Lexicography made easy
You don't need a slide ruler to spell, nor do you need to know what a 'lexicographer' is in order to appreciate a good dictionary when you find one. Suppose that you're reading an important document using your web browser, or some code-junkie's ramblings in a CodeProject article, and you need to look up the word "lexicography" because you're wondering if Lex Luther had anything to do with it and if you should therefore be worried. You could reach onto your shelf behind that old box of stale crusty pizza for the pocket dictionary that never had any of Shakespeare's olde English you had trouble with in high-school or, if you have this program up and running, you could select the word with your mouse, right click it, and 'copy'. The GCIDE dictionary you just downloaded would spot the word on Microsoft's clipboard and treat it as a command to search the English-language look-up table and report back to you that lexicography is:
: the art, process, or occupation of making a lexicon or dictionary; the principles which are applied in making dictionaries.
and you'd get a warm fuzzy feeling inside.
GCIDE: GNU Collaborative International Dictionary of English
The authors of GCIDE describe their project as follows:
This electronic dictionary is the starting point for an ongoing project to develop a modern on-line comprehensive encyclopedic dictionary, by the efforts of all individuals willing to help build a large and freely available knowledge base. Contributions of data, time, and effort are requested from any person willing to assist the creation of a comprehensive and organized knowledge base for free access on the internet.
GCIDE Project
Essentially, it's a free online dictionary, with over 123,000 word-entries, available as a collection of 26 XML documents (one for each letter of the alphabet) or a single 64MB XML document (much too large to be kept in RAM!). The site listed above has a 'headword' search which you can use to find words in their dictionary, but I've got one better. Of course, this project could not have existed without the work of those who created the original source XML files and made them available free of charge on their website. So, to them, I owe a debt of thanks.
Downloading the XML Document
As I mentioned above, you can download everything for free. But since the original XML document is 64MB, this application requires you not only to download this file, but then divide its component word-entries into 123742 separate XML documents, then build a look-up table using these files so that the final product can do all the work. The source code attached to this article includes three separate programs:
- Create XML Files
- Build Look-Up Table
- Dictionary
So, when you've downloaded the source code, you'll have to download this file, decompress it, and then save the file 'gcide-entries.xml' (64MB) to the subdirectory: \GCide\GCide_Create_XML_Files\GCide_Create_XML_Files\gcide-entries.xml, and run the 'Create XML Files' program.
You're probably guessing that generating 123000 files takes a long time, and if you are, you're right. But, you don't have to do it all in one shot, you can dispose the feedback form (that'll be the one counting down the number of files left to do), and a message box will appear to confirm that you want to quit. Then, the next time you want to start it up again, it'll ask you if you want to 'continue a previously started rebuild?', you click 'Yes', and it'll continue where you left off. On my laptop, it takes about 15 hours! This is painful to watch, but if you run it overnight, it's not too bad. And, it doesn't prevent you from doing most anything else, so you can just let it run while you're doing whatever, but mind you, it will slow your processor down considerably.
The original document had (has) some non-printable 'print-control' characters which don't always require the same number of bytes in memory (I've been informed by one of the authors that these will soon be corrected), though they only count for one character in the string.Length method. And, this is the reason why it took me a week just to get the look-up table working. It was a pesky problem, and I had trouble figuring it out, but eventually realized that only three or four (or even one!) print-control character in the thousands of files was the cause of all my woes. Since the look-up table is stored in a file-stream, and the file-stream therefore consists of records evenly spaced out at exact locations, they can be easily stored and retrieved in a random-access fashion; however, when a single character takes up one byte too many, that record becomes unreadable, and the whole system crashes.
To identify these problem files and then correct them, I added a 'validWord' function which triggers an alarm. When this alarm goes off, the rebuild LUT stalls with a messagebox asking if you want to try again, presumably after you've either added another acceptable character to the valid-characters string in the testing function, or made the correction in the troubling XML document.

Having discovered these problem word-entries (there were fifteen entries with errors), I corrected the XML documents on my computer, then included them in the Create_XML_Files() program so that that program can then copy these corrected files over the erroneous ones it has generated on your computer. That way, you don't have to deal with any of the problems. Just sit back and let it go. When it has finished generating all 123000 files, it will overwrite the 15 files that created problems for the Rebuild Look-Up Table program, and then you'll be ready to hook it up into a searchable look-up table.
Look-Up Table
In a previous CodeProject article titled 'Spell weller, but grammar's up to you', I explain how the look-up table works without giving you any source code because the data involved in the earlier projects mentioned there is too large to be posted on the CodeProject site (>1GB!). But, with this GCIDE dictionary, you can download the source code here and see for yourself how it all works when you run it with the XML file provided on the GCIDE site mentioned earlier. You might want to read that article anyway, but even if you don't, you should be able to get the general idea from what follows in this article.
