Introduction
Disclaimer: This article and source code are not endorsed by Microsoft. Use it at your own risk. You can freely reuse this code.
Microsoft recently (as of February 5, 2006) shipped a preview of their new Internet Explorer release, along with an integrated RSS experience. This includes an RSS store mechanism combined with a documented COM interface.
While Internet Explorer 7 is the default client for this RSS store, I thought it would be interesting to get behind the API and understand how the RSS store works and how to create your own Microsoft RSS store API-free client. The example you can download is the result of the experiments. It's C# .NET code.
You can run this example even without Internet Explorer 7 installed. I have provided a "just in case" folder in the zip file where you'll find a snapshot of my RSS store. Simply copy the contents of this folder into the RSS store location on your hard drive (see below).
RSS Store Inside Out
The RSS store is installed at the same time as Internet Explorer 7 preview bits on XP SP2 machines. No configuration is required. The RSS store has a synchronization engine (the equivalent of a Unix daemon) which I'll talk about later in this article.
The RSS store is a set of OLE documents (a two-decade old technology, which is not cross-platform), and is installed on a per account basis. If your Windows account name is <user>, then the RSS store is stored in C:\Document and settings\<user>\Local Settings\Application Data\Microsoft\Feeds\FeedsStore.feedsdb-ms.

The RSS store
Unlike what the .feedsdb-ms file extension suggests, it can be opened using a standard OLE document viewer, such as the one which comes with Visual Studio (Tools / DocFile Viewer). If you have no Visual Studio installation available, you can download an alternative OLE client here.
Opening FeedsStore.feedsdb-ms, a regular OLE document
The OLE document has a number of streams. The first stores general purpose settings, while all streams whose name begins with @ are actual feed subscriptions. In the screen capture above, I'm subscribed to two feeds. The stream names themselves are irrelevant.
Opening up those streams brings a simple XML schema which governs how the feed will be presented and how it syncs. Some of the most interesting properties include:
<FeedDataCache Path="...">: stores the name and path of the corresponding feed<uiInterval>: client refresh interval<fDownloaded>: whether attached enclosures have been downloaded<Counts>: the number of items stored at this point
Here is a screen capture of one of the feed descriptors, grabbed from the stream @KWKUcVBJEWabDBVUIBbfDFeLHbWD:
A feed descriptor
The <Path> element is critical: it contains both the name of the feed as it appears in the IE7 Favorite side bar, and the fully qualified path which describes the folders in which the feed file actually is. Note that the folders are used to build the IE7 favorite sidebar treeview, and are also actual physical subfolders on the hard drive.
To access the feed, one needs to take the RSS store path, add the content of <Path> after encoding, and add ~.feed-ms to it. The resulting file is another OLE document which can in turn be opened as well. Here is a screen capture of Scobleizer - Microsoft Geek Blogger~.feed-ms opened in the OLE client:
Stored feed items
There are a number of streams, most notably:
- Streams with a numeric name, 0, 1, ..., n - 1, are none other than feed item snapshots.
- A stream named "
Rss". It stores the header of the RSS/Atom feed. This can be useful to grab the encoding charset for instance, as well as some other metadata. - A stream named "
Item data". This stream contains a list of settings for each feed item, most notably whether they are "marked as read". - A stream with a mangled name. It stores the actual feed URL on the internet.
A good citizen feed client should read all of the streams and combine the metadata as appropriate. In sequence, one would read the mangled named stream in order to get the actual URL, then the RSS stream in order to get important header information that will be used to render the feed items, and then the Item data stream which lists all feed items along with their settings. Followed, of course, by all actual streams storing the feed items.
The example I provide for download currently takes a shortcut to this sequence, and simply grabs all streams, storing the feed items in the order they are read.
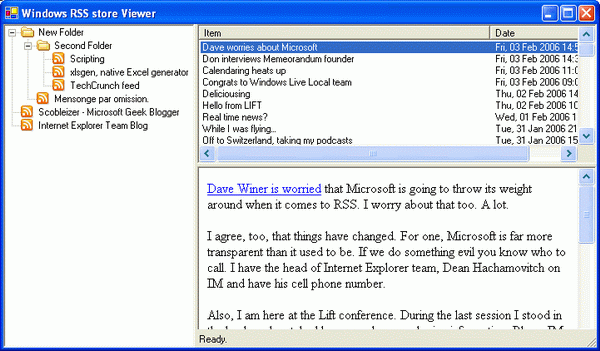
Finally, we need to take a look at what the feed item streams look like. Here is a snapshot of stream 0:
<ItemData>
<item>
<title>Dave worries about Microsoft</title>
<link>http://scobleizer.wordpress.com/2006/02/03/
dave-worries-about-microsoft</link>
<comments>http://scobleizer.wordpress.com/2006/02/03/
dave-worries-about-microsoft#comments</comments>
<pubDate>Fri, 03 Feb 2006 14:50:03 GMT</pubDate>
<author>scobleizer</author>
<atom:author xmlns:atom="http://www.w3.org/2005/Atom">
<atom:name>scobleizer</atom:name>
</atom:author>
<category>RSS</category>
<category>Blog Stuff</category>
<guid isPermaLink="false">http://scobleizer.wordpress.com/
2006/02/03/dave-worries-about-microsoft</guid>
<description type="html"><p><a href="http://www.scripting.com/
2006/02/03.html#itsADifferentWorldToday">Dave Winer is worried</a>
that Microsoft is going to throw its weight around
when it comes to RSS. I worry about that too. A lot.</p>
<p>I agree, too, that things have changed. For one,
Microsoft is far more transparent than it used to be.
