I’m going to show you how to set up your Android development environment to use Neon intrinsics. Then, we’ll implement an Android application that uses the Android Native Development Kit (NDK) to calculate the dot product of two vectors. Finally, we’ll see how to improve the performance of such a function with NEON intrinsics.
Do not repeat yourself (DRY) is one of the major principles of software development, and following this principle typically means reusing your code via functions. Unfortunately, invoking a function adds extra overhead. To reduce this overhead, compilers take advantage of built-in functions called intrinsics, where the compiler will replace the intrinsics used in the high level programming languages (C/C++) with mostly 1-1 mapped assembly instructions. To even further improve performance, you're into the realm of assembly code, but with Arm Neon intrinsics. You can often avoid the complication of writing assembly functions. Instead you only need to program in high level languages and call the intrinsics or instruction functions declared in the arm_neon.h header file.
As an Android developer, you probably don’t have the time to write assembly language. Instead, your focus is on app usability, portability, design, data access, and tuning the app to various devices. If that's the case, Neon intrinsics is going to be a big performance help.
Arm Neon intrinsics technology is an advanced single instruction multiple data (SIMD) architecture extension for Arm processors. The idea of SIMD is to perform the same operation on a sequence or vector of data during a single CPU cycle.
For instance, if you’re summing numbers from two one-dimensional arrays, you need to add them one by one. In a non-SIMD CPU, each array element is loaded from memory to CPU registers, then the register values are added and the result is stored in memory. This procedure is repeated for all elements. To speed up such operations, SIMD-enabled CPUs load several elements at once, perform the operations, then store results to memory. Performance will improve depending on the sequence length, N. Theoretically, the computation time will reduce N times.
By utilizing SIMD architecture, Neon intrinsics can accelerate the performance of multimedia and signal processing applications, including video and audio encoding and decoding, 3D graphics, and speech and image processing. Neon intrinsics provide almost as much control as writing assembly code, but they leave the allocation of registers to the compiler so developers can focus on the algorithms. Hence, Neon intrinsics strike a balance between performance improvement and the writing of assembly language.
First, I’m going to show you how to set up your Android development environment to use Neon intrinsics. Then, we’ll implement an Android application that uses the Android Native Development Kit (NDK) to calculate the dot product of two vectors. Finally, we’ll see how to improve the performance of such a function with NEON intrinsics.
I created the example project with Android Studio. The sample code is available from the GitHub repository NeonIntrinsics-Android. I tested the code using a Samsung SM-J710F phone.
Native C++ Android Project Template
I started by creating a new project using the Native C++ Project Template.
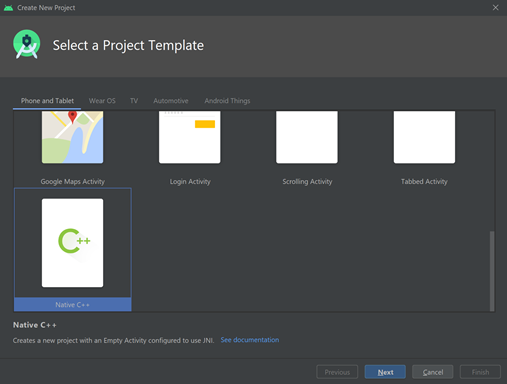
Then, I set the application name to Neon Intrinsics, selected Java as the language, and set the minimum SDK to API 19: Android 4.4 (KitKat).

Then, I picked Toolchain Default for the C++ Standard.
The project I created comprises one activity that’s implemented within the MainActivity class, deriving from AppCompatActivity (see app/java/com.example.neonintrinsics/MainActivity.java). The associated view contains only a TextView control that displays a “Hello from C++” string.
To get these results, you can run the project directly from Android Studio using one of the emulators. To build the project successfully, you’ll need to install CMake and the Android NDK. You do so through the settings (File | Settings). Then, you select NDK and CMake on the SDK Tools tab.
If you open the MainActivity.java file, you’ll note that the string displayed in the app comes from native-lib. This library’s code resides within the app/cpp/native-lib.cpp file. That’s the file we’ll use for our implementation.
Enabling Neon Intrinsics Support
To enable support for Neon intrinsics, you need to modify the ABI filters so the app can be built for the Arm architecture. Neon has two versions: one for Armv7, Armv8 AArch32, and one for Armv8 AArch64. From an intrinsics point of view there are a few differences, such as the addition of vectors of 2xfloat64 in Armv8-A. They are all available in the arm_neon.h header file that is included in the compiler’s installation path. You also need to import the Neon libraries.
