This is a showcase review for our sponsors at CodeProject. These reviews are intended to provide you with information on products and services that we consider useful and of value to developers.
Expanded SQL Compare API: full support for new SQL Server 2005 database objects
By Andras Belokosztolszki
In SQL Server 2000 the primary database objects were tables, stored procedures, views and functions. In 2005 we have XML schema collections, message types, CLR objects (encapsulated .NET code), partition schemes, and more. The number of object types has more than doubled, and the dependency relations between them have become more complex. In SQL Compare 5.x we support all these new object types and allow their comparison and synchronization.
One of the most complex features of SQL Server 2005 is its support for CLR data types. You can now write stored procedures, functions, triggers using any .NET compliant language, such as C#.The CLR assemblies are stored directly in the database, so stored procedures and data types that depend on a CLR assembly do not depend on anything other than the database, and are persisted completely in a database backup. Restoring such a backup on a different server will make the CLR objects available in the restored database.
The problem arises when you want to modify one of these CLR objects. T-SQL offers the ALTER ASSEMBLY command but it does have some shortcomings. Perhaps the most important restriction is all method signatures must remain the same in the modified assembly. If just a single method signature has changed, then the ALTER ASSEMBLY command will fail. So how can you upgrade an assembly? Simple: you just need to drop all dependent CLR objects (stored procedures, functions, DDL and DML triggers), drop the assembly, re-create the assembly using the new DLL, and then recreate all the CLR objects. Sounds tedious, right? It is, but unfortunately that is still not the end of the story. CLR assemblies may contain user defined types. Rebuilding (i.e. dropping and creating) an assembly requires that such user defined types are dropped before the assembly is dropped. But this is not possible if there are tables that use the user defined data type.
So, what you are left with is a CLR UDT upgrade path that looks something like this:
- drop any tables that use the CLR user defined types
- drop the user defined type
- drop any other dependent CLR objects
- drop the assembly
- recreate the assembly
- …and so on
If the data in your tables is not important, then this might be a viable route for you. This is rarely the case though.
What SQL Compare 5.x does is analyze the CLR assemblies in the two databases that are compared. It intelligently decides whether a simple ALTER ASSEMBLY statement can be used to modify the assembly, or whether the assembly needs to be rebuilt. In the latter case, SQL Compare unbinds the data from tables that depend on a CLR UDT by migrating the data into a set of temporary tables. These temporary tables use the string representation of the UDT. Having done this all the relevant CLR objects are dropped, the CLR assembly rebuilt and, the above CLR objects are rebuilt based on the new CLR assembly. Finally, the data in the temporary tables is converted back to use the new CLR user defined type. By default we assume that the string representation of a CLR UDT is the same in the two versions. This assumption holds in the majority of the cases. However, in the cases where the string representation changes between the different CLR assembly versions, an extra conversion function can be added manually to the migration script.
The nice thing is that all of this is done automatically in SQL Compare 5.x, so if you are using this tool, upgrading to a new version of CLR assembly no longer requires potentially dropping all dependent CLR objects by hand and risking data loss.
There are many other changes and additions to SQL Server 2005 that SQL Compare 5 handles smoothly. XML Schema collections and partition schemes are similar to CLR assemblies from the modification point of view. Once again, SQL Compare can migrate changes by rebuilding all the dependent objects. While defaults in SQL Server 2000 were partially parsed by SQL Server, and ended up in the database in a similar form as they were entered, in 2005 the database management system can completely rewrite defaults, and thus SQL Compare 5 has to compare them at a semantic level.
SQL Data Compare 5 command line: improved code reuse and testing
By David Connell
While working on the SQL Data Compare 5 command line it became apparent that the command line version would have to be able to run comparisons in exactly the same way as the GUI. I have always found in the past that "n" implementations of a given algorithm will, for the same input, result in "n" different answers. James Moore was currently re-writing the SQL Data Compare GUI. He had already abstracted most of the logic dealing with the SQL Data Compare engine into a set of classes. He had tested and verified that this code worked within his environment. It soon became apparent that I could reuse his code and as a result get ahead of the game. The only issue we had to agree was whether we should distribute this code as an assembly, share the source code between us, or copy the source code. We decided to share the source code using our version control software. As a result we decided to implement a three tiered architecture:
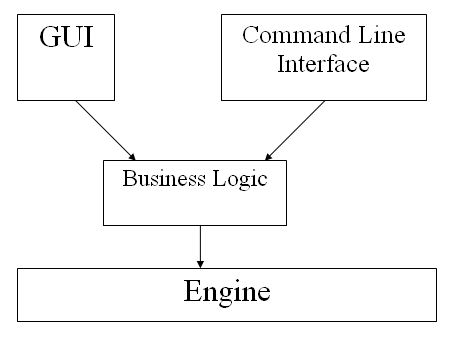
This new business logic layer encapsulates logic that is specific neither to the SQL Data Compare's engine, nor to its GUI. For example, it encapsulated such common SQL Data Compare Engine tasks as:
- Registering Databases
- Setting up mappings
- Replaying the user selections specified in the project files
- Comparing the database
- Exporting the Results
- Creating the Migration SQL
- Executing the generated SQL
From the end user's perspective, these tasks tend to get linked together and then run in one step. The command line may run all these tasks in one go whereas the GUI could run the first four tasks in one step and then subsequent steps individually. These tasks tend to take a significant period of time and so were implemented within Red-Gate's own ICancellable operation and run using our own ProgressDialog box.
