Introduction and Motivation
A few weeks ago I decided to build a web crawler. Not a trivial one that would simply ignore the size and issues of current Internet. After all, those are the most interesting challenges of the task.
A very common feature of web crawlers is the
URL-seen test. As the name suggests, it is responsible for classifying a link extracted from a document as
unique or
duplicate. In an usual scenario, the latter is discarded while the former is eligible for further processing and will be eventually added to the download queue. Naturally, there might be aspects like filtering or continuous crawling that also have influence over the process, but they are not relevant here.
I initially thought that the URL-seen implementation would be straightforward. Everything I needed was a good hash table and a good hash function. Well... I was wrong. Unless you have unlimited resources, this is not an efficient and scalable solution. Once you reach the millions and billions of URLs, it is just too much RAM. Do your calculations.
By that time, it was clear to me that I would have to persist data on disk. However, doing so for every URL check is too expensive. Therefore, I was heading towards some kind of asynchronous batch operation. Then, searching a little bit about the subject, I ended up on the following paper published at the WWW Conference 2008: IRLbot: Scaling to 6 Billion Pages and Beyond.
Among other topics, this papers discusses known methods used for the URL-seen test and presents a new technique that achieves close to the best theoretical result for very large data sets. This technique, which is called DRUM (Disk Repository with Update Management), is based on a combination of RAM and disk through a bucket sort strategy.
In this article, although I provide a brief overview of DRUM's working principle, I do not explain the theory behind it. I am particularly interested in the implementation details, a matter that is not mentioned in the original paper. In fact, even the description of the DRUM is a relatively small part of it. Thus, the code I distribute and the comments I make reflect my own understanding and interpretation.
My implementation is generic in the same sense of the STL (Standard Template Library). You can use it with any data type as long as they satisfy some requirements. The code is supposed to be portable, even though I have only run it on Ubuntu/GCC 4.2.4. I use standard C++ and a couple of open-source libraries: Boost and Berkeley DB - If you wish to use the code you need to download and install them. I should also make it clear that I did not perform any kind of benchmarking or performance evaluation. I have also not used it under stressful conditions yet. (I plan to do all these when I finish my crawler.) Of course, there are no warranties, but I would really appreciate that you let me know in the case you find any bugs or have constructive feedback.
If you think the article needs improvement, please use the message board at the bottom of the page. Just keep in mind that I do expect knowledge of C++ (in particular, related to templates) and algorithms/data structures in general (hashing, trees, etc.). The focus is in distributing the source-code (in the hope it can be useful for others) and explaining the design decisions.
Understanding DRUM
All mathematical modeling of DRUM was introduced in IRLbot: Scaling to 6 Billion Pages and Beyond. However, no lower level details are available. Also, during the transition from theory to practice there is still a gap that needs to be filled by a programmer's imagination and adaptation. Since this text is the "big picture" of how I have implemented DRUM, I suggest the reader to refer to the original paper for a longer presentation.
DRUM (Disk Repository with Update Management) is a technique for efficient storage of key/value pairs and asynchronous check/update operations. In addition to the URL-seen test existent in many web crawlers, it can also be used for robots.txt compliance and DNS cache. Three operations are supported:
- check - A key is checked against those in the disk repository and classified as unique or duplicate. If the key is a duplicate, its associated value can be retrieved.
- update - A key and its associated value are merged into the disk repository. If the key was already there, only its value is updated.
- check + update - A combination of the previous ones. A key is classified as unique or duplicate and a merge is performed.
For all operations, it is possible that an auxiliary piece of data is supplied together with the key/value pair. This is necessary because DRUM is asynchronous. By the time you get the result of a check operation, for example, you might no longer be in the same context from when you requested it.
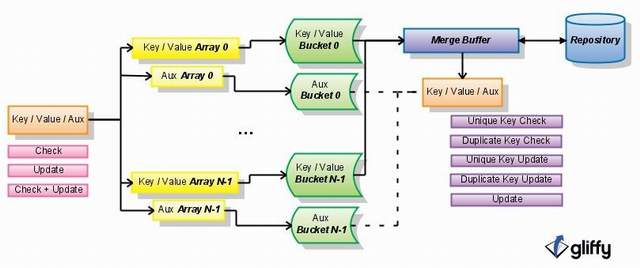
DRUM can be subdivided into three major components. One of them is a set of arrays which are organized through a bucket strategy based on the key value. There is an array subset responsible for storing the key/value pairs and another for the auxiliaries. Input received through the DRUM interface is inserted into the arrays.
Once any of the arrays is filled, their values are transferred to corresponding disk buckets - again, the key/value pairs and the auxiliaries are written to different subset of buckets. The arrays, which are now empty, continue to receive input and the process goes on until one of the disk buckets reaches a predetermined size threshold. This indicates that it is merge time.
