Contents
It's not hard to find articles about MSMQ. They usually focus on the good side of it- what's MSMQ good for, how, when and why to use it. Although MSMQ really helps in many distributed scenarios, it's not without problems. If you have a complex system with some external dependencies, where subsystems are under constant development with lots of updates, sooner or later something will break. Once a subsystem sends a message which the receiver is not able to process, for one reason or the other- you'll have poison messages.
What are poison messages?
Poison messages are messages that can not be processed. If they stay on top of a queue other messages will never get a chance. This could happen in any architecture involving first-in first-out queues, including MSMQ.
What happens when a message fails? Sometime the failure is transient - for example when processing involves a DB transaction that was terminated as a deadlock victim, or when some external component is temporarily unavailable. The solution is simple - we will receive messages transactionally, and if any exception is thrown during the processing, we will roll back the entire transaction. Messages will go back to the queue and after some time we will retry the processing. Hopefully the transient problems will go away in the meantime. MSMQ used with transactions works very well in this scenario, and with little help of COM+, database operations can be within the same transaction too.
However the failures are sometimes permanent. For instance when a message says "Update user 1234", but before it's received the user 1234 is deleted from the database. Then that update command will fail. Versioning issues are also common - for example we could send the message serialized with the old version of the class and try to deserialize it with the new version which expects additional field. If we apply the same strategy of rolling back transaction, then that same message will always return to the top of the queue and other pending messages will never be processed.
There are cases in between - a message that will succeed after some delay or after some manual intervention. Technically, a message that could never succeed should be called a poison message, but even if it works after some manual interventions or after too many retries, we can name and treat it as poisonous.
How to detect a poison message?
It's not easy to determine if the failure is transient or permanent. It's usually a good idea to retry the failed message, but not indefinitely. If it doesn't work after a couple of retries something should be done - like send a notification to the admin, move the message to some "poison messages" queue or something else. We'll discuss handling of poison messages later - our first challenge is to determine when the message should not be retried any more.
Using TimeToBeReceived message property
Each message has a TimeToBeReceived property. The default value is InfiniteTimeout but the sender can set that time to something else, like 5 minutes in the future. The best thing about this property is that when that time expires Message Queuing will take care of the message, by deleting it or moving it to dead letter queue. Which of these two happens depends on the UseDeadLetterQueue property.
One problem is in the offline scenario. Application can work without any connection to the main server, in which case the messages are collected and sent when the connection is made available. 5 min timeout will obviously be not good in such a case, but if we can increase that time the poison message can be retried for hours before detecting them. Another, more serious problem is that other pending messages will get older though they are valid and were never retried. As we'll see later, whether this approach is usable depends on the strategy we choose to handle poison messages.
Retry counter
In simple scenarios we need to keep only one retry counter per queue - if we always retry only the last failed message. However in some strategies we try the second message after the first one fails, etc. - we'll have to remember the retry counter for each message that's still in the processing.
In both cases the question is where to keep these counters - in memory, registry, DB or somewhere else? Wherever we put it there's a possibility of resource leak - for instance when the administrator manually deletes the messages and the application still keeps their counters. Another problem is if we keep them in the memory we'll loose all the counters if the application is restarted.
Message modification
Some messaging systems automatically keep the retry count as part of each message but not MSMQ. We can make something like that - for instance we can put the retry count in the AppSpecific property (if we don't use it for other purposes). A major limitation with this is we cannot modify the message that is rolled back - we have to send the message to the back of the queue and commit transaction. This makes it unsuitable for handling strategies.
Exception filter
We can analyze the exception thrown from the processing code. For example if we catch the SerializationException or some custom exception which says something like "couldn't find row 1234 in users table" we know that it is a poison message. However, for some exceptions it's hard to tell if it's a temporary or a permanent problem, and taking care of the fact that all exceptions are treated as they should, is hard and error prone. Therefore exception filtering could be used in combination with some other method as a shortcut to detect at least some positives as early as possible.
External monitoring
An external application or another thread could monitor the queue and raise alarm if the same message stays on top of the queue for too long. It will work if we always return the failed messages back to the top of the queue. The biggest advantage of this method is that it will detect even when our application is not processing any messages, not only the poison messages - may be for some reason our Windows service is not running?
Poison message handling strategies
So far we have covered ways of detecting poison messages. In most cases some retrying was needed. Are there any ways to improve the performance and robustness of our application by different retry strategies? What to do when a message should not be retried any more - should we delete the message or put it somewhere else?
All the handling strategies described here kick in whenever a message fails. It's usually a good idea to log details about why the processing failed and send some notification to the Admin. After the system is fixed you will probably want to delete the poison message or move it back to the queue to be processed again. The problem is that you can't perform these operations from the management console, there is only one operation available - deleting all messages from the queue (purge). You'll have to use some of the existing third party tools or write some utilities yourself to move and delete messages.
We'll start with simpler strategies first.
Discard poison messages
If the primary concern is to process messages as quickly as possible and it's not important if some of the messages are lost, read no more - just drop the poison message and move on. I believe not many people use MSMQ in this fashion.
Always roll back
The simplest message-preserving solution could be not to do anything except roll back - poison message would return to the top of the queue and stay there, potentially forever. This is the simplest solution and there are no risks of loosing a message. It's up to the administrator to fix the problem. Obviously no other messages will be processed in the mean time. Another problem is that after failure we have to make a pause before retry, so even if the message fails only once for some temporary reason we will have delay in processing.
