Introduction
Functional programming is
getting more and more interest nowadays, as the silver bullet solving
all of the problems of humanity; the knife which can partition
complexity into thin, manageable slices; the prophet who can show us
the way out of the Kingdom of Nouns. Unfortunately, the
proponents of Functional Programming usually only talk about the
advantages of this paradigm, without concrete examples how it can be
applied to real life problems. This article is an attempt to convince
you that it is worth considering, especially when writing
multi-threaded code.
If you are wondering what
this FP is all about, it can be reassuring that you are already
actively practicing it whenever you write LINQ queries. Not too many
people disputes that LINQ is powerful, completely general and very
easy to use. This power comes from the fact that there are general
functions in the System.Linq namespace which can be tailored to the
exact problem we are solving by passing in problem specific
functions. With the elegant lambda notation of C# we can write very
powerful algorithms, while still keeping the code succinct and easy
to read. This similarity between LINQ and FP is not too surprising
however, as LINQ's extension methods are very old functions from FP
languages in disguise: Select is map(), Aggregate is reduce(), the
map/reduce algorithm probably sounds familiar to you.
Functional Programming basics
In this article we will
use only the subset of Functional Programming, if you are interested
how you can emulate most of the machinery which exist in FP
languages, you can read this excellent article from Jovan Popovic:
Functional programming in C#. There are two properties we are
about to use from FP, pure functions and higher order
functions. The latter is explained in the linked article, we are
talking about functions taking other functions as parameters (or
returning them as results). We will write generic algorithms
expressed as these higher order functions, and will turn them into
specific program code by using lambdas. Just like LINQ does.
Pure functions on the
other hand are functions which always return the same result for the
same parameters and have no side effects. The latter means that they
cannot modify any state nor using any I/O, as that would be a side
effect. (As we are not in the race for purity, we can break the no
side effects rule for logging, but only for logging!) Pure functions
are interesting for us since they have some very useful attributes
(called referential transparency):
As they depend only
on the input parameters, they are usually easier to understand and
easier to reason about. You do not have to check every method which
can modify the object's state, everything is in front of you
whenever you look at the source code of the function.
They are trivial to
test, you just pass in some values and compare the result to the
expected one. If you pass in just values, there is no need to create
fakes at all, you do not have to write “extracted” classes
either.
We can easily compose
pure functions as the evaluation of those functions cannot interfere
with each other. Compare this to the experience what you get when
you call a simple function in an Object Oriented Programming style:
after the call, every object you hold a reference to, can
potentially be altered.
If two pure functions
do not depend on each other, so the result of one is not used as a
parameter of the other, then we can evaluate them in any order. We
can even execute them on different threads without locking as they
cannot interfere with each other.
Since we do not
mutate object state (every field in every class is readonly),
state is built from constant (immutable) values, which can be shared
between multiple threads without any synchronization.
All the above sounds very
convincing, however there is a small problem with pure functions is
that they are good only for heating the room. Once we calculate some
expression we have to throw away the result, since by definition we
cannot store it anywhere, effectively wasting all the work done by
the CPU, other than the heat it generated. Remember, pure functions
have no side effects, we cannot write the result to an I/O device or
store it in some variable! As the world is full of state, and our
programs must model and handle that state, obviously every FP
language developed some method coping with that. Haskell has
pure functions and monads, which are little bags where all the
non-pure garbage (like I/O) is stored. Clojure has pure
functions and ref, which is a Software Transactional Memory
implementation, which can hold multiple versions of values. Non-pure
languages such as C# can mix and match pure and non-pure functions,
and it is the responsibility of the developer to make sure that
pureness and immutability constraints are not violated. In this
article we will do exactly that, by separating state representing
immutable objects, state processing pure functions and state holding
mutable infrastructure.
The problem
In order not to fall into
the same trap as Functional Programming proponents usually do, the
problem we will solve will not be an exclusively mathematical one but
will have some twist. Everybody seems to be sick of factorials and
such so here is some real world task. Imagine that we are running our
pension fund and need real time data about the current value of our
stock portfolio so we can compare it to the price of the current
value of our gold pile under the bed, so we can decide whether to buy
more gold or buy more stocks. The twist is that we want to run this
price calculating algorithm within soft real-time time constraints to
beat High Frequency Traders, which means that we cannot
allocate too much memory for processing as it implies too much
garbage collections. Garbage collections are considered bad things in
soft real-time algorithms, as everybody hates if somebody else
interrupts them during speech, you know what I mean.
As we are working with
pure functions, and since pure functions cannot modify state, they
have to create a new state. In order to avoid memory allocations, we
will use value types to represent the state.