The last component is a sorted persistent repository. During merge a key/value bucket is read into a separate buffer and sorted. Its content is synchronized with that of the persistent repository. Checks and updates happen at this moment. Afterwards, the buffer is re-sorted to its original order so that key/value pairs match again the corresponding auxiliary bucket. A dispatching mechanism then forwards the key, value and auxiliary for further processing along with the operation result. This process repeats for all buckets sequentially.
There is one thing I would like to make very clear. Both the array sets and the disk buckets sets are organized in buckets that are identified by key values and that are not sorted internally. Sorting is done only when a particular disk bucket is read into memory just before the merge stage. This allows an efficient synchronization of all buckets with the persistent repository (which is sorted) in only a single pass through it. The figure below illustrates the DRUM components.
Implementation Design
The major part of the DRUM interface is pretty obvious from the introduction above. At least three methods are necessary: check, update, and check + update. But what kind of types do they operate on? Yes, templates are beautiful and a powerful feature of C++. That is why DRUM is implemented by a class template. Its name is Drum.
Of course, three template parameters are easy to infer: one for the key type; other of the value type; a third for the auxiliary type. Furthermore, I also enforced other characteristics of DRUM by using non-type template parameters. In particular, I am talking about the number of buckets (remember that each bucket has a corresponding array), the maximum number of elements in the arrays, and the disk buckets byte size. There is still one template parameter left, but I will not mention it now. So far, Drum class template looks like this:
template <
class key_t,
class value_t,
class aux_t,
std::size_t num_buckets_nt,
std::size_t bucket_buff_elem_size_nt,
std::size_t bucket_byte_size_nt,
>
class Drum
{
};
Template arguments for key_t, value_t, and aux_t must satisfy some requirements. I did not take the time to formally specify a concept for them to model, but the idea is quite simple. key_t must be Less Than Comparable. (One might wonder why the comparison is not parameterized like in std::map. This is because I do not see how any other behavior different than std::less could be used in this implementation.) All three types must be Default Constructible and Assignable. They must also support serialization and deserialization in order to be written to and read from the disk buckets. For this purpose, I expect that a valid and correct template instantiation of the following class template exists:
template <class element_t>
struct ElementIO
{
static void Serialize(element_t const& element,
std::size_t & size, char const* & serial)
{
size = sizeof(element_t);
serial = reinterpret_cast<char const*>(&element);
}
static void Deserialize(element_t & element, std::size_t size, char const* serial)
{
element = reinterpret_cast<element_t const&>(*serial);
}
};
If the above definition does not fit well your type, a specialization of ElementIO is needed. Here is one for std::string.
template <>
struct ElementIO<std::string>
{
static void Serialize(std::string const& element,
std::size_t & size, char const* & serial)
{
size = element.size();
serial = element.c_str();
}
static void Deserialize(std::string & element, std::size_t size, char const* serial)
{
element.assign(serial, serial + size);
}
};
Arrays and disk buckets are identified by a number from 0 to num_buckets_nt - 1. The DRUM needs to know the array where to store arriving data and the disk buckets where to write data from the arrays. It is your responsibility to map a key value to an id. The implementation cannot do it by itself. There are too many possibilities given that both the key type and the number of buckets are template parameters. Therefore, I use the same strategy as for the serialization/deserialization. A valid and correct template instantiation of BucketIdentififer must exist. The difference is that this time I only declared the class template and did not define it. After all, what could be a general form of it?
Still, you need to know how BucketIdentifier looks like and should behave. As an example, I show specializations for keys of type boost::uint64_t and number of buckets that are a power of two. Member function Calculate returns the bucket id (which is also the array id).
template <class key_t, std::size_t num_buckets_nt>
struct BucketIdentififer;
...
template <>
struct BucketIdentififer<boost::uint64_t, 2>
{
static std::size_t Calculate(boost::uint64_t const& key)
{
boost::uint64_t mask = 0x8000000000000000LL;
boost::uint64_t bucket = mask & key;
return static_cast<std::size_t>(bucket >> 63);
}
};
template <>
struct BucketIdentififer<boost::uint64_t, 4>
{
static std::size_t Calculate(boost::uint64_t const& key)
{
boost::uint64_t mask = 0xC000000000000000LL;
boost::uint64_t bucket = mask & key;
return static_cast<std::size_t>(bucket >> 62);
}
};
template <>
struct BucketIdentififer<boost::uint64_t, 8>
{
static std::size_t Calculate(boost::uint64_t const& key)
{
boost::uint64_t mask = 0xE000000000000000LL;
boost::uint64_t bucket = mask & key;
return static_cast<std::size_t>(bucket >> 61);
}
};
template <>
struct BucketIdentififer<boost::uint64_t, 16>
{
static std::size_t Calculate(boost::uint64_t const& key)
{
boost::uint64_t mask = 0xF000000000000000LL;
boost::uint64_t bucket = mask & key;
return static_cast<std::size_t>(bucket >> 60);
}
};
Now, a very important observation. The persistent repository is implemented as a Berkeley DB database with BTree access. By default, Berkeley DB uses raw byte strings as keys for the BTree comparison function. Sometimes, this is not desired. In a generic implementation like Drum, it is necessary to supply a comparison function that is consistent with the way by which the bucket numbers are calculated. During merge all buckets from 0 to num_buckets_nt - 1 are synchronized with the contents of the persistent repository. In order to be efficient, iteration over the keys from these buckets should match a natural order of iteration over the keys in the Berkeley DB database.