This solution is satisfactory if we want every message to be processed and we don't care when it will be. Also this is the only solution that maintains ordering of messages. On the other hand constant monitoring and manual interventions are unavoidable. This strategy fits nicely with the external monitoring which checks if the same message is on top of the queue for too long.
Retry, move to dead-letter queue
This strategy is an extension of the previous one. After a message fails several times we can move it to some special dead-letter queue. We can put all the poison messages to the system dead-letter queue or make separate dead-letter queue for each queue that we have. What happens if there's some temporary issue? If for instance the connection to some external resource is down, some perfectly valid messages will end up in the dead-letter queue after a couple of retries. They will not be put back to the original queue unless the administrator moves them manually.
Therefore this solution also demands constant monitoring and manual interventions and possibility of having valid messages in the dead-letter queue, but at least the queue can never be blocked for too long.
Send to back
The obvious problem with the previous two strategies is that the failed message goes back to the top of the queue, preventing other messages from processing. What if we could move it to the bottom of the queue after failure? Other messages will have a chance to be processed.
Since roll back returns the message to the top of the queue we cannot use it. We could finish the receive operation (thus removing the message from the top), and send the message again to the queue - which will put it to the bottom. It would be best to have both the Receive and Send in a single transaction.
Special care must be taken with the message priorities - if we send a high priority poison message back to the queue it will nevertheless be in front of older but lower priority messages, blocking them. Therefore, reduce the priority of a poison message to the lowest when it's sent back.
Another problem is that it's hard to detect which message is coming for the first time and which is already retried several times. The easiest way to deal with this is to inject the retry count into the message itself. We can modify the message in any way we want, for MSMQ it's like a completely new message being sent. AppSpecific field is ideal for this purpose and it's used in the sample application.
If only poison messages are in the queue, we will kill our system if we retry them immediately - we will constantly process the same messages in circle. Some delay has to be introduced. One approach is to make a pause when we receive a message that had failed before. These delays inevitably affect the valid messages too.
Separate retry queue
All the solutions discussed so far blocked the main queue at least temporarily. If that's an issue, we could use another queue for retrying and move all the failed messages there immediately. The main queue will never be blocked. Now we also need a separate receiver for the retry queue, which will have delays (using some of the previous strategies), but the valid messages will be processed as soon as possible.
The queued components way
Queued components are part of COM+ which uses MSMQ for transporting remote method invocations. Even if you're not using QC, it's good to know how it works because considerable attention was given to poison messages handling. A combination of separate retry queue and retry, move to dead-letter queue is used.
The general idea is to have more than one retry queue. After a message fails, it is moved to retry queue 1. It's retried there three times with 1 minute pause between each retry. If it doesn't succeed it's moved to retry queue 2, where the delay is 2 minutes. Retry queue 3 will have a delay of 4 minutes, etc. By default five retry queues are used. After a message drops out from the last retry queue it goes to the dead letter queue, where no retries are performed.
Although you can increase or reduce the number of retry queues and what happens before a message is moved to the dead letter queue, you can not affect the number of retries and delays for each queue - so in a default configuration a message will reach the dead letter queue in (1+2+4+8+16)*3=93 minutes. Queued components don't completely solve the problem of valid messages in dead-letter queue, they only reduce it. Manual interventions are still required from time to time.
Also you would have to deal with COM+, but that's inevitable if you want to integrate the database and MSMQ transactions.
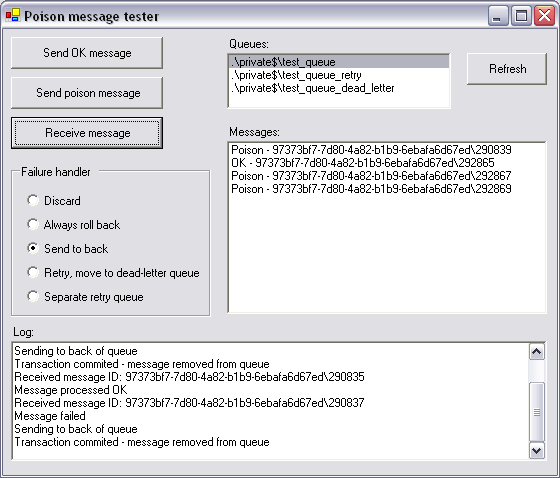
Testing application
You can play with different poison handling strategies in the sample application. You can send valid and poison messages and choose poison handling strategies. Three private transactional queues will be created automatically: test_queue, test_queue_retry, and test_queue_dead_letter. Messages from any of these queues can be seen, so that you can check how the messages are moved between queues.
All the failure handlers implement the IFailedMessageHandler interface:
public interface IFailedMessageHandler
{
TransactionAction HandleFailedMessage(Message message,
MessageQueueTransaction transaction);
}
This method is called any time a message fails. The current transaction is passed as a parameter so that the message can be sent to another queue within the same transaction. Each handler returns what should be performed at the end of the processing - commit or roll back. Architecture like this allows a choice of poison handling strategy at run time. You can also pick strategy for each queue separately.
Conclusion
Optimal poison handling strategy depends on the application requirements - sometimes all the messages are to be handled in the order they come in, or they must be handled as fast as possible even if some of them are lost. There is no ideal solution to the poison message problem - we should be involved when things go wrong. At least we can make sure that bad messages are put aside so that other messages can flow easily. Poison messages could wait in some other queue for the administrator to delete or retry them.
Anyway MSMQ, if used properly, allows our systems to survive various problems and outages. Some additional effort to deal with poison messages shouldn't stop us from using it.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




