In a previous article, we discussed how to perform the recognition of handwritten digits using Kernel Discriminant Analysis. In this article, we will discuss some techniques to do it using Kernel Support Vector Machines.
For the latest version of the code, which may contain the latest enhancements and corrections, please download the latest version of the Accord.NET Framework.
Contents
- Introduction
- Support Vector Machines
- Kernel Support Vector Machines
- Multi-class Support Vector Machines
- Source code
- Support Vector Machines
- Training Algorithms
- Digit recognition
- UCI's Optdigits Dataset
- Classification of Digits by a Multi-class SVM
- Sample application
- Learning
- Results
- Conclusion
- See Also
- References
- History
In a previous article, I wanted to show how to use Kernel Discriminant Analysis to solve the problem of handwriting recognition. However, I feel I didn't do justice to the problem of handwriting recognition because my main focus was on KDA, not on the recognition per se. In this article, I will show perhaps a better method to tackle this problem.
Kernel Discriminant Analysis has its own set of problems. It scales poorly to the number of samples as O(n³), despite having no problem dealing with high-dimensional data. Another serious problem is that it requires the entire training set to be available during model evaluation, making it unsuitable in many scenarios (such as in embedded systems).
At the end of the previous article, I had mentioned Support Vector Machines (SVMs) as better candidates for performing handwritten digits recognition. One advantage of SVMs is that their solutions are sparse, so, unlike KDA, they do not require the entire training set to be always available during evaluation. Only a (typically small) subset will be needed. This subset is what is commonly called "support vectors".
Support Vector Machines (SVMs) are a set of related supervised learning methods which can be used for both classification and regression. In simple words, given a set of training examples, each marked as belonging to one of two categories, an SVM classification training algorithm tries to build a decision model capable of predicting whether a new example falls into one category or the other. If the examples are represented as points in space, a linear SVM model can be interpreted as a division of this space so that the examples belonging to separate categories are divided by a clear gap that is as wide as possible. New examples are then predicted to belong to a category based on which side of the gap they fall on.

Support Vector Machine as a maximum margin classifier. The leftmost picture shows a decision problem for two classes, blue and green. The middle picture shows the hyperplane which has the largest distance to the nearest training data points of each class. The rightmost picture shows that only two data points are needed to define this hyperplane. Those will be taken as support vectors, and will be used to guide the decision process.
A linear support vector machine is composed of a set of given support vectors z and a set of weights w. The computation for the output of a given SVM with N support vectors z1, z2, ... , zN and weights w1, w2, ... , wN is then given by:
A decision function is then applied to transform this output in a binary decision. Usually, sign(.) is used, so that outputs greater than zero are taken as a class and outputs lesser than zero are taken as the other.
As detailed above, the original SVM optimal hyperplane algorithm is a linear classifier. However, almost 30 years later, since its introduction in 1963, some researchers (and the original author himself) suggested a way to create non-linear classifiers by applying the kernel trick to those maximum-margin hyperplanes. The result was a "boom" in the research of Kernel Machines, which became one of the most powerful and popular classification methods to date.
And it was not without a reason. The Kernel trick is a very powerful tool able to provide a bridge from linearity to non-linearity to algorithms which solely depend on the dot product between two vectors. It comes from the fact that, if we first map our input data into a higher-dimensional space, a linear algorithm operating in this space will behave non-linearly in the original input space.
The "trick" resides in the fact that this mapping does not ever need to be computed: all we have to do is replace all dot products by a suitable kernel function. The kernel function denotes an inner product in feature space, and is usually denoted as:
Kernel function (in which φ denotes a possibly non-linear mapping function).
Using a Kernel function, the algorithm can then be carried into a higher-dimension space without explicitly mapping the input points into this space. This is highly desirable, as sometimes our higher-dimensional feature space could even be infinite-dimensional and thus infeasible to compute. Since the original formulation of SVMs mainly consists of dot products, it is straightforward to apply the Kernel trick. Even if the resulting classifier is still a hyperplane in the high-dimensional feature space, it may be non-linear in the original input space. The use of the Kernel trick also gives a much stronger theoretical support to the underlying classifiers when in comparison with methods which have different source of inspiration, such as biology.