If we do something evil you know who to call. I have
the head of Internet Explorer team, Dean Hachamovitch
on IM and have his cell phone number.</p>
<p>Also, I am here at the Lift conference.
During the last session I stood in the back and watched
how people were sharing information. Blogs. IM. Email.
All live. People are so connected now. If we do something
evil it spreads around the world within an hour.
Or even faster.</p>
<p>Finally, it takes minutes for this connected world
to figure out whether something is good or not.
If it isn’t you’ll know and know in a violent manner.</p>
<p>What does this mean? First, if we don’t work with
the community we’ll fail. Second, if we don’t have
the best products and services, we’ll fail.
Third, if we take too long to react to market
demands we’ll be left out of the conversation
and rendered irrelevant.</p>
<p>Hint: I am using <a href="http://scripting.wordpress.com/
2006/02/02/scott-they-need-a-river-2/">Dave Winer’s
aggregator</a>. That said, I wish Dave’s aggregator told
the RSS platform when I read a post so that other RSS reading
apps on the system (I have several) will know that I read
an item already.</p>
</description>
<atom:summary xmlns:atom="http://www.w3.org/2005/Atom"
type="html">Dave Winer is worried that Microsoft
is going to throw its weight around when it comes
to RSS. I worry about that too. A lot. I agree, too,
that things have changed. For one, Microsoft is far
more transparent than it used to be. If we do something
evil you know who to call. I have [...]</atom:summary>
<wfw:commentRSS xmlns:wfw="http://wellformedweb.org/CommentAPI/">
http://scobleizer.wordpress.com/2006/02/03/
dave-worries-about-microsoft/feed
</wfw:commentRSS>
</item>
<Url>http://scobleizer.wordpress.com/feed</Url>
</ItemData>
Note that the feed item is contained within an <ItemData> element which is added by the RSS store. Both RSS schema version x.y and Atom schema version x.y feeds follow those rules.
In practice, unless you are interested in making sense out of all the XML elements, it really does not matter much. After all, RSS and Atom schemas are close enough to let one build a client without much time to spend into it. What my example code does is use the .NET XML subscriber-like parser to grab the following elements:
<title>: the feed item title itself<pubDate>: optional, the publication date<link>: optional, the link to the actual online blog post<description>: the feed item body
And that's pretty much it!
Additional information is available for path and name encoding. When you try to access a feed's file, such as Scobleizer - Microsoft Geek Blogger~.feed-ms, from the <Path>, you need to pay special attention to some encodings used to map paths and names to actual hard drive files (I don't know why Microsoft invented another layer of proprietary encoding here while the standard URL encoding scheme would have worked just fine):
- any . (dot) character in
<Path> should be replaced by ~d - any : (colon) character in
<Path> should be replaced by ~c - any \ (backslash) character in
<Path> should be replaced by ~\ - I am pretty sure there are other replacements, but other characters like apostrophes and commas are not replaced. Let me know if you find a combination not documented here yet.
Building a Client
The example is a C# project with the following files:
- FeedViewer.cs: the UI on top of the feed store retrieval code
- FeedStore.cs: the code used to open the main OLE document and expose feeds to a client
- Feed.cs: the code used to represent a feed itself
- FeedItem.cs: the code used to represent a feed item itself
- NativeCalls.cs: the
IStorage/IStream calls used to read OLE documents
If you'd like to reuse this code, then you really can take the non-UI files and use them as an "RSS store API". Alternatively, you may want to use the official Microsoft RSS store API though.
