Introduction
A while back, I was looking for a data structure that could store strings quickly and retrieve them very quickly. I stumbled upon the Patricia (PAT) trie ("Practical Algorithm To Retrieve Information Coded in Alphanumeric"). Unfortunately, I could not find a good enough explanation of the trie. Every explanation I read, glossed over too many details. Every code piece (there are not many) that I could find had very nice implementations, but did not store text only numbers. So, I wrote my own class that stores text.
If you want to store a good amount of unique text strings (duplicates can be handled, just not by the class itself), retrieve them super fast, and associate data or functions with them, then read on!
This class could be used for (as examples, but not limited to):
- command lists (like menus or OSI(7) protocols)
- a dictionary or thesaurus
- associative arrays
- catalogue ports on a TCP server
- store/parse XML
Not bad, huh?
Patricia Trie
I would like to give a brief overview of what a trie is and then speak about PAT tries more specifically. It is assumed you understand how a binary tree works.
A trie is a binary tree that uses key space decomposition (as opposed to object space decomposition). The idea is that instead of branching left or right based on what data value happens to be at a particular node in the tree (that is not a mistake, tries are trees), we branch based on predefined key values. So the root node of a tree could send the first thirteen letters of the alphabet to the left child while the others go to the right. This does not guarantee a balanced tree, but it helps to keep the tree balanced and ensures that the order in which data is input will not affect the performance of the data structure (i.e., insert a sorted list into a binary tree and end up with a list).
In a PAT trie, all of the internal nodes (a node with at least one child) hold only enough information to make branching decisions (go left or right), but no actual data. The leaves of the trie (a node with no children) hold the data: a key and a link to one class (that holds whatever we need it to).
My PAT trie uses integers (on a 32-bit machine) for keys. If you want to use a long for the key, then you must change the type of the key (keyType). If you change the type of the key or you compile this class on a machine that encodes integers (int) with more than 32 bits, then you must set the constant MAX_KEY_BITS to the number of bits that your data type is wide (default is 32). We will see later how to convert text to integers.
With PAT tries, at every level of the trie, we evaluate one bit of the key, and based on that bit, move left or right. To find any key in our trie, we only have to check at most the number of bits that our key is wide (32 bits).
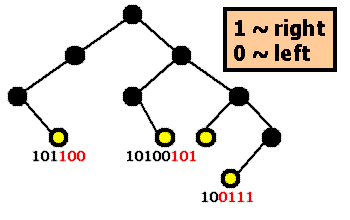
The image above shows a PAT trie that stores a few keys (binary representation shown). The black circles are internal nodes. The yellow circles are leaf nodes.
Text To Number
Now, we turn our attention to making this a useful PAT trie. We need a way to turn a string of text into our key. All of the three methods described below are based on the fact that Unicode or ASCII characters are really just numbers. The character 'a' is also 97.
The first method involves converting all of our characters into 8-bit numbers (a byte) and concatenating them. There are only 26 letters in the alphabet; we can represent them with a byte. This is not a very good solution, because we could only discriminate against four letters (4 letters * 8 bits = 32 bits). Also, most of the branching would be on the same characters (eight bits to store an ASCII character, eight identical internal node checks).
The second method allows us to store more letters in our key. We could add our characters ('a' + 'e' + ... = 4532). In this way, with the largest ASCII character being no more than 255 (2^8-1) or in Unicode 65535 (2^16-1), we could have our key encode many numbers and we would not be wasting space on comparing eight internal nodes for one character. This method has one fatal flaw: encoding "was" or "saw" we will get the same number (3 + 5 = 5 + 3).
The last method uses a Huffman code. Huffman codes are primarily used for compression. They encode letters in a new format using the least amount of bits possible by assigning the least number of bits to the most frequent character. So, if 'e' is the most common letter in a document, then we will represent 'e' with a zero (or just one bit). We would represent the next most frequent letter with a one and the third most frequent with a two. In this way, the Huffman code saves the most space of the three methods, by replacing the most frequent letter with the smallest representation.
Please note that with any of these three methods, there is no guarantee that the generated key will be unique. If all of the letters are identical until the point where our key is full (we have represented as many characters as possible), then we will have generated the same key for two distinct strings ("a baby ate the fox" and "the baby ate the fox" will translate to the same key). To ease this issue, use a key with greater than 32 bits. With a 32 bit key, we can represent at most 32 characters (provided those characters can be represented by one bit ~ 32 e's or t's).
Huffman Is Our Man
The Huffman code used in my PAT trie is an array of twenty-six numbers. The first cell holds the Huffman code for the letter 'a', the next cell for 'b', and so on. The code stored in each cell is the reduced bit representation of the corresponding letter. For instance, the fifth cell is for 'e' and holds the number zero. 'e' is the most frequent letter in the English alphabet and so should map to the smallest number. To build our key:
- for each letter right to left (is there more variability at the end of words?)
- look up the Huffman code for the letter (we will refer to as "Huffing")
- shift the bits on the key to the left for the number of bits that the Huffman code is long (make space to add the code to the key)
- add (arithmetic) the new Huffman code to the key
To better explain the last three steps, here is an example:
- 'l' huffs to 8 or 1000 (in binary)
- the key 0000 0000 0000 0000 0101 1101 0110 0011, becomes 0000 0000 0000 0101 1101 0110 0011 0000
- we can add 8 to the key to get 0000 0000 0000 0101 1101 0110 0011 1000
How was the decision made that the letter 'e' is the most frequent and 'z' is the twenty-third most frequent? Initially, I wrote a program to mill through text and produce a list of the most frequent letters in the English alphabet. Fortunately, it was brought to my attention (by Don Clugston - on Code Project) that there is an official list of the most frequent letters. I should have thought of that... Irregardless, the code has been updated and kudos/thanks to Don! The change will improve the speed of the code. Note that if you use this class to store command lists or some type of structured document where the same words are being used over and over, it pays to rearrange the frequency to match the most frequently used letters. If you were storing C programming code, then if and while would crop up quite a bit. The most frequent letter should (possibly) be i.