Go to the Gradle scripts, and open the build.gradle (Module: app) file. Then, supplement the defaultConfig section by adding the following statements. First, add this line to the general settings:
ndk.abiFilters 'x86', 'armeabi-v7a', 'arm64-v8a'
Here, I am adding the support for x86, 32-bit and 64-bit ARM architectures. Then add this line under the cmake options:
arguments "-DANDROID_ARM_NEON=ON"
It should look like this:
defaultConfig {
applicationId "com.example.myapplication"
minSdkVersion 16
targetSdkVersion 29
versionCode 1
versionName "1.0"
ndk.abiFilters 'x86', 'armeabi-v7a', 'arm64-v8a'
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
externalNativeBuild {
cmake {
cppFlags ""
arguments "-DANDROID_ARM_NEON=ON"
}
}
}
Now you can use Neon intrinsics, which are declared within the arm_neon.h header. Note that the build will only be successful for ARM-v7 and above. To make your code compatible with x86, you can use the Intel porting guide.
Dot Product and Helper Methods
We can now implement the dot product of two vectors using C++. All the code should be placed in the native-lib.cpp file. Note that, starting from armv8.4a, the DotProduct is part of the new instruction set. This corresponds to some cortex A75 designs and all Cortex A76 designs onwards. See Exploring the Arm dot product instructions for more information.
We start with the helper method that generates the ramp, which is the vector of 16-bit integers incremented from the startValue:
short* generateRamp(short startValue, short len) {
short* ramp = new short[len];
for(short i = 0; i < len; i++) {
ramp[i] = startValue + i;
}
return ramp;
}
Next, we implement the msElapsedTime and now methods, which will be used later to determine the execution time:
double msElapsedTime(chrono::system_clock::time_point start) {
auto end = chrono::system_clock::now();
return chrono::duration_cast<chrono::milliseconds>(end - start).count();
}
chrono::system_clock::time_point now() {
return chrono::system_clock::now();
}
The msElapsedTime method calculates the duration (expressed in milliseconds) that passed from a given start point.
The now method is a handy wrapper for the std::chrono::system_clock::now method, which returns the current time.
Now create the actual dotProduct method. As you remember from your programming classes, to calculate a dot product of two equal-length vectors, you multiply vectors element-by-element, then accumulate the resulting products. A straightforward implementation of this algorithm follows:
int dotProduct(short* vector1, short* vector2, short len) {
int result = 0;
for(short i = 0; i < len; i++) {
result += vector1[i] * vector2[i];
}
return result;
}
The above implementation uses a for loop. So, we sequentially multiply vector elements and then accumulate the resulting products in a local variable called result.
Calculating Dot Product Using Neon Intrinsics
To modify the dotProduct function to benefit from Neon intrinsics, you need to split the for loop such that it will utilize data lanes. To do so, partition or vectorize the loop to operate on sequences of data during a single CPU cycle. These sequences are defined as vectors. However, to distinguish them from the vectors we use as inputs for the dot product, I’ll call these sequences register vectors.
With register vectors, you reduce the loop iterations such that, at every iteration, you multiply, then accumulate, multiple vector elements to calculate the dot product. The number of elements you can work with depends on the register layout.
The Arm Neon architecture uses a 64-bit or 128-bit register file (more info here). In a 64-bit case, you can work with either eight 8-bit, four 16-bit, or two 32-bit elements. In a 128-bit case, you can work with either sixteen 8-bit, eight 16-bit, four 32-bit, or two 64-bit elements.
To represent various register vectors, Neon intrinsics use the following name convention:
<type><size>x<number of lanes>_t
<type> is the data type (int, uint, float or poly).<size> is the number of bits used for the data type (8, 16, 32, 64).<number of lanes> defines how many lanes.
For example, int16x4_t will represent a vector register with 4 lanes of 16-bit integer elements, which is equivalent to a four-element int16 one-dimensional array (short[4]).
You don’t instantiate Neon intrinsic types directly. Instead, you use dedicated methods to load data from your arrays to CPU registers. The names of these methods start with vld. Note that method naming uses a convention similar to the one for type naming. All methods start with v, which is followed by a method short name (like ld for load), and the combination of a letter and a number of bits (for example, s16) to specify the input data type.
