Introduction
It is a fundamental skill to extract data from formatted or unformatted data sources and make further processing. A typical case is, access a website, grab Html pages and get some useful information. The basic steps to accomplish this are:
- Create http request to grab html data
- Extract information from HTML code
- Process dump data to local database for further processing
Background
There are two fundamental ways to retrieve data from Internet through HTTP: GET and POST. Most websites support GET method to return data. You can simply initiate a GET request by entering the URL in browsers. However, some websites considering security issues or length restriction of request parameters only accept POST method to return data.
For instance, MSDN blog search form supports POST requests:
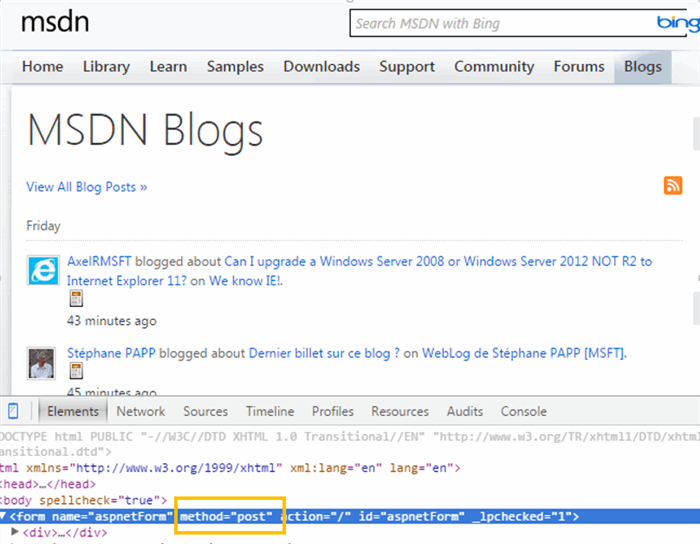
Another example is tracking the status of deliveries. Due to the reason of dealing with sensitive data, carriers either provide public web services to allow users to retrieve data, or only provide online query by submitting a form using POST. In order to grab the information, we have to simulate a POST request and parse the returned Html data to extract the details.

Using the Code
In this tutorial, you grab tracking event logs from speedy.ca. Here are the steps:
- Create an ASP.NET Web Forms project
- Add a web form with two textboxes, one button, two labels and a gridview. You will use gridview to display the results.
- Double click button and implement event handler:
protected void btpParse_Click(object sender, EventArgs e)
{
String website = txtWebsite.Text;
String param = txtParam.Text;
String htmlData = GrabHtmlData(website, param);
if (htmlData != null)
{
lblGrabResult.Text = "Size of html data: " + htmlData.Length + " characters";
List<EventLog> logs = ParseData(htmlData);
lblParseResult.Text = "Count of items: " + logs.Count;
gvParseResult.DataSource = logs;
gvParseResult.DataBind();
}
else
{
lblGrabResult.Text = "Failed to grab html data";
}
}
Here, you define a class EventLog to save event logs.
public class EventLog
{
public DateTime EventDate { get; set; }
public String EventName { get; set; }
public String EventLocation { get; set; }
public override string ToString()
{
return EventDate + " " + EventName + " " + EventLocation;
}
}
- Implement
GrabHtmlData() and ParseData() methods.
1. Grab Html Data
There are multiple ways to send POST request. You could use 3rd-party tools such as Fiddler, Postman to create POST requests. You can also create POST requests programmatically. In C#, WebRequest and WebClient classes from System.Net namespace allow you to do this.
Way1 to get Html Data - via HttpWebRequest
HttpWebRequest request = WebRequest.CreateHttp(website) as HttpWebRequest;
request.Method = "POST";
request.KeepAlive = false;
request.ContentType = "application/x-www-form-urlencoded";
string postData = "pro=" + param;
byte[] byteArray = Encoding.UTF8.GetBytes(postData);
request.ContentLength = byteArray.Length;
using (Stream stream = request.GetRequestStream())
{
stream.Write(byteArray, 0, byteArray.Length);
}
var response = request.GetResponse() as HttpWebResponse;
using (var stream = response.GetResponseStream())
{
StreamReader reader = new StreamReader(stream);
return reader.ReadToEnd();
}
Way2 to get Html Data - via WebClient
private string GrabHtmlDatabyWebClient(string website, string param)
{
using (var client = new WebClient())
{
var values = new NameValueCollection();
values["pro"] = param;
var response = client.UploadValues(website, values);
return Encoding.Default.GetString(response);
}
}
2. Parse Html data
There are multiple ways to extract data from Html document in C#.