Schematic diagram demonstrating how the Kernel trick can be applied to the original Support Vector Machine formulation.
It is also very straightforward to see that, using a linear kernel (of the form K(z,x) = <z,x> = zTx), we recover the original formulation for the linear SVM. For more details about the kernel trick and also an example of readily available Kernel functions, you can check either the previous article about Kernel Discriminant Analysis or the page Kernel Functions for Machine Learning Applications.
Unfortunately, unlike KDA, Support Vector Machines do not generalize naturally to the multi-class classification case. SVMs are binary classifiers, and as such, in their original form, they can only decide between two classes at once. However, many approaches have been suggested to perform multi-class classification using SVMs, one of which will be exemplified below.
Suppose we have to decide between three classes, A, B, and C. Now, suppose all we have are binary classifiers, i.e., methods which can automatically decide only between two classes. A possible approach in order to use our binary classifiers in a multi-class classification problem would be to try to divide our multi-class problem into a set of binary problems. The left matrix below shows all possible combinations of binary decision problems which can be formed by taking our three classes:
However, notice that the left matrix includes some redundant scenarios. For example, it is pointless to compute the decision between A and A. It is also inefficient to compute both B x A and A x B, when computing only one and taking the opposite would suffice. Discarding the redundant options, we are left with the matrix on the right. As it can be seen, a typical decision problem between n classes can always be decomposed in a small subset of n(n-1)/2 binary problems.
Now that we are left with three binary problems, it is then straightforward to see that in order to achieve multiclass classification using SVMs, all we have to do is to create three SVMs to operate, each in one of the sub-problems.
To decide for a class, we can use a voting scheme in which the class which receives the most decisions is declared the winner of the decision process. For example, let's say class A won in the first machine, and that C won in both the second and the third.
If we take the class which receives most of the votes as the winner, then it is clear that our multi-class machine should decide for C. This approach is often described as a one-against-one strategy for multi-class classification.
Voting results from the one-against-one decision process.
Another possible approach is to use a one-against-all strategy where the input pattern is presented to all SVMs and decide for the SVM which produces the highest output. Unfortunately, nothing guarantees that a higher positive output from a machine is better than a lower, but still positive output from another machine, so just choosing the machine which produces the highest output as a winner in the decision process can lead to poor results. That is, unless one is using Relevance Vector Machines, which in this case, this strategy would work since the outputs would be indeed probabilities. However, RVMs have problems of their own which are beyond the scope of this article.
For the reasons listed above, we will be focusing only on one-against-one multi-class classification in the rest of this article.
The (Kernel) Support Vector Machine code presented here is also part of Accord.NET, a framework I've been building over the years. It is built on top of AForge.NET, a popular framework for computer vision and machine learning, aggregating various topics I needed through my past researches. Currently, it has implementations for PCA, KPCA, LDA, KDA, LR, PLS, SVMs, HMMs, LM-ANN, and lots other acronyms. The project is hosted in GitHub, at https://github.com/accord-net/framework/.
For the latest version of this code which may contain the latest bug-fixes, corrections, enhancements, and features, I highly recommend the download of the latest version of Accord.NET directly from the project's site.
The classes for the machines included in the source code are shown below:
The KernelSupportVectorMachine class extends SupportVectorMachine with Kernels. MulticlassSupportVectorMachine employs a collection of KernelSupportVectorMachines working in a one-against-one voting scheme to perform multi-class classification. The code presented here and the framework offers an extensive list of machine learning kernel functions to chose from.
The training algorithms can perform both classification and regression. They are direct implementations of Platt's Sequential Minimal Optimization (SMO) algorithm. MulticlassSupportVectorLearning provides a delegate function, denoted Configure, which can be used to select and configure any learning algorithm. This approach does not impose limitations on which algorithm to use, and also allows the user to specify his own algorithms to perform training.