The value of our stock can
be calculated by using the following very simple expression:
value :=
SUM(stock_price[i] * number_of_stock[i] * currency_exchange_rate[i])
The value of the gold is
the same, we can assume a stock portfolio which has only one stock,
the gold, and the stock price is the current gold price.
The problem is that we can
have thousands of stocks in our portfolio and we have to recalculate
this formula a million times per second in order to beat the HFT
guys. We can reorder the expression, grouping by currencies like
this:
value :=
SUM(SUM(stock_price[i] * number_of_stock[i]) *
currency_exchange_rate[j])
That way we only have to
recalculate one multiplication when the currency rate changes but we
still have to add up all the numbers. If we think about the SUM
function, we can notice that because addition is associative, the
following is true:
a1+a2+a3 = (a1+a2)+a3
So if only a3 changes, and
we somehow would remember what was the sum of a1+a2, then we would
have to do only one addition instead of two. For 10000 values, it
would mean doing one addition instead of 9999 and it is a huge
difference. We can get a1+a2 by subtracting the old a3 value from the
old sum, but it will result in worse and worse result quality as the
rounding errors accumulate. It will not be generic enough either, as
we will be able to use only functions which have inverse functions as
well (like the subtraction is an inverse of addition).
The solution in Functional
Programming is called Memoization, which is a way to remember
the result of a function call, so when we call it next time with the
same parameters, the result does not have to be recalculated, we can
use the memoized one. Of course it can consume a lot of memory to
remember everything, and it is also slower than adding two numbers
together, so we will develop a simpler but faster version of it. This
will be the infrastructure which will enable us to incrementally
calculate anything, and will store and cache the results for us.
The solution
In order to be able to
cache the last value of a sum, we will arrange every function into a
tree hierarchy like an Abstract Syntax Tree. In case of a sum,
we arrange like this:
a1+a2+a3+a4 = ( (a1+a2) +
(a3+a4) )
Once we do not have to
distinguish between simple operators like multiplication and list
operations like SUM(), the whole problem is simplified to caching and
updating. The following pictures show how the system works.

Here you can see how we
group (A+B)*(C+D), but we would group and handle A+B+C+D exactly the
same way, only the result would be 50 instead of 400. A, B, C and D
are Sources of the calculation as they provide values. A+B, C+D and
(A+B)*(C+D) are Dependents of the sources above them but also Sources
for the Dependents below them.

It easy to see that if we
change one Source value (C from 11 to 1 in this case, shown with
yellow), then we have to recalculate all Dependents. The number of
calculations is the depth of the tree, so in the worst case, when
every node has only two Sources, it will be log2(n). In our problem
it means that in case of 10000 stocks, it will be 14 additions
instead of 9999.

Every node in the tree
maintains a Ready and a Cached flag, and it is very important not to
mix these two states together. Ready means that the value of the
calculation can be read from the node to be given as parameters to
further calculations (which are pure functions themselves). In the
graph Ready is shown as green. Cached means that we do not have to
evaluate the calculation as we hold the last value. In the graph
Cached is shown as a concrete value instead of question marks. Cached
implies Ready, but Ready does not imply Cached!!!
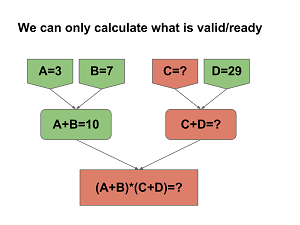
In case of Sources, Ready
means that the value they hold are valid. They can became not Ready
only when we store an invalid value into them, like null. Not Ready
is shown as red. Note that Ready is transitive, so if something is
Ready, then it implies that all the Sources of the calculations are
Ready, otherwise we could not calculate the value which would mean
not Ready. In order to keep this invariant, when we make something
not Ready then we have to make every Dependents not Ready. We stop
only if we either reach the bottom of the tree, so there are no more
Dependents, or when we encounter a node which is not Ready. In the
latter case as Ready is already transitive, we can be sure that all
of its Dependents are already not Ready. As you can see on the graph,
all not Ready states imply not Cached, holding question marks.

Unlike as the second,
gray/yellow graph suggested, when we change one Source, we do not
have to recalculate everything until we reach the bottom, as it would
exercise wasted calculations in case we would like to change several
Sources simultaneously. So when we change B from 7 to 2 in this case,
we just invalidate all Dependents (A+B becomes not Cached and
(A+B)*(C+D) is already not Cached). We recalculate the value only
when we access the value of (A+B)*(C+D), which in this case will
throw an exception as it is not Ready. If it would be Ready, then
accessing the value would recalculate and cache the values of A+B and
C+D, then by using those values would recalculate and cache the value
of (A+B)*(C+D).