Reading an OLE document is essentially not .NET friendly. An OLE document uses the COM IStorage/IStream interfaces to expose a hierarchy of fictitious sub-folders and sub-files in a given file. Microsoft uses an OLE document for the feed store itself, and then a separate OLE document for all feeds. All combined is what they call the RSS store, but it's physically a bunch of folders and OLE files in it. In order to read an OLE document, one must use the IStorage/IStream interfaces implemented in the OLE32.dll, or get away with it with Wine or OLE API replacements (Apache POI for Java, on Mac OSX, Linux, ...). The IStorage interface is not publicly re-exposed in the .NET framework, so this must be done. To make things easier, the www.pinvoke.net website has done this work for us already. The IStream interface is already re-exposed though, and its name is UCOMIStream. Since we'll execute native code, the permission for doing this must be granted, hence the permission.Demand() call made in the initialization phase.
When reading the main feed store file, the streams are enumerated and then the actual parsing work is delegated to the appropriate objects. The Feed class is the only class that knows how to deal with a feed stream (whose name begins with @). By analogy, the FeedItem class is the only class that knows how to deal with feed item streams (streams with a numeric name).
Reading those OLE documents allows to populate collections of Feed and FeedItem objects which are exposed by the FeedStore class by index or name.
On the UI side of things, the folders used to build a treeview on the left hand side are stored in the Feed class. A simple string split lets us build the tree recursively. We put a wait cursor and block the treeview Win32 window update to avoid any flicker. The treeview has a context menu with a Refresh option, which essentially wipes the collection and does the reading work again. In other words, when you click Refresh, it's doing an online Refresh, it's grabbing what's available from the RSS store, and it's up to the IE7 synchronization engine to update the RSS store, separately.
The feedstore is read when the UI is initialized. At this point, we can build the tree of feeds, but we haven't read the feeds. This happens on-demand (only if required) whenever the user clicks a treeview item. And the associated OLE document to the feed is read, and the feed items are read and stored in memory.
The listview on the right hand side is populated using the feed item titles and publication dates. It's sortable to accommodate typical needs. When right-clicking a feed item, you can open the actual online link associated to the feed item. This works whenever applicable. In fact, a feed item is apparently not required to have a <link> element, although I guess a fallback scenario would be to grab the <guid>, which apparently is also optional.
Once a feed item is clicked, we grab the accompanying body (<description>) element, then enclose it in a rudimentary HTML mark-up tag so that the web browser control understands its HTML. We create a temporary filename, store the content in it, and then ask the web browser control to show it by issuing a Navigate call. All of this is a matter of a few lines of code.
It's very clear from the above that what the example code does is read the feeds. It never edits them, deletes them, or adds a new feed. That'd be a nice addition to it, however. Feel free to contribute!
Using the API
Accessing Feed Names
FeedStore fs = new FeedStore();
fs.Refresh();
foreach(Feed f in fs.Feeds())
{
string [] pathsplit = f.Path.Split(new Char [] {'\\'});
String name = pathsplit[pathsplit.Length - 1];
}
Accessing a Feed's Content
Feed f = fs[i];
f.Open(fs.FeedStorePath);
String path = f.Path;
int nbitems = f.Items.Count;
foreach (FeedItem fi in f.Items)
{
...
}
Accessing a Feed Item
Feed f = fs[i];
f.Open(fs.FeedStorePath);
foreach (FeedItem fi in f.Items)
{
}
Why Use the API
Currently, this API is fully .NET (unlike the official API which uses tlbimp to interop the COM-based API) and has clear shortcomings in the sense that it only reads the RSS store. That said, it will reflect any update from the RSS store, which is after all what a generic client would expect.
Nice additions to it would be the ability to add/edit/delete feeds. Again, this would work through the IStorage/IStream mechanism.
The RSS Store Synchronization Engine
By default, feeds in the RSS store are synched automatically using a scheduled mechanism. There is a general option available from the IE7 toolbar which lets you uncheck this option. Against all odds, this works even without IE7 started. Magic!
Actually, the engine is a COM object called msfeeds.dll which is registered so as to be both a Windows Explorer add-on and a IE7 add-on. The SysInternals Process Explorer reveals it:
The reason why the RSS synchronization engine works without IE7 started.
Since Windows Explorer always run on the desktop, this provides both a general purpose synchronization mechanism, as well as an unexpected conduit.
Why OLE?
One can only wonder why they have chosen OLE as their store foundation, especially when there are separate OLE documents being created for every single feed. Aside that, the general performance of your system may be greatly reduced during a synchronization as a side effect of automatic anti-virus sniffing. Anytime a file gets touched, one wonders why a single OLE document is not used (after all, the hierarchy inside can store all feeds and all feed items in the same place). Or why they are not using ZIP, now that it's supposed to be the solution to all file format problems (pun intended). How well this is going to work across platforms (remote sync) remains to be seen.
History
- February 5, 2006 - Article first published
License
This article has no explicit license attached to it, but may contain usage terms in the article text or the download files themselves. If in doubt, please contact the author via the discussion board below.
A list of licenses authors might use can be found here.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