Huffing Again and Again
What if you Huff duplicates? My PAT trie is set up so that you associate an entire class with a key. It will only store a key once, but the class associated with it could remember information about duplicates. For instance, here are three scenarios:
- You could keep a variable to count how many times you found a particular word. Instead of inserting, just search for the key and increment the variable in the associated class.
- You could build a linked-list in the associated class to store the position of the text string in a text document. Then, you would know that the word was stored at positions 45, 64, 134, and 856. Note: this would be down right horrible if you wanted to piece the document back together.
- You could build a linked-list that, instead of storing the position of the string, pointed to the next string in the document (or just stored the next word in text). That would help if you wanted to rebuild the document a little more efficiently later on. You could follow the bread crumbs of each string.
Code Overview
There are three classes that together create my Patricia Trie:
PatriciaTrieC ~ the Patricia trie.
PatriciaNodeC ~ an internal or leaf node in the trie.
ASSOCIATED_CLASS (PayloadC) ~ the associated class, originally PayloadC, but it can be changed by changing the constant ASSOCIATED_CLASS.
The Huffman Code [CODE]
The Huffman code array is a static member of the PatriciaTrieC class. It is initialized once for the class and available for all objects of PatriciaTrieC. If you want to change the values, you will have to go in and tweak the array itself.
char PatriciaTrieC::huffman_code [] =
{
2,
18,
11,
10,
0,
The code that Huffs text to keys will ignore all characters that are not A through Z (case-insensitive). So, the strings "HAPPY" and "H A P P Y" would Huff to the same key. Also note that the character strings should be terminated by the end of string character ('\0' or zero).
do
{
if (txt [txt_count] == END_OF_STRING)
break;
if (txt [txt_count] >= 'a' && txt [txt_count] <= 'z')
txt [txt_count] -= LOWER_TO_UPPER_FACTOR;
if (txt [txt_count] < 'A' || txt [txt_count] > 'Z')
{
txt_count += 1;
continue;
}
.
.
.
Using The Code [CODE]
You can insert, search, and remove a key (or one data element) out of the trie. There is a method BuildKey that you can use to convert text into keys if you wanted to store or find out the exact key signature for a string of text. You can also call Print to print the entire trie (if DEBUG is set) or Clear to wipe the entire trie.
The class associated with every leaf node (where data is stored) is PayloadC. If you want your own class, just change the constant ASSOCIATED_CLASS in the pat.h file to the name of your class.
The included project has a nice little program that loads words from a text file and inserts, searches and then removes them all. Below is a simple example of those three operations (insert, search, remove):
#include "pat.h"
#include <iostream.h>
int main ()
{
PayloadC* p_dyn = new PayloadC ();
PayloadC p_stc;
PayloadC* catch_payload = NULL;
PatriciaTrieC pat;
if (pat.Insert (p_dyn, "HAPPY"))
cout << "inserted HAPPY" << endl;
else
cout << "did not insert HAPPY" << endl;
catch_payload = pat.Search ("HAPPY");
if (pat.Insert (&p_stc, "SAD"))
cout << "inserted SAD" << endl;
else
cout << "did not insert SAD" << endl;
catch_payload = pat.Search ("SAD");
catch_payload = pat.Search ("WHO");
if (!catch_payload)
cout << "WHO does not exist" << endl;
catch_payload = pat.Remove ("HAPPY");
catch_payload = pat.Remove ("SAD");
catch_payload = pat.Remove ("WHO");
return 0;
}
Points of Interest
The word frequency list I used came from here.
Worst-Case Running Times
Insert | O(bc+bc*bc) | where bc is the maximum number of bits for the key (32 bit comparisons to search for the spot to insert, plus for every break you have a full 32 bit comparison for duplication - this could be removed, but then duplicates would automatically create a path 32 bits deep, which is fine, but the extra work is better in the average case) |
Search | O(bc) | where bc is the maximum number of bits for the key (using an int on a 32 bit machine, 32 bit comparisons) |
Delete | O(bc) | where bc is the maximum number of bits for the key |
BuildKey | O(n) | where n is the length of the string |
The PAT trie with a 32 bit key can store (2^32-1) / 2 = 2,147,483,647 words and find any of them in 32 bit comparisons.
History
- version 0.0 [November 9, 2004]
- version 0.1 [December 3, 2004]
- The Huffman encoding code is better optimized based on this.
- No GPL. If you want it, use it. If I goofed and did not remove something, remove it and use it. I am sure I got everything though.
- version 0.2 [December 18, 2004]
- Academic Free License, Version 1.2 applied to source.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 Yeah that would make sense, I agree. Here is the trick, where will you save and how will you save the keys?
Yeah that would make sense, I agree. Here is the trick, where will you save and how will you save the keys? 




 in my implementation I used a static array to map a character to a number, so I dind't have to use the Hufman coding...
in my implementation I used a static array to map a character to a number, so I dind't have to use the Hufman coding...