The code you've downloaded takes every word entry in the GCIDE dictionary, generates all of their alternate spellings, and while retaining how the various word-spellings were generated, enters them into a look-up table where they can be retrieved and displayed for the user later. This look-up table, or LUT, is made up of a binary tree. Each leaf in the tree has a right, left, and next pointer, as well as the word information and the file ID indicating where to find the definition.
The medium used to store this data is a file-stream. Each leaf of the tree is called a record. And, each record in the tree (all recorded in the same file-stream) is exactly the same size. This allows the program to index each record and, using functions like:
classLUT_Bin_Rec loadbinRec(long index)
{
classLUT_Bin_Rec binRecRetVal = new classLUT_Bin_Rec();
fsBin.Position = getBinRecPosition(index);
binRecRetVal.Word = (string)formatter.Deserialize(fsBin);
binRecRetVal.typeWord =
(enuTypeWord)((int)formatter.Deserialize(fsBin));
binRecRetVal.FileID = (string)formatter.Deserialize(fsBin);
binRecRetVal.left = (long)formatter.Deserialize(fsBin);
binRecRetVal.right = (long)formatter.Deserialize(fsBin);
binRecRetVal.next = (long)formatter.Deserialize(fsBin);
return binRecRetVal;
}
and:
void saveBinRec(long index, classLUT_Bin_Rec binRec)
{
fsBin.Position = getBinRecPosition(index);
formatter.Serialize(fsBin, binRec.Word);
formatter.Serialize(fsBin, (int)binRec.typeWord);
formatter.Serialize(fsBin, binRec.FileID);
formatter.Serialize(fsBin, binRec.left);
formatter.Serialize(fsBin, binRec.right);
formatter.Serialize(fsBin, binRec.next);
}
it can quickly and easily save or retrieve any record it needs. Since these records have 'pointers' to the left-child, right-child, or the next-sibling, though the records are listed in the random order they were created (random because the binary-tree requires a non-ordered insertion if it is to remain a balanced tree) and indexed like a one dimensional array, they are linked together into a binary tree where the root of the tree is the first record on the file. And so, a search through the tree is done by traversing it from the root-node down, falling to the 'left-child' when the word we're looking for appears earlier in alphabetical order compared to the word stored in the record it is currently looking at, or the search algorithm will fall to the 'right-child' when the word your user is looking for appears later in alphabetical order, until it either reaches a null pointer (-1 in implementation, since they're really long integer indices of the records we're looking for) there where the word it's seeking should be, or quits when it finds what it's after.
The 'next-sibling' indices are used for word spellings that have multiple sources. For example, the word 'runs' appears three times in the GCIDE LUT:
- noun plural
- verb simple present third person singular (to run)
- verb simple present third person singular (to cause to run, e.g., run a horse)
All three of these are spelled the same, and are sourced from three different word entries, one of which is a noun and the other two are verbs.
You can see in the example above that the word 'fascinate' includes the past participle 'fascinated' and the present participle 'fascinating' in its definition. (Also, you may notice that the Greek characters in the etymology are still 'non-printable' characters on the computer this screen capture was taken, but since they don't appear between word morphology or conjugation form tags, they are not used to enter the LUT, and are simply left as they appear in the XML file.)
The file below shows an example of a word entry that was generated by the BuildLUT program by simply adding 'ing' to the word 'bunt'. You can find the rules for these alternate word-spellings and how to generate them in the functions 'getNounSolution()', 'getVerbSolutions()', and 'getAdjectiveSolutions()', which are part of the classEnglish_LUT.cs file.
The word entries in GCIDE don't all have their 'morphologies', and so many of them need to be generated using simple rules of grammar before they can be inserted into the look-up table. This facilitates the searching of words, because you no longer have to try and figure out how a word's heading would appear in a dictionary, which is a great improvement on many other electronic dictionaries which are not always ideal. Also, since the application's input tries to remove common prefixes and suffixes, trying every combination until it either finds something or quits when it's exhausted all possibilities, you can even find nonsense invented words like 'noncredibleness'. The result of that search in the GCIDE LUT is 'non + CREDIBLENESS', which appears as the definition of 'credibleness' along with the removed prefix 'non-'.
Running 'build LUT' takes only about four hours on an average laptop, so most home-computers can probably punch it out in less than three.
Your own Dictionary
The classGCide.cs and classEnglish_LUT.cs files can be used as DLLs in other projects, or you can compile the Dictionary Application which comes with the source code in this article. Once you've downloaded the original XML document, created the 123K-files, and built your look-up table (LUT), you'll want to use the dictionary application which has a couple of handy features.