Neon intrinsics directly correspond to the assembly instructions.
int dotProductNeon(short* vector1, short* vector2, short len) {
const short transferSize = 4;
short segments = len / transferSize;
int32x4_t partialSumsNeon = vdupq_n_s32(0);
for(short i = 0; i < segments; i++) {
short offset = i * transferSize;
int16x4_t vector1Neon = vld1_s16(vector1 + offset);
int16x4_t vector2Neon = vld1_s16(vector2 + offset);
partialSumsNeon = vmlal_s16(partialSumsNeon, vector1Neon, vector2Neon);
}
int partialSums[transferSize];
vst1q_s32(partialSums, partialSumsNeon);
int result = 0;
for(short i = 0; i < transferSize; i++) {
result += partialSums[i];
}
return result;
}
Here, to load data from memory, I use the vld1_s16 method. This method loads four elements from the array of shorts (signed 16-bit integers or s16 for short) to the CPU registers.
Once the elements are in the CPU registers, I add them using the vmlal (multiply and accumulate) method. This method adds elements from two arrays and accumulates the result in a third array.
Here, this array is stored within the partialSumsNeon variable. To initialize this variable, I used the vdupq_n_s32 (duplicate) method, which sets all CPU registers to the specific value. In this case, the value is 0. It’s the vectorized equivalent of writing int sum = 0.
Once all the loop iterations complete, you need to store the resulting sums back to memory. You can either read the results element by element using vget_lane methods, or store the whole vector using vst methods. I use the second option.
Once the partial sums are back in memory, I sum them to get the final result.
Note that, on AArch64 you could also use:
return vaddv_s32 (partialSumsNeon);
Then skip the second for loop.
Putting Things Together
We can now put all of the code together. To that end, we’ll modify the MainActivity.stringFromJNI method.
extern "C" JNIEXPORT jstring JNICALL
MainActivity.stringFromJNI (
JNIEnv* env,
jobject ) {
const int rampLength = 1024;
const int trials = 10000;
auto ramp1 = generateRamp(0, rampLength);
auto ramp2 = generateRamp(100, rampLength);
int lastResult = 0;
auto start = now();
for(int i = 0; i < trials; i++) {
lastResult = dotProduct(ramp1, ramp2, rampLength);
}
auto elapsedTime = msElapsedTime(start);
int lastResultNeon = 0;
start = now();
for(int i = 0; i < trials; i++) {
lastResultNeon = dotProductNeon(ramp1, ramp2, rampLength);
}
auto elapsedTimeNeon = msElapsedTime(start);
delete ramp1, ramp2;
std::string resultsString =
"----==== NO NEON ====----\nResult: " + to_string(lastResult)
+ "\nElapsed time: " + to_string((int)elapsedTime) + " ms"
+ "\n\n----==== NEON ====----\n"
+ "Result: " + to_string(lastResultNeon)
+ "\nElapsed time: " + to_string((int)elapsedTimeNeon) + " ms";
return env->NewStringUTF(resultsString.c_str());
}
The MainActivity.stringFromJNI method proceeds as follows.
First, we create two equal-length vectors using generateRamp methods.
Next, we calculate the dot product of those vectors using the non-Neon method dotProduct. We repeat this calculation several times (trials constant), and measure the computation time using msElasedTime.
Then, we do the same operations but now using the Neon-enabled method dotProductNeon.
Finally, we combine the results of those two methods along with the computation times within the resultsString. The latter will be displayed in the TextView. Note that to build and run the above code successfully, you need an Arm-v7-A/Armv8-A device.
That's a 7 percent improvement simply by using built-in intrinsics. A theoretical improvement of 25 percent could be achieved on Arm 64 devices.
Wrapping Up
In this article, we saw how to set up Android Studio for native C++ development, and to utilize Neon intrinsics for Arm-powered mobile devices.
After explaining the idea behind Neon intrinsics, we demonstrated a sample implementation of the dot product of two equal-length vectors. We then vectorized the method using dedicated Neon intrinsics. By doing so, we presented the significant steps you take when working with Neon intrinsics, in particular, loading data from memory to CPU registers, completing the operations, and then storing the results back to memory.
Vectorizing code is never an easy task. However, you can simplify it with Neon intrinsics to improve performance in scenarios that employ 3D graphics, signal and image processing, audio encoding, and video streaming, to name just a few.
References and Useful Links
Dawid Borycki is a software engineer and biomedical researcher with extensive experience in Microsoft technologies. He has completed a broad range of challenging projects involving the development of software for device prototypes (mostly medical equipment), embedded device interfacing, and desktop and mobile programming. Borycki is an author of two Microsoft Press books: “Programming for Mixed Reality (2018)” and “Programming for the Internet of Things (2017).”