Way1 - via HtmlDocument
.NET contains HtmlDocument, HtmlElement and HtmlNodeCollection classes (under System.Windows.Forms namespace) to parse Html page. HtmlDocument provides basic DOM methods like GetElementById() and GetElementsByTagName().
e.g. Find and print all links inside a table:
<table>
...
<div class="photoBox">
<a href="/user_details?userid=9HuMj3ePDGWR7vs3kLfZGg">
<img width="100" height="100" alt="Photo of Terry"
src="http://s3-cdn.azure.com/photo/uiBlab5eTCJJuUrpdauA/ms.jpg">
</a>
</div>
...
</table>
Sample code to parse html segment:
String htmlData = ..;
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(htmlData);
HtmlNodeCollection col = doc.DocumentNode.SelectNodes("//table");
foreach (HtmlNode node in col)
{
String link = node.Attributes["href"].Value;
Console.WriteLine(link);
}
Similarly, .NET also provides XmlDocument class and XmlNode to parse XML document.
Way2 - via Regular Expression
The regular expressions language is designed to identify character patterns. It is generally used to implement search, read, replace and modify text. With regular expressions, you can perform very sophisticated and high-level operations on strings:
- Validate text input such as emails, passwords and phone numbers
- Parse textual data into more structured forms, e.g., extract links, pictures, titles from html page
- Process patterns of text in a document, e.g., count repeated words and replace words
Of course, you can use methods in System.String and System.Text.StringBuilder to accomplish these tasks, but it requires fair amount of C# code. You can use regular expressions to achieve these through just a couple of lines.
Steps
- Instantiate a
System.Text.RegularExpressions.Regex object - Pass in the
string to be processed - Pass in a regular expression
- Start match and process returned groups
For example:
string htmlData = ...;
string pattern = @"<[dD][iI][vV]\sclass=[\""\']?adxTOCTitleMycenNews[\""\']?>
<[aA]\shref=[\""\']?[^>]*>(?<title>[^<]*)<\/[aA]>";
Regex r = new Regex(pattern);
MatchCollection mc = r.Matches(htmlData);
foreach (Match m in mc)
{
GroupCollection gc = m.Groups;
Console.WriteLine("News title: " + gc["title"].Value);
}
However, Regex is less efficient in extracting data from Html Data. In read world, HTML document might be mal-formed, various and even include empty tags such as <br>, <br/>. It is complicated to write an appropriate Regex to identify target html tags. For instance, considering the different formats of <input/>, <input type=text name=firstName value=> and <input type="text" name="firstName" value=""/>, it is a challenging job to write a Regex to consider all the cases.
Way3 - via third-party libraries
Html Agility Pack (HAP) is a HTML parser that builds a read/write DOM. HAP enhances internal .NET HtmlDocument. It allows you to parse HTML files in a convenient way. HAP also supports Linq to Objects. The major benefit is, the parser is very tolerant with "real world" malformed HTML (i.e., lacking proper closing tags or capitalized tags). HAP goes through page content and builds document object model that can be later processed. Once the document is loaded, you can start parsing data through loop the nodes.
To start working with HAP, you should install NuGet package named HtmlAgilityPack.
You can also download it at https://www.nuget.org/packages/Fizzler.Systems.HtmlAgilityPack/.
Steps to parse Html data:
- Create an
HtmlWeb object. It is a utility tool to get the HTML over HTTP. - Create an
HtmlDocument object to accept the Html data. - Find a
HtmlNode object through getElementById() method. - Use node's properties such as
ChildNodes, FirstChild, NextSibling and ParentNode to navigate the nodes. Or, use Ancestors() and Descendants() methods to get a list of the node's ancestors or descendants. - Create
HtmlAttribute objects from nodes and extract the data by node's Attributes property or extract the text using innerText and innerHtml property.