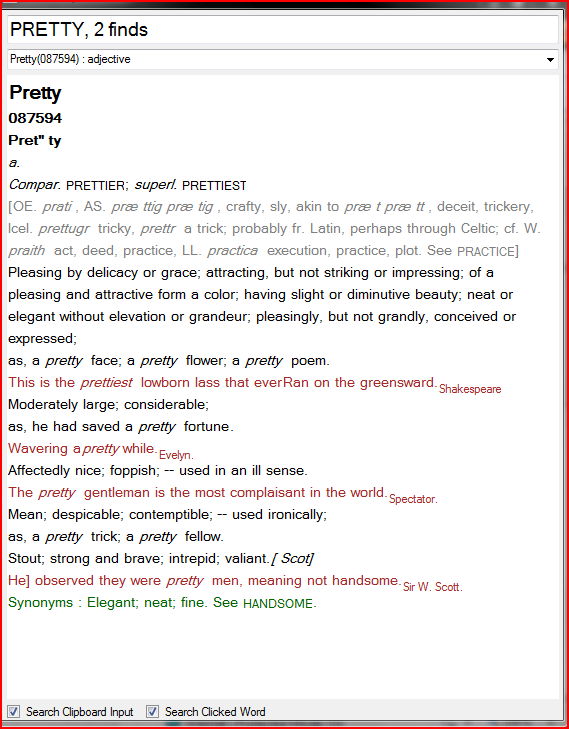
But first, let me tell you about the output screen. You're looking at a bitmap. So, if you like richtextboxes, you'll have something to play around with when you look at this output. Richtextboxes annoy me. So, I built a class called classGraphicText which can still grow in terms of flexibility, but after only a couple of weeks on this project and maybe two days on the graphic text business, it's already pretty good.
Graphic Text
This class takes strings of text and creates an array of classWordImage elements. Each of which has text, font, color, a bitmap, and a position relative to the previous element in the array. Then, given a requisite image width, the function:
public Bitmap putImageArrayOntoBitmap(int intWidth,
classWordImage[] udrWordArray)
puts that array of word images side-by-side, or new-line when required, together onto a single bitmap which it returns to the calling function. There is a convenient output form which is ready to use in the class, which has its own vertical scrollbar to control the position of the bitmap when you want to scroll down the text. It also reacts to any size changes so that the output bitmap is regenerated to fit the new size.
Here's an example:
And below, you'll see what happens when we take the first image above and reduce the form's width. The form's sizechange event handler calls classGraphicText's putImageArrayOntoBitmap() function for its new size, and the images (words) are moved around to fit into the bitmap following rules similar to 'word-wrap's that virtually every word-processor or text-editor uses:
should you ever need to make room for something else on your screen.
Picture Another Bin-tree
Since drawing all those separate bitmaps for each word of each result your user finds is a bit slow, I created a binary-tree of previously created word entries, and scan these before generating any new bitmaps. When the word, spelled exactly the same, including the punctuations trailing it, with the exact same font, size, and color, is not in the binary tree, then the one the program is about to create is stored in the tree and referenced for later. And, when the image you're looking for is already there, then that word's classWordImage element's bitmap field pointer points to the bitmap in the element which stays in the WordImage binary tree.
The binary tree can be found in the classGraphicText's
public bool WordSetInBinTree(ref classWordImage wordImage)
function.
Extras
Have another look at the pretty picture above. You'll notice two check boxes at the bottom of the dictionary's form. The first one on the left lets you use the dictionary from any other application, either your web-browser or word-processor; simply highlight the word you want to look-up, then punch the keys Ctrl-C or Ctrl-X, and when the word appears in Windows' clipboard, the dictionary will treat it like a search command as if you had typed the word in the text box on the top of the form and pressed Enter.
The second check-box lets you click on the bitmap and have whatever word you clicked defined. This is done through the use of classGraphicText.Panel_GraphicText's function:
public classWordImage getWordUnderMouse()
and is called when the mouse_click event is handled.
As a bonus, you can play a game. Without using the keyboard, but only the mouse, try to click your way from 'zebra' to 'aardvark'. It'll take you hours!
Updated Version
There is a third checkbox now with this new updated version of the GCIDE Dictionary which reads 'Popup Mouse Hover DEfinition'.
When this is checked, any word beneath your mouse cursor, when you let it hover, will have its own pop-up definition appear. A list box will appear beneath the mouse cursor and in front of the word, and beside it, a popup form with that word's definition. The mouse-wheel allows you to scroll over the pop-up definition, and you can also move the mouse down to any of the other entries listed in the list-box should the word you're looking at has several sources for that particular spelling.
Code Comments
I've added a few comments to the code and elaborated more where I thought explanation was needed, but in many cases, the name of the function seemed enough to call it self-explanatory, so you shouldn't have any problem using the classes.
Christ Kennedy grew up in the suburbs of Montreal and is a bilingual Quebecois with a bachelor’s degree in computer engineering from McGill University. He is unemployable and currently living in Moncton, N.B. writing his next novel.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 Regards.
Regards.
