Introduction
The article provides an implementation of the simple problem using both Pipes-and-Filters architectural pattern and Decorator pattern, and explores a relationship between them, if any.
Pipes-and-Filters Pattern - An architectural design pattern
Intent
The Pipes and Filters architectural pattern provides a structure for systems, having components that process a stream of data (filters) and connections that transmit data between adjacent components (pipes). This architecture provides reusability, maintainability, and decoupling for the system processes having distinct, easily identifiable, and independent but somehow compatible tasks.
The usage of Pipes and Filters pattern is limited to systems where the order in which filters are processed is strongly determined and sequential in nature. The pattern applies to problems where it is natural to decompose the computation into a collection of semi-independent tasks. In the Pipeline pattern, the semi-independent tasks represent the stages of the pipeline, the structure of the pipeline is static, and the interaction between successive stages is regular and loosely synchronous. A pipeline is a definition of steps/tasks that are executed to perform a business function. Each step may involve reading or writing to data confirming the “pipeline state,” and may or may not access an external service. When invoking an asynchronous service as part of a step, a pipeline can wait until a response is returned (if a response is expected), or proceed to the next step in the pipeline if the response is not required in order to continue processing.
Use the pipeline pattern when:
- You can specify the sequence of a known/determined set of steps.
- You do not need to wait for an asynchronous response from each step.
- You want all downstream components to be able to inspect and act on data that comes from upstream (but not vice versa).
Advantages of the pipeline pattern include:
- It enforces sequential processing.
- It is easy to wrap it in an atomic transaction.
Disadvantages of the pipeline pattern include:
- The pattern may be too simplistic to cover all cases in business logic, especially for service orchestration in which you need to branch the execution of the business logic in complex ways.
- It does not handle conditional constructs, loops, and other flow control logic as it's mostly sequential in nature.
Background
Filters
The filters are the processing units of the pipeline. A filter may enrich, refine, process, or transform its input data.
- It may refine the data by concentrating or extracting information from the input data stream and passing only that information to the output stream.
- It may transform the input data to a new form before passing it to the output stream.
- It may, of course, do some combination of enrichment, refinement, and transformation.
A filter may be active (the more common case) or passive.
- An active filter runs as a separate process or thread; it actively pulls data from the input data stream and pushes the transformed data onto the output data stream.
- A passive filter is activated by either being called:
- as a function, a pull of the output from the filter.
- as a procedure, a push of output data into the filter.
Pipes
The pipes are the connectors having the following links between a data source and the first filter, between filters, between the last filter and a data sink. As needed, a pipe synchronizes the active elements that it connects together.
Data source
A data source is an entity (e.g., a file or input device) that provides the input data to the system. It may either actively push data down the pipeline or passively supply data when requested, depending upon the situation.
Data sink
A data sink is an entity that gathers data at the end of a pipeline. It may either actively pull data from the last filter element or it may passively respond when requested by the last filter element.
Implementation Details
We may consider the generic filter as a component that processes data. The IComponent basic interface could be defined as follows:
public interface IComponent<T>
{
bool Process(T t);
}
Throughout the sample, I used ‘T’ as a generic type parameter. InputStream and OutputStream are interfaces used for the input and the output streams.
public interface InputStream<T> : IEnumerable<T>
{
bool Available();
T Read();
ulong Read(out T[] Data, ulong offset, ulong length);
void Reset();
void Skip(ulong offset);
}
public interface OutputStream<T>
{
void Flush();
void Write(T data);
void Write(T[] Data);
void Write(T[] Data, ulong offset, ulong length);
}
public interface IStreamingControl<T>
{
InputStream<T> Input
{
get; set;
}
OutputStream<T> Output
{
get; set;
}
InputStream<T> FactoryInputStream();
OutputStream<T> FactoryOutputStream();
}
Now, define the concrete implementation class StreamingControlImpl which implements the IStreamingControl as:
public class StreamingControlImpl<T> :
IStreamingControl<T> where T : new()
public interface IComponentStreaming<T> :
IComponent<StreamingControlImpl<T>> where T : new()
{
bool Process(InputStream<T> input, OutputStream<T> output);
}
public abstract class InputSource<T> :
StreamingComponentBase<T> where T : new()
{
public const bool isOutputSink = false;
public abstract bool Process(OutputStream<T> output);
public override bool Process(InputStream<T> input,
OutputStream<T> output)
{
foreach (T t in input)
output.Write(t);
return Process(output);
}
}
public abstract class OutputSink<T> :
StreamingComponentBase<T> where T : new()
{
public const bool isOutputSink = true;
public abstract bool Process(InputStream<T> input);
public override bool Process(InputStream<T> input,
OutputStream<T> output)
{
return Process(input);
}
}
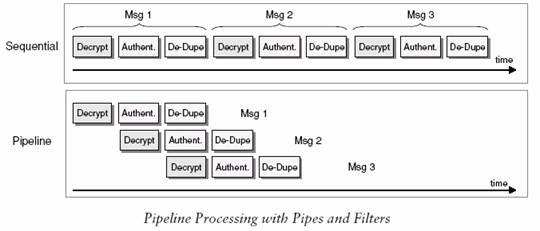
We can have two processing types: sequential processing and pipeline processing. Connecting components with asynchronous pipes allows each unit in the chain to operate in its own thread or its own process. When a unit has completed processing one filter, it can send the data to the output stream and immediately start processing another data. It does not have to wait for the subsequent components to read and process the data. This allows multiple data messages to be processed concurrently as they pass through the individual stages. For example, after the first message has been decrypted, it can be passed on to the authentication component. At the same time, the next message can already be decrypted. We call such a configuration a processing pipeline because messages flow through the filters like liquid flows through a pipe. When compared to strictly sequential processing, a processing pipeline can significantly increase system throughput. Here, I only discuss sequential processing.
