough about this project; as it is of little use to anyone but myself, I was reluctant to write an article about it (especially since I can't offer you the code or the database because I don't know the copyright for the dictionary I've typed into my computer, and the LUT files themselves are 1GB in size decompressed), but this way, you got a textbox, and if you were having trouble sleeping, this should have done the trick.
En Francais?
When this worked out so well, I went ahead and did the same thing in French and English. French was much easier than Latin for me, because I actually speak the language and found the Bescherelle the best French-cookbook I could find. So aside from the pronominal verbs and the passive forms, my French dictionary (entirely French and 1600 pages long!) has been turned into a French LUT. There's this French chick whom I think might be interested in seeing that one. I did the English one (yes, I have a lot of time on my hands), and now I have all three together in a separate project which uses the clipboard to take commands while I write in whatever application or on the Internet using my computer.
Clipboard Commands
Right now, if I highlight and 'copy' the word 'enabledictionary' using the CTRL-C combination on my keyboard, then whatever I copy to the clipboard becomes a word I've asked this application to look up. It is like I'm saying: give me the definition for this word. But all I've done is copy it to the clipboard. This slows my system down slightly, because it tests the clipboard every second of the day, but I do a lot of writing and I can always say 'killdictionary' whenever I choose. My three LUTs are in there, and I have a selection of several dictionaries to choose from, so given my penchant for writing, it has become a powerful tool which I use quite often.
My latest typing project is a rhyming dictionary, but I won't bother you with that.
History
- 24th November, 2009: Initial version
Christ Kennedy grew up in the suburbs of Montreal and is a bilingual Quebecois with a bachelor’s degree in computer engineering from McGill University. He is unemployable and currently living in Moncton, N.B. writing his next novel.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