Since the MulticlassSupportVectorLearning algorithm works by training a set of independent machines at once, it is easily parallelizable. In fact, the available implementation can take full advantage of extra cores in a single machine.
public double Run(bool computeError)
{
AForge.Parallel.For(0, msvm.Classes, delegate(int i)
{
for (int j = 0; j < i; j++)
{
var machine = msvm[i,j];
int[] idx = outputs.Find(x => x == i || x == j);
double[][] subInputs = inputs.Submatrix(idx);
int[] subOutputs = outputs.Submatrix(idx);
subOutputs.ApplyInPlace(x => x = (x == i) ? -1 : 1);
configure(machine, subInputs, subOutputs).Run(false);
}
});
}
The code listed above uses AForge.NET Parallel constructions alongside with Accord.NET matrix extensions. I have decided not to use the newly added .NET 4.0 Parallel Extensions so the Framework could still be compatible with .NET 3.5 applications.
If you have already read the previous article about Kernel Discriminant Analysis for Handwritten Digit Recognition, just skip this section. This is an introduction to the Optdigits Dataset from the UCI Machine Learning Repository.
The UCI Machine Learning Repository is a collection of databases, domain theories, and data generators that are used by the machine learning community for the empirical analysis of machine learning algorithms. One of the available datasets is the Optical Recognition of Handwritten Digits Data Set (a.k.a. the Optdigits Dataset).
In raw Optdigits data, digits are represented as 32x32 matrices. They are also available in a pre-processed form in which digits have been divided into non-overlapping blocks of 4x4 and the number of on pixels have been counted in each block. This generates 8x8 input matrices where each element is an integer in the range 0..16.
Sample digits extracted from the raw Optdigits Dataset.
Kernel methods are appealing because they can be applied directly to problems which would require significant data pre-processing (such as dimensionality reduction) and extensive knowledge about the structure of the data being modeled. Even if we know little about the data, a direct application of Kernel methods (with less preprocessing) often finds interesting results. Achieving optimality using Kernel methods can become, however, a very difficult task because we have an infinite choice of Kernel functions to choose from - and for each kernel, an infinite parameter space to tweak.
The following code shows how a Multiclass (Kernel) Support Vector Machine is instantiated. Note how the inputs are given as full vectors of 1024 positions. This would be impractical if we were going to use Neural Networks, for example. Kernel methods, in general, however, have no problems processing large dimensionality problems because they do not suffer from the curse of dimensionality.
int samples = 500;
double[][] input = new double[samples][];
int[] output = new int[samples];
for (int i = 0; i < samples; i++)
{
...
}
IKernel kernel = new Polynomial((int)numDegree.Value, (double)numConstant.Value);
ksvm = new MulticlassSupportVectorMachine(1024, kernel, 10);
var ml = new MulticlassSupportVectorLearning(ksvm, input, output);
double complexity = (double)numComplexity.Value;
double epsilon = (double)numEpsilon.Value;
double tolerance = (double)numTolerance.Value;
ml.Configure = delegate(KernelSupportVectorMachine svm,
double[][] cinput, int[] coutput)
{
var smo = new SequentialMinimalOptimization(svm, cinput, coutput);
smo.Complexity = complexity;
smo.Epsilon = epsilon;
smo.Tolerance = tolerance;
return smo;
};
double error = ml.Run();
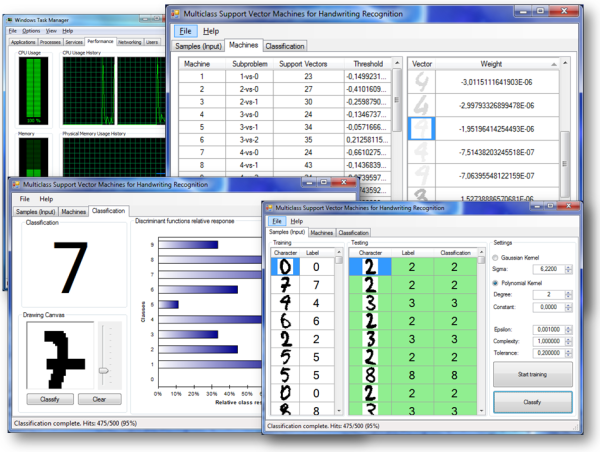
The sample application which accompanies the source code can perform the recognition of handwritten digits using Multi-class Kernel Support Vector Machines. To do so, open the application (preferably outside Visual Studio, for better performance), click on the File menu, and select Open. This will load some entries from the Optdigits Dataset into the application.