The pipeline interface is defined as:
public interface IPipeline<T>
{
void AddLink(IComponent<T> link);
bool Process(T t);
}
LinearPipeline is the IPipeline implementation that can process filters sequentially. There are two ways to process the filters in the order defined by the following enumerator:
public enum OPTYPE { AND, OR };
If processing of any filter in the pipeline fails and/or returns false, the processing stops without executing the preceding filters, and the pipeline returns false to the caller program. So the pipeline processing with the AND operator is as follows:
if (_optype == OPTYPE.AND)
{
result = true;
foreach (IComponent<T> link in _links)
{
if (! link.Process(t))
{
result = false;
break;
}
}
}
If the processing of any filter in the pipeline returns true, the pipeline returns true to the caller program. The pipeline continues to process each filter regardless of the result obtained in processing the filters. The pipeline processing with the OR operator is as follows.
if (_optype == OPTYPE.OR)
{
result = false;
foreach (IComponent<T> link in _links)
{
if (link.Process(t))
{
result = true;
}
}
}
Different filters do different jobs, hence are implemented as different classes. Here is the list of five filters in the pipeline:

LoadFileFilter reads the program text (i.e., source code) from a file (or perhaps a sequence of files) as a stream of characters, and recognizes a sequence of tokens. It is not very efficient to read a character at a time, since file IO operations are slow. Therefore, we can read a file at a time using a StreamReader. The class Tokens is an iterator tokenizer that uses either commas or semicolons and spaces to divide into tokens.
StartWithSearchFilter gets data stream from LoadFileFilter and sinks the words which start with the keyword provided as the parameter.
WordLengthSearchFilter gets data stream from StartWithSearchFilter and sinks the words having length less than or equal to the maximum value provided as the parameter.
PlaindromeSearchFilter gets a data stream from WordLengthSearchFilter and sinks the words that are palindrome in nature.
Output is used to display the results to the user.
The following class describes the implementation of the LoadFileFilter task:
internal class LoadFileFliter : InputSource<Item>
{
private string _path;
public LoadFileFliter(string path)
{
_path = path;
}
public override bool Process(OutputStream<Item> output)
{
try
{
if (File.Exists(_path))
{
string buffer;
using (StreamReader sr = new StreamReader(_path))
{
buffer = sr.ReadToEnd();
}
buffer = buffer.Replace("\r\n", " ");
Tokens Tokenizer = new Tokens(buffer, new char[] { ' ', ';', ',' });
foreach (string Token in Tokenizer)
{
if (Token == string.Empty) continue;
System.Diagnostics.Debug.Write(Token);
output.Write(new Item(Token));
}
return true;
}
else
throw new Exception("File could not be read");
}
catch (Exception ex)
{
System.Diagnostics.Debug.Write(ex.Message);
}
return false;
}
}
As every filter exposes a very simple interface, it receives messages on the inbound pipe, processes the message, and publishes the results to the outbound pipe. The pipe connects one filter to the next, sending output messages from one filter to the next. Because, all components use the same external interface.
They can be composed into different solutions by connecting the components to different pipes. We can add new filters, omit existing ones, or rearrange them into a new sequence—all without having to change the filters themselves. Here is the major Invoke class that prepares an order of filters into a pipeline and processes it:
public static void Invoke()
{
LinearPipeline<StreamingControlImpl<Item>> pipeline =
new LinearPipeline<StreamingControlImpl<Item>>();
pipeline.AddLink(Factory<Item>.CreateLoadFile(@"c:\a.log"));
pipeline.AddLink(Factory<Item>.CreateStartWithSearch("wa"));
pipeline.AddLink(Factory<Item>.CreateWordLengthSearch(9));
pipeline.AddLink(Factory<Item>.CreatePalindromeSearch());
pipeline.AddLink(Factory<Item>.CreateOutput());
StreamingControlImpl<Item> controldata =
new StreamingControlImpl<Item>();
bool done = pipeline.Process(controldata);
if (done)
System.Diagnostics.Debug.Write("All filters " +
"processed successfully");
}
While reading a file and tokenizing it to prepare stream data, I want to use the “string” native data type to be passed as the type parameter but using StreamingControlImpl<string> generates a compiler error as the constraint where T : new() on every level of upward hierarchy requires a parameter-less constructor for type “string”. Since string does not have a parameter-less constructor and it is a sealed class, we cannot inherit a class from string. To solve this problem instead of having a is-a relationship, we can implement a new class Item having a has-a relationship and can get the value using the Item.Text property! No big deal:
internal class Item
{
private string _text = null;
public string Text
{
get { return _text; }
set { _text = value; }
}
public Item()
{
_text = string.Empty;
}
public Item(string t)
{
_text = t;
}
}
The following class diagram explains the whole concept of the Pipes and Filters architecture:
Liabilities of Pipes and Filters
The pipes-and-filters architectural pattern has the following liabilities [Buschmann]:
- Sharing state information is expensive or inflexible. The information must be encoded, transmitted, and then decoded.