So in the end we flow
Ready/not Ready changes and Cached invalidation from top to bottom,
and recalculate and cache values from bottom to top recursively.
The code
We define three minimal
interfaces to capture the design we just described.
interface ISource {
bool IsReady { get; }
void AddDependent(IDependent dependency, int key);
}
interface IValue<T> : ISource {
T Value { get; }
}
interface IDependent {
void Notify(int readyChange, int key);
}
const int BecomeNotReady = -1;
const int ValueChanged = 0;
const int BecomeReady = +1; ISource is implemented by
every node which wants to be a Source in the graph. IsReady is the
Ready state we talked about, AddDependent is used when building the
graph. Since we do not want to change the graph once we have built
it, there is no RemoveDependent here. Key is just a number
ISource
remembers, so when it calls
Notify later, it can pass this value as
the second parameter. The use case is when we put a lot of
ISource
references into an array, we can use this number as the index in the
Notify callback.
IValue<T> is the typed
version of ISource, Value recalculates the value of the node, or
gives back the cached one. In case the IValue is not IsReady then it
throws an exception.
IDependent is implemented
by every node which wants to be a Dependent in the graph. Notify is
called every time IsReady changes in one of the ISources, or when the
value changes and this node must be invalidated. The constant numbers
-1, 0 and +1 are important, as we do not check every ISource every
time IsReady is called, we just keep an always up-to-date count of
the not IsReady ones, so those constant values can be used to
directly modify the counter. When the counter reaches 0, it means
that the node became IsReady, otherwise it is not IsReady.
Now lets implement all the
nodes in the graphs by implementing these interfaces. First the top
row, which are the Source values, the root of all calculations.
public class Source<T> : IValue<T> {
protected bool _isValid;
protected T _value;
protected DependentList _dependentList;
public Source() {
_isValid = false; _value = default(T);
_dependentList = new DependentList();
}
bool ISource.IsReady { get { return _isValid; } }
void ISource.AddDependent(IDependent dependency, int key) { ... }
public bool IsValid { get { return _isValid; } }
...
public T Value {
get { if (!_isValid) throw new Exception(); return _value; }
set {
if (!_isValid) {
_value = value; _isValid = true;
_dependentList.NotifyAll(DependentList.BecomeReady);
} else {
_value = value;
_dependentList.NotifyAll(DependentList.ValueChanged);
}
}
}
public void Invalidate() { ... }
}In case of a Source<T>,
IsReady is the same as IsValid. Reading Value does not involve
recalculating and caching anything, as it is just a stored instance
of T, whatever it is. Implementing AddDependent and Invalidate is
trivial, not shown here. Note however the NotifyAll calls in the
Value setter, which will call all the Notify handlers stored in
DependentList in a list of IDependents. In case we just changed to
!_isValid to _isValid, it uses BecomeReady for the notification,
otherwise it uses ValueChanged. In the case of Invalidate, it uses
BecomeNotReady as expected.
There is also a
SourceValue<T> and a Constant<T> in the real code base,
the former notifies Dependents only when the value not only set but
also different from the prior value, while the latter is a constant,
which is always IsReady.
The next things are the
lower nodes in the graph, first creating Dependent, which handles
notifications correctly, then the function nodes will come.
public abstract class Dependent : IDependent, ISource {
protected int _notReadyCount;
protected bool _isCached;
protected readonly DependentList _dependentList;
protected Dependent(params ISource[] sourceList)
{
_notReadyCount = 0; _isCached = false;
_dependentList = new DependentList();
for (int i = 0; i < sourceList.Length; ++i) {
sourceList[i].AddDependent(this, i);
if (!sourceList[i].IsReady) ++_notReadyCount;
}
}
bool ISource.IsReady { get { return _notReadyCount == 0; } }
void IDependent.Notify(int readyChange, int key) {
var oldReady = _notReadyCount == 0;
_notReadyCount -= readyChange;
var newReady = _notReadyCount == 0;
if (oldReady != newReady) {
_isCached = false;
_dependentList.NotifyAll(newReady ? DependentList.BecomeReady : DependentList.BecomeNotReady);
} else if (_isCached) {
_isCached = false;
_dependentList.NotifyAll(DependentList.ValueChanged);
}
}
}
In the constructor we add
ourselves as an IDependent to all ISource nodes, and make the
invariant true, so that _notReadyCount is always equal with the count
of the not IsReady ISource nodes. We keep this invariant true by the
line: _notReadyCount -= readyChange; later.
The node is considered
IsReady if and only if _notReadyCount == 0, which is trivial.