To start the learning process, click the button "Start training". Using the default settings, it should not take too long. Since the code uses the Parallel Extensions from AForge.NET, the greater the number of cores, the faster the training.
Training a Multi-class Support Vector Machine using the parallelized learning algorithms of the Accord.NET Framework.
After the training is complete, click "Classify" to start the classification of the testing set. Using the default values, it should achieve up to 95% accuracy, correctly identifying around 475 instances of the 500 available. The recognition ratio of the testing set may vary around a little depending on the learning algorithm's run.
Results from the Kernel Support Vector Machine learning algorithm.
The same set and the same amount of training and testing samples have been used as in the previous Kernel Discriminant Analysis article for comparison purposes. Since SVMs are more efficient both in processing time and memory needs, probably higher accuracy rates could be achieved by using more samples from the dataset.
After training, the created SVMs can be seen in the "Machines" tab. The support vectors and the bias (threshold) for each machine can be seen by selecting one of the entries in the first DataGridView. The darker the vector, the more weight it has in the decision process.
Details about Support Vector Machines, including their support vectors.
Even if the gain on recognition rate was just over 3%, the accuracy of the recognition has greatly improved upon KDA. By clicking on the "Classification" tab, we can manually test the Multi-class Support Vector Machine for user drawn digits.
We can see that the SVM method produces much more robust results, as even badly drawn digits can still be recognized accurately:
Recognition of handwritten digits.
And finally, here is a video demonstration of the handwritting recognition sample application[^], as included in the latest version of the Accord.NET Framework.
In this article, we detailed and explored how (Kernel) Support Vector Machines could be applied in the problem of handwritten digit recognition with satisfying results. The suggested approach does not suffer from the same limitations of Kernel Discriminant Analysis, and also achieves a better recognition rate. Unlike KDA, the SVM solutions are sparse, meaning only a generally small subset of the training set will be needed during model evaluation. This also means the complexity during the evaluation phase will be greatly reduced since it will depend only on the number of vectors retained during training.
One of the disadvantages of Support Vector Machines, however, is the multitude of methods available to perform multi-class classification since they can not be applied directly to such problems. Nevertheless, here we discussed and exemplified how to employ a one-against-one strategy in order to produce accurate results even if your data set is unbalanced.
As in KDA, another problem that raises from Kernel methods is the proper choice of the Kernel function (and the tuning of its parameters). This problem is often tractable with grid search and cross-validation, which are by themselves very expensive operations, both in terms of processing power and training data available. Nonetheless, those methods can be parallelized easily, and a parallel implementation of grid search is also available in the Accord.NET Framework.
- Wikipedia contributors, "Sequential Minimal Optimization", Wikipedia, The Free Encyclopedia, http://en.wikipedia.org/wiki/Sequential_Minimal_Optimization (accessed April 24, 2010).
- Wikipedia contributors, "Support Vector Machine", Wikipedia, The Free Encyclopedia, http://en.wikipedia.org/wiki/Support_vector_machine (accessed April 24, 2010).
- John C. Platt, Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines, Microsoft Research, 1998.
- J. P. Lewis, A Short SVM (Support Vector Machine) Tutorial. CGIT Lab / IMSC, University of Southern California.
- A. J. Smola and B. Scholkopf, A Tutorial on Support Vector Regression. NeuroCOLT2 Technical Report Series, 1998.
- S. K. Shevade et al. Improvements to SMO Algorithm for SVM Regression, 1999.
- G. W. Flake, S. Lawrence, Efficient SVM Regression Training with SMO.
- A. Asuncion & D.J. Newman, UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science (2007).
- Andrew Kirillov, The AForge.NET Framework. The AForge.NET Computer Vision, Artificial Intelligence and Robotics Website, 2010.
- C. R. Souza, Kernel Functions for Machine Learning Applications. 17 Mar. 2010. Web.
- 1st September, 2010: Initial version


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







{kind=link}