- Efficiency gain by parallel processing is often an illusion. The costs of data transfer, synchronization, and context switching may be high. Non-incremental filters, such as the Unix
sort, can become the bottleneck of a system.
- Data transformation overhead. The use of a single data channel between filters often means that much transformation of data must occur, for example, translation of numbers between binary and character formats.
- Error handling. It is often difficult to detect errors in pipes-and-filters systems. Recovering from errors is even more difficult.
Decorator Pattern - An alternative or related to Pipes-and-Filters
Intent
Attach additional responsibilities to an object dynamically, without using subclassing. The key to a decorator is that a decorator "wraps" the object decorated and looks to a client exactly the same as the object wrapped. This means that the decorator implements the same interface as the object it decorates.
Any message that a client sends to the object goes to the decorator. The decorator may apply some processing and then pass the message it received on to the decorated object. That object probably returns a value (to the decorator) which may again apply some processing to that result, finally sending the (perhaps modified) result to the original client. This decorator story is transparent to the calling client. It just sent a message and got a result.
Implementation Details
For example, suppose that we would like to solve all of the above problems from the Pipes and Filters section by using Decorator instead. We could change the above code arrangement accordingly. So we would create a SearchDecorator as an abstract class that takes an IComponent (filling the purpose of ISearch actually) interface as a parameter in its constructor and will itself implement the IComponent interface. The following diagram describes the concept:
Like Pipes and Filters, we may consider the basic interface as IComponent defining the Process method, that is:
public interface IComponent<T>
{
IEnumerable<T> Words { get; }
bool Process();
}
As we don’t have the concept of streams here to carry and transfer data across filters, we may define an iterator Words in IComponent to keep the searched words. SearchDecorator is defined as:
public abstract class SearchDecorator<T> :
IComponent<T> where T: new()
{
protected IComponent<T> _ancestor;
public SearchDecorator(IComponent<T> ancestor)
{
_ancestor = ancestor;
}
public virtual bool Process()
{
return _ancestor.Process();
}
public virtual IEnumerable<T> Words
{
get
{
return _ancestor.Words;
}
}
}
public class StartWithSearch : SearchDecorator<Item>
{
private string _keyword;
private IEnumerable<Item> _words;
public StartWithSearch(IComponent<Item> ancestor, string keyword)
: base(ancestor)
{
_keyword = keyword;
_ancestor = ancestor;
}
public override bool Process()
{
_ancestor.Process();
System.Diagnostics.Debug.Write(_keyword);
_words = CreateEnumerator();
return true;
}
IEnumerable<Item> CreateEnumerator()
{
foreach (Item Token in _ancestor.Words)
{
if (Token.Text == string.Empty) continue;
if (Token.Text.StartsWith(_keyword))
{
System.Diagnostics.Debug.Write(Token.Text);
yield return Token;
}
}
}
public override IEnumerable<Item> Words
{
get
{
return _words;
}
}
}
The calling program uses the decoration of search in the following ways:
IComponent<Item> S = new FileLoader(".log");
S = new StartWithSearch(S, "ma");
S = new WordLengthSearch(S, 5);
S = new PalindromeSearch(S);
S = new Output(S);
S.Process();
Comparisons
Benefits of Pipes-and-Filters
The pipes-and-filters architectural pattern has the following benefits [Buschmann]:
Benefits of Decorator
The Decorator pattern has the following benefits:
Conclusions
I implemented the same problem using both Pipes-and-Filters architectural pattern and Decorator pattern. The basic idea that encourages me is the dynamic arrangement of filters on one side and dynamic pluggablility of responsibilities (wrappers) on the other side. If I don’t talk about parallel pipeline processing in pipes-and-filters, you can see how pipes-and-filters with sequential processing maps to the decorator pattern exactly. So they may be related patterns in a sense that in Pipes-and-Filters, pipes are stateless and serve as conduits for moving streams of data across multiple filters, while filters are stream modifiers which process the input streams and send the resulting output stream to the pipe of another filter, and in the Decorator pattern we can see decorators as filters.
History
- First version: February 13, 2006.
References
For more information on Pipes-and-Filters architectural pattern implementation, I recommend the following book:
- Foundations of Object-Oriented Programming Using .NET 2.0 Patterns. Christian Gross. Apress, 2005, ISBN 1-59059-540-8.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