Sample code:
HtmlDocument document = new HtmlDocument();
doc.Load("file.htm");
HtmlNode myNode = document.GetElementbyId("mynode");
foreach(HtmlNode link in myNode.Descendants("//a[@href"])
{
HtmlAttribute attr = link.Attributes["href"];
Console.WriteLine(attr.Value);
}
In order to extract the tracking event data from the following table, you need to loop each row and get data from each column.
Sample Html code:
<div class="ServicesResults">
...
<table width=498 border=0 class='textTracing'>
<tr id='TableTitle'>
<td colspan=4 id='ProbillHeader'>
Shipment Timeline for 3009000
Delivery ETA: 09-Oct-2015 (Appointment)
</td>
</tr>
<tr>
<td class='ColumnHeader' id='DateHeader'>Date</td>
<td class='ColumnHeader' id='TimeHeader'>Time</td>
<td class='ColumnHeader' id='StatusHeader'>Status</td>
<td class='ColumnHeader' id='LocHeader'>Location</td>
</tr>
<form id='FindPOD' name='FindPOD' action='findpod.asp' method='post'>
<tr>
<td class='ColumnValue'>Wed 07-Oct-2015</td>
<td class='ColumnValue'>01:08Hrs</td>
<td class='ColumnValue'>Bill Entered</td>
<td class='ColumnValue'>Toronto, ON</td>
</tr>
<tr>
<td class='ColumnValue'> </td>
<td class='ColumnValue'>05:10Hrs</td>
<td class='ColumnValue'>Loaded-Tor-Mtl</td>
<td class='ColumnValue'>Toronto, ON</td>
</tr>
<tr>
<td class='ColumnValue'> </td>
<td class='ColumnValue'>06:05Hrs</td>
<td class='ColumnValue'>Enroute to Montreal ex-Toronto</td>
<td class='ColumnValue'>Toronto, ON</td>
</tr>
<tr>
<td class='ColumnValue'>Thu 08-Oct-2015</td>
<td class='ColumnValue'>13:05Hrs</td>
<td class='ColumnValue'>Appointment Set 09-Oct-2015 08:00 - 12:00Hrs</td>
<td class='ColumnValue'>Toronto, ON</td>
</tr>
...
</tr>
</table>
</div>
Note that the table has a CSS class "textTracing" and is wrapped inside a div with another CSS class "ServicesResults". In order to get the nodes and extract data by identifying nodes through CSS, you can install another library Fizzler which is implemented as the extension of HtmlNode in HTML Agility Pack. Fizzler is a light .NET CSS Selector Engine and enables you to select items from a node tree through a CSS selector.
To install Fizzler, you should install NuGet package named Fizzler.Systems.HtmlAgilityPack.
You can also install at https://www.nuget.org/packages/Fizzler.Systems.HtmlAgilityPack/.
You can call QuerySelectorAll() method (accept class name as parameter) to get nodes and extract data from nodes. Until now, you already grab the Html data, the next is to pass the data to HtmlDocument object and go further to extract the data.
private List<EventLog> ParseData(string htmlData)
{
var logs = new List<EventLog>();
var document = new HtmlAgilityPack.HtmlDocument();
document.LoadHtml(htmlData);
var resultNode = document.DocumentNode.QuerySelector(".ServicesResults .textTracing");
String date = null;
String time = null;
String status = null;
String location = null;
foreach (var rowNode in resultNode.Descendants("tr").Skip(2))
{
var colNodes = rowNode.Descendants("td");
if (colNodes.Count() != 4)
{
throw new InvalidOperationException("The website modify the format result results");
}
var colList = colNodes.ToList();
if (colList[0].InnerText != " ")
date = colList[0].InnerText;
time = colList[1].InnerText;
status = colList[2].InnerText;
location = colList[3].InnerText;
var log = new EventLog()
{
EventDate = DateTime.Now,
EventName = status,
EventLocation = location
};
logs.Add(log);
}
return logs;
}
Final Demo
After compiling the project, you will get the gridview filled with parsed event logs:
History
- October 11, 2015: First version posted
- October 20, 2015: Add screenshot of final project
Andy Feng is a software analyst/developer based in Toronto, Canada. He has 9+ years experience in software design and development. He specializes in Java/J2EE and .Net solutions, focusing on Spring, Hibernate, JavaFX, ASP.NET MVC, Entity framework, Web services, JQuery, SQL and related technologies.
Follow up with my blogs at: http://andyfengc.github.io/


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