NOTE: For some basic examples on how to compare databases please refer to the C#/VB code snippets which are by default installed at C:\Program Files\Red Gate\SQL Bundle 5\Toolkit Sample Files\Automating SQL Data Compare. Also check out the SQL Bundle Help.
Ideally, this business logic would have been extracted and turned into a reusable component (assembly) and made publicly available via our Toolkit API. However, it would have required significant time – time we did not really have –to make this assembly code fully robust (check all the parameters, and so on). This extra effort was not factored into the original timescale of the project and the only way to include it would have been at the expense of other features – hence the decision to internally document this logic and share it at source code level.
So if the end user can't access this logic, what does this new architecture really mean to them? Well, for one the same base code is used to carry out all communication with the Data Engine so it guarantees that the command line and the GUI generate the same results for a given project. However, it does also have an interesting impact on testing.
We use nunit extensively to test our code and for the SQL Data Compare Engine we have hundreds of test scenarios that we use as part of our regression tests. As Helen Joyce explains in her recent Relentless Testing article, there is a lot of manual labor involved in writing these tests and, generally, any test code has to be rewritten to work with any new version of a tool API. For the SQL Data Compare API, this would have normally taken several weeks. However the testers, rather than implementing their own logic to drive the SQL Data Compare engine (which would need to be tested and debugged), were able to reuse our business logic. This saved a significant amount of time and enabled the testers to spend more time testing production code and writing more test cases. So, what you have with SQL Bundle 5 is our most thoroughly and exhaustively tested – and therefore (hopefully) our most reliable and stable – set of tools yet.
A brand new GUI for SQL Compare
By Tom Harris
We began thinking about SQL Bundle 5 almost a year ago now. Although by that time SQL Compare 3 had become the industry standard tool for comparing and synchronizing SQL Server database schema, we felt that there was a whole lot more that we could with it.
Our first step was to take a long hard look at usability of the product. Although we already had some top level technical requirements, we really wanted to meet some of our real users and capture their input. There is nothing more compelling than seeing a real user struggle with your application. We ended up visiting about half a dozen local companies; some were existing users whilst others had never used the products before.
All the usability feedback plus numerous emails and forum posts were fed into the melting pot of the new design. We played around with several prototypes, both in-house and with customers. Here are the motivations behind some parts of the new design
- Project management. Most SQL Compare 3 users were not using projects at all – they simply entered the new server details every time. For SQL Compare 5 we introduced a project manager control to provide a list of most recent comparisons.
- Synchronization direction. The most important thing never to get wrong when using SQL Compare is the synchronization direction. In SQL Compare 3 we had a textual description to guide users. SQL Compare 5 uses the same colored arrows in a consistent fashion across the whole product right from the initial project management control through to the final step of confirming synchronization. This constant reaffirming should ensure that no one accidentally synchronizes in the wrong direction again!
- Improved layout – In SQL Compare 5 we have introduced a very clear idea of left and right for the different data sources. Again this helps with maintaining clarity about which objects are present in which databases.
- Interactive help – this is a nice feature that gives users immediate help about any part of the main screen, invaluable for first time users.
SQL Data Compare engine rewritten from the ground up
By Richard Mitchell
For SQL Data Compare version 5 we decided to address a number of issues that people have been having with our previous versions of the product. One of the earliest decisions we took was to make the data comparison engine rely on our SQL Compare engine to retrieve all of the schema information. This should help our SQL Toolkit users because the skills they have learned for SQL Compare are easily transferable to SQL Data Compare.
Another interesting change is the inclusion of an entirely new way to map the schema of two databases together to work out which tables are comparable. This new mapping system is far more flexible than the old method and can be used to compare and synchronize differently named tables; tables in different schemas or even different tables in the same database. You now don't even have to have a unique or primary key set on the tables; you can select the columns you want to use to compare the tables and we'll use those columns instead.
We have also refactored the entire results store API to cope with a new view of the data required by the UI. This has seen several benefits including all of the results store classes now being included in their own namespace. Also the filtering and sorting support has been improved to allow multiple layers of filters and/or sorts to be applied.
Before the data even gets into the results store you can apply a WHERE clause to the database so if you know you only want to compare and synchronize data after a certain timestamp you can do that.
Other important features to take note of are the improved SQL Variant support and complete collation support.

Redgate makes ingeniously simple software used by 804,745 IT professionals and counting, and is the leading Microsoft SQL Server tools vendor. Our philosophy is to design highly usable, reliable tools which elegantly solve the problems developers and DBAs face every day, and help them adopt database DevOps. As a result, more than 100,000 companies use products in the Redgate SQL Toolbelt, including 91% of those in the Fortune 100.