A BTree comparison function is easy to write. You need to know just a bit of Berkeley DB interface and one rule: the function must return a positive number if a is larger than b; a negative number if a is smaller than b; zero if they are equal. For example:
int Compare(Db* db, Dbt const* a, Dbt const* b)
{
int ai;
int bi;
std::memcpy(&ai, a->get_data(), sizeof(int));
std::memcpy(&bi, b->get_data(), sizeof(int));
return (ai - bi);
}
Notice that the specializations of BucketIdentififer above assign small bucket numbers for smaller keys and large bucket numbers for larger keys. For instance, if you parameterize Drum with 4 buckets, the compiler will select specialization BucketIdentififer<boost::uint64_t, 4>. In this case, the smaller keys are placed in bucket 0 while the larger keys are placed in bucket 3 (others in buckets 1 and 2). When buckets are traversed and synchronized with the persistent repository, there will be a high level of locality in the queries submitted to Berkeley DB. This means fast access with not much I/O because Berkeley DB offers an in-memory transparent cache for frequently used keys.
How DRUM can be configured to use your comparison function? Again, the answer relies on template specialization. In fact, it is very similar to the other cases. This time you need to provide an specialization of class template BTreeCompare. Here is the code for boost::uint64_t.
template <class key_t>
struct BTreeCompare;
...
template <>
struct BTreeCompare<boost::uint64_t>
{
static int Compare(Db* db, Dbt const* a, Dbt const* b)
{
boost::uint64_t ai;
boost::uint64_t bi;
std::memcpy(&ai, a->get_data(), sizeof(boost::uint64_t));
std::memcpy(&bi, b->get_data(), sizeof(boost::uint64_t));
if (ai > bi) return 1;
if (ai < bi) return -1;
return 0;
}
};
Time to get back to the last template parameter of Drum - technically, it is more than that as you will see. At some point, you need to know what the results of the operations are. Drum achieves this through a Visitor-like mechanism. I simply call it the DRUM dispatcher. It is a type with member functions for every possible result from one of the check, update, and check + update operations. Below, I show a dummy example that prints the key, value, and auxiliary values. You can look at it as an archetype for the Drum Dispatcher concept.
template <class key_t, class value_t, class aux_t>
struct DummyDispatcher
{
void UniqueKeyCheck(key_t const& k, aux_t const& a) const
{std::cout << "UniqueKeyCheck: " << k << " - Aux: " << a << "\n";}
void DuplicateKeyCheck(key_t const& k, value_t const& v, aux_t const& a) const
{std::cout << "DuplicateKeyCheck: " << k << " - Value: "
<< v << " - Aux: " << a << "\n";}
void UniqueKeyUpdate(key_t const& k, value_t const& v, aux_t const& a) const
{std::cout << "UniqueKeyUpdate: " << k << " - Value: "
<< v << " - Aux: " << a << "\n";}
void DuplicateKeyUpdate(key_t const& k, value_t const& v, aux_t const& a) const
{std::cout << "DuplicateKeyUpdate: " << k << " - Value: "
<< v << " - Aux: " << a << "\n";}
void Update(key_t const& k, value_t const& v, aux_t const& a) const
{std::cout << "Update: " << k << " - Value: " << v << " - Aux: " << a << "\n";}
};
You have probably noticed that DummyDispatcher is a class template. It depends on some types. For this reason, the last template parameter of Drum is actually a template template parameter. (The double template words are not a typo, in the case you are beginning in C++.) Finally...
template <
class key_t,
class value_t,
class aux_t,
std::size_t num_buckets_nt,
std::size_t bucket_buff_elem_size_nt,
std::size_t bucket_byte_size_nt,
template <class, class, class> dispatcher_t = NullDispatcher>
class Drum
{
typedef dispatcher_t<key_t, value_t, aux_t> DispatcherType;
public:
Drum(std::string const& name);
Drum(std::string const& name, DispatcherType const& dispatcher);
void Check(key_t const& key);
void Check(key_t const& key, aux_t const& aux);
void Update(key_t const& key, value_t const& value);
void Update(key_t const& key, value_t const& value, aux_t const& aux);
void CheckUpdate(key_t const& key, value_t const& value);
void CheckUpdate(key_t const& key, value_t const& value, aux_t const& aux);
};
Quick Facts
Drum is not thread-safe. In a multi-threaded environment, you should handle concurrency around your calls.- Since
Drum is kind of a container, it is advisable that key_t, value, and aux_t are cheap to copy. - The internal arrays are implemented with
boost::array. - Key, value, auxiliary, and other information are held in a
boost::tuples::tuple. - Files for the disk buckets must exist prior to execution. Preallocate them with according size for better performance.