The Notify call simply
forwards the state change, if IsReady changed then BecomeReady or
BecomeNotReady (both imply ValueChanged), otherwise just
ValueChanged
which invalidates the cached value in Dependents. Of course, it we
was not Cached then there is no point forwarding the
ValueChanged as
our Dependents cannot be Cached either.
public abstract class FunctionBase<R> : Dependent, IValue<R> {
protected R _cachedValue;
protected abstract void UpdateCached();
public R Value {
get {
if (base._isCached)
return _cachedValue;
UpdateCached();
base._isCached = true;
base._dependentList.NotifyAll(DependentList.ValueChanged);
return _cachedValue;
}
}
}
FunctionBase<R>
simply caches the result of a calculation, and if the value is cached
then it does not update it by calling UpdateCached(). Note that it
uses the inherited _isCached field from Dependent, as the base class
sets the field to false in Notify, while FunctionBase sets it to true
in the Value getter.
public sealed class Function<T1, T2, R> : FunctionBase<R> {
IValue<T1> _param1;
IValue<T2> _param2;
Func<T1, T2, R> _func;
public Function(IValue<T1> param1, IValue<T2> param2,
Func<T1, T2, R> pureFunction) : base(param1, param2) {
_param1 = param1; _param2 = param2; _func = pureFunction;
}
protected override void UpdateCached() {
base._cachedValue = _func(_param1.Value, _param2.Value);
}
}
Function<T1, T2, R>
finally calculates the pure function f(T1,T2) -> R which is passed
to it in the constructor and stored in _func. Of course we have to
implement one such class for every arity (number of function
arguments).
static IValue<T> RecurseApply<T>(IList<IValue<T>> sourceList, Func<T, T, T> associativeFunction, int startIndex, int length)
{
if (length == 1)
return sourceList[startIndex];
int newlen1 = length / 2;
int newstart2 = startIndex + newlen1;
int newlen2 = length - newlen1;
return new Function<T, T, T>(
RecurseApply(sourceList, associativeFunction, startIndex, newlen1),
RecurseApply(sourceList, associativeFunction, newstart2, newlen2),
associativeFunction);
}
public static IValue<T> Apply<T>(IList<IValue<T>> sourceList, Func<T, T, T> associativeFunction)
{
return RecurseApply(sourceList, associativeFunction, 0, sourceList.Count);
}
Finally this is the magic
which turns the SUM() function into a tree. All it expects is the
list we want to operate on (the numbers we want to add up), and the
function which must be associative, and addition clearly is. Note
that we do not have to use mathematical operations here, any function
will do as long as it is associative, like string concatenation.
That is it, we have
finished creating the state holding mutable infrastructure, the next
step is putting it to good use by writing state representing
immutable objects and state processing pure functions.
Usage
First we have to define a
value type which holds the price of stocks. Unfortunately stocks have
more than one prices, so a double will not suffice, we have to create
a struct called Price. The reason to keep both prices is that when we
want to sell stocks, we get only the lower BuyPrice, and when we want
to buy stocks, we have to pay the higher SellPrice. Of course having
two prices is also a good excuse to introduce immutable value types into
this article.
public struct Price
{
public readonly double BuyPrice;
public readonly double SellPrice;
public Price(double buyPrice, double sellPrice)
{
BuyPrice = buyPrice;
SellPrice = sellPrice;
}
public static Price operator +(Price a, Price b)
{
return new Price(a.BuyPrice + b.BuyPrice, a.SellPrice + b.SellPrice);
}
public static Price operator *(Price a, double b)
{
return new Price(a.BuyPrice * b, a.SellPrice * b);
}
}
As you can see, we also
define addition and multiplication operators so the next piece of
code will look like a little bit better.
public class Portfolio : Model
{
readonly Dictionary<string, Source<Price>> _stocks;
readonly Dictionary<string, Source<double>> _rates;
public readonly IValue<Price> Result;
public Portfolio(IEnumerable<Tuple<string, int, string>> stocklist)
{
_stocks = new Dictionary<string, Source<Price>>();
_rates = new Dictionary<string, Source<double>>();
var totallist = new List<IValue<Price>>();
foreach (var stockDataGroup in stocklist.GroupBy(x => x.Item3)) {
_rates.Add(stockDataGroup.Key, Source<double>());
var addlist = new List<IValue<Price>>();
foreach (var stockData in stockDataGroup) {
var stockID = stockData.Item1;
var stockNum = stockData.Item2;
var currencyID = stockData.Item3;
_stocks.Add(stockID, Source<Price>());
var stockValueInCurrency = Function(
_stocks[stockID], Constant(stockNum), (stock, num) => stock * num);
addlist.Add(stockValueInCurrency);
}
var sumInCurrency = Apply(addlist, (p1, p2) => p1 + p2);
var stockSumInEUR = Function(
sumInCurrency, _rates[stockDataGroup.Key], (sum, curr) => sum * curr);
totallist.Add(stockSumInEUR);
}
Result = Apply(totallist, (p1, p2) => p1 + p2);
}
}
This is the class which
holds the complete expression we want to incrementally calculate. We
derive from Model, which is a simple utility class containing
wrappers around the constructors of Function, Source and similar
things, just like Tuple.Create wraps the Tuple constructor. The
reason of this is that type inference does not work in case of
constructors, and without wrappers we would always had to use
new
Function<Price, int>(...)
instead of simply writing
Function(...).
Looking at the code from
the inside to the outside, we first define stockValueInCurrency,
which is a simple multiplication we have just defined. We add those
together by Applying addition into sumInCurrency, then multiply by
the currency rate into stockSumInEUR. Finally we add all of them
together by Applying addition again into Result. Note that in this
constructor we do not calculate the value of the portfolio, just
build a graph which will do that when we read Result.Value.
There is one interesting
thing is that we use Constant to capture the value of stockNum. It is
used here only for completeness, we can use its value directly in the
lambda we pass to Function(), and in that case the C# compiler
automatically allocates a closure object to hold it. If we do not
capture any value in the lambda then the C# compiler will use a
single static instance of the lambda, which one you prefer should
depend only on your taste.
public void UpdateStockPrice(string stockID, Price price)
{
_stocks[stockID].Value = price;
}
public void UpdateCurrencyRate(string currencyID, double rate)
{
_rates[currencyID].Value = rate;
}
The remaining two methods
simply update the Source values which will force the graph to
invalidate itself so next time we read Result.Value, it will be
recalculated.
class Program
{
static void Main(string[] args)
{
var p = new Portfolio(new[] {
Tuple.Create("VOD LN", 100, "GBP"),
Tuple.Create("BP LN", 1000, "GBP"),
Tuple.Create("BMW GY", 200, "EUR"),
});
p.UpdateCurrencyRate("EUR", 1.0);
p.UpdateCurrencyRate("GBP", 1.3);
p.UpdateStockPrice("VOD LN", new Price(60.0, 61.0));
p.UpdateStockPrice("BP LN", new Price(55.1, 55.2));
p.UpdateStockPrice("BMW GY", new Price(155.1, 155.2));
if (p.Result.IsReady) {
Console.WriteLine(p.Result.Value.BuyPrice);
Console.WriteLine(p.Result.Value.SellPrice);
} else {
Console.WriteLine("NOT READY");
}
}
}
The remaining code is very
straightforward. If we remove any of the p.Update... function calls,
we will see that the expression value is NOT READY.
Final words
Now if we would profile
this application by updating big portfolios millions of times, we
would notice that the majority of the time is spent in NotifyAll in a
foreach loop. So in the real library code we have EmptyDependentList,
SingleDependentList and MultiDependentList, which are optimized for
0, 1 and more elements. With this optimization we can process 3
million updates per second per core, which is considered good enough
for our little pension fund. If it is not fast enough, we can reduce the
tree depth and the number of Dependents by having 16 or 32 element
fat nodes, and then we cache the result of the function applied to all
elements in a loop. That way we would evaluate the pure functions 4-6
times more but overall it could still result in speed gains. Another
possibility is to process the expression on multiple threads
simultaneously, but of course in our simple <code><code><code><code>Portfolio model, thread
synchronization would eat all the speed-ups. It can be considered for
other algorithms though. Note that all of these optimization
possibilities exist only because we decoupled storing data from
calculating it using only pure functions, and as we know, pure
functions can be evaluated in any order.
If we look at the
constructor of Portfolio, we can wonder how can we call it Functional
Programming when everything we do is modifying the state of the
object we are constructing? Another thing that can be strange is that
everything in Source, Dependent and FunctionBase is good old Object
Oriented Programming...
Do you remember the
title of the article? It is Almost functional programming.
In the next part we will create a server to execute our little
financial model, and we will discover what exactly the word Almost
means in this context. We will also rewrite that imperative constructor and see if
the result will become worse or better.
Download StockTest.zip
I am a senior software developer with almost 20 years of experience. I have extensive knowledge of C#, C++ and Assembly languages, working mainly on Windows and embedded systems. Outside of work I am interested in a wider variety of technologies, including learning 20 programming languages, developing Linux kernel drivers or advocating Functional Programming recently.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