- Unexpected behaviors cause either a
DrumException or a std::exception to be thrown. Drum's destructor does not throw. - All three operations have an overload that accepts an
aux_t data. - There are a couple of
Drum constructors which take Berkeley DB specific options as parameters. For other customizations, check DB's documentation. Drum's public interface is minimal. Extend it, if you desire.- Make sure you have
<boost/array.hpp>, <boost/tuple/tuple.hpp>, <boost/cstdint.hpp>, and <db_cxx.h> on your compiler's path. These Boost libraries are header only, but Berkeley DB requires linking.
Hands-On Coding
This section illustrates how to use the code. First, the concrete type of the Drum is defined. The key is a boost::uint64_t and both the value and aux types are std::string. It has 2 key/value buckets (with 2 associated auxiliary buckets), 4 elements per array, and a bucket threshold size of 64 bytes. The URLSeenDispatcher simply prints the output on the screen. (Notice that URLSeenDispatcher inherits from NullDispatcher, which does not provide any virtuals. Therefore, you should not rely on a base pointer or reference to refer to it.) A real scenario would naturally require a different setup.
It is worth remembering that once you are done with
Drum, there might be pending elements that did not go through disk merge yet. To make sure everything is processed, you should force synchronization. Then, I recommend calling
Dispose. If you forget to do that,
Drum's destructor will do it for you. However, if an exception is thrown, it will not propagate it.
For the URL-seen test, keys are URL fingerprints calculated using Rabin's method as described by Broder. The URLs are supplied in the form of auxiliaries and no values associated to the keys are actually stored. Only the check + update operation is used.
#include "drum.hpp"
#include "bucket_identifier.hpp"
#include "db_compare.hpp"
#include "rabin_fingerprint.hpp"
#include <iostream>
using namespace drum;
template <class key_t, class value_t, class aux_t>
struct URLSeenDispatcher : NullDispatcher<key_t, value_t, aux_t>
{
void UniqueKeyUpdate(key_t const& k, value_t const& v, aux_t const& a) const
{std::cout << "UniqueKeyUpdate: " << k << " Data: " << v << " Aux: " << a << "\n";}
void DuplicateKeyUpdate(key_t const& k, value_t const& v, aux_t const& a) const
{std::cout << "DuplicateKeyUpdate: " << k << " Data: " << v << " Aux: " << a << "\n";}
};
int main()
{
try
{
std::cout << "Example of Drum usage." << std::endl;
typedef Drum<boost::uint64_t, std::string, std::string,
2, 4, 64, URLSeenDispatcher> DRUM;
DRUM drum("url-seen.db");
RabinFingerprint fp;
std::string url0 = "http://www.codeproject.com";
boost::uint64_t key0 = fp.Compute(url0.c_str(), url0.size());
drum.CheckUpdate(key0, "", url0);
std::string url1 =
"http://www.oracle.com/technology/products/berkeley-db/index.html";
boost::uint64_t key1 = fp.Compute(url1.c_str(), url1.size());
drum.CheckUpdate(key1, "", url1);
std::string url2 = "http://www.boost.org";
boost::uint64_t key2 = fp.Compute(url2.c_str(), url2.size());
drum.CheckUpdate(key2, "", url2);
std::string url3 = "http://www.codeproject.com";
boost::uint64_t key3 = fp.Compute(url3.c_str(), url3.size());
drum.CheckUpdate(key3, "", url3);
drum.Synchronize();
drum.Dispose();
std::cout << "Done!" << std::endl;
}
catch (DrumException & e)
{
std::cout << "Drum error: " << e.what() <<
" Number: " << e.get_error_code() << std::endl;
}
catch (std::exception & e)
{
std::cout << "Drum error: " << e.what() << std::endl;
}
catch (...)
{
std::cout << "Something wrong..." << std::endl;
}
return 0;
}
Final Notes
If you are still reading, thank you very much. I am pretty sure that there are many possible improvements in the implementation and it is definitely not a final solution. There are things that could have been done differently, but the implementation represents a balance between my available time to build it and what I considered to be a good starting point. If you have questions, suggestions, or corrections to make, feel free to contact me. I really would like to hear opinions.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







