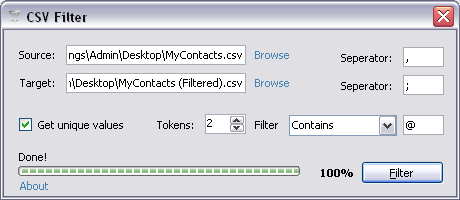
Introduction
In this article, you will learn how to read a CSV (Comma Separated Values) file and re-write it to another file applying some basic filter of your choice.
The reason why I wrote this article is that I had some old lengthy contact list on my desktop and I wanted to organize it, remove duplicates and convert it into a CSV file. Of course, I had to first use Microsoft Word for replacing semicolons with commas and then insert the special character ^p at the end of each line making sure I have a CSV file format of two columns.
Background
To understand this article, you need to be familiar with the basics of IO streams and ADO.
Using the Code
First, we start by reading the source CSV file using a BackgroundWorker component and we make sure we don't do anything stupid that may result in a cross-thread crash.
We create a StreamReader and read the source file line by line and split it according to the specified separator character and see if the resulting tokens match the ones expected, if so, then a row is created in a DataTable object:
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
DataTable dt;
StreamReader sr;
StreamWriter sw;
string[] tokens={String.Empty};
OpenFile:
try
{
sr = new StreamReader(strSource);
}
catch (IOException)
{
DialogResult dr = MessageBox.Show("Source file in use!",
"Error", MessageBoxButtons.AbortRetryIgnore, MessageBoxIcon.Error);
if (dr == DialogResult.Retry)
goto OpenFile;
else
return;
}
dt = new DataTable("CSV_SOURCE");
for (int x = 1; x <= (int)numTokens.Value; x++)
dt.Columns.Add("COL_"+x.ToString(), typeof(string));
backgroundWorker1.ReportProgress(0, "Reading source file...");
while (!sr.EndOfStream)
{
try
{
tokens = sr.ReadLine().Split(strSourceSeperator.ToCharArray()[0]);
if (tokens.Length == (int)numTokens.Value)
dt.Rows.Add(tokens);
}
catch (Exception ex) { MessageBox.Show(ex.Message); }
}
sr.Close();
}
Our DataTable object columns were created in a simple loop and named COL_1, COL_2, COL_3..., etc. according the number of tokens specified by the user and found in the source file:
dt = new DataTable("CSV_SOURCE");
for (int x = 1; x <= (int)numTokens.Value; x++)
dt.Columns.Add("COL_"+x.ToString(), typeof(string));
Notice that when starting the thread, we had to create a set of class global variables that stores the input from the interface controls in order to ensure thread safety:
string strFilter, strSourceSeperator, strTargetSeperator;
private void btnFilter_Click(object sender, EventArgs e)
{
strFilter = txtFilter.Text;
strSourceSeperator = txtSourceSeperator.Text;
strTargetSeperator = txtTargetSeperator.Text;
backgroundWorker1.RunWorkerAsync();
}
Now we remove the duplicates:
if (chUnique.Checked)
dt = dsHelper.SelectDistinct("DISTINCT_CSV_SOURCE", dt, "COL_1");
Actually, I did something stupid in the code segment above and you'd better fix it by creating one more class global bool variable and assign the checkbox control state to it.
For the SelectDistinct method, you need to include this helper class in your solution:
public class DataSetHelper
{
public DataSet ds;
public DataSetHelper(ref DataSet DataSet)
{
ds = DataSet;
}
public DataSetHelper()
{
ds = null;
}
private bool ColumnEqual(object A, object B)
{
if (A == DBNull.Value && B == DBNull.Value)
return true;
if (A == DBNull.Value || B == DBNull.Value)
return false;
return (A.Equals(B));
}
public DataTable SelectDistinct
(string TableName, DataTable SourceTable, string FieldName)
{
DataTable dt = new DataTable(TableName);
dt.Columns.Add(FieldName, SourceTable.Columns[FieldName].DataType);
object LastValue = null;
foreach (DataRow dr in SourceTable.Select("", FieldName))
{
if (LastValue == null || !(ColumnEqual(LastValue, dr[FieldName])))
{
LastValue = dr[FieldName];
dt.Rows.Add(new object[] { LastValue });
}
}
if (ds != null)
ds.Tables.Add(dt);
return dt;
}
}
Finally we create a StreamWriter object, iterate through our previously created DataTable object, fetch its data row by row and column by column, include the new separator character (or keep the original) and close the stream.
SaveFile:
try
{
sw = new StreamWriter(strTarget);
}
catch (IOException)
{
DialogResult dr = MessageBox.Show("Target file in use!",
"Error", MessageBoxButtons.AbortRetryIgnore, MessageBoxIcon.Error);
if (dr == DialogResult.Retry)
goto SaveFile;
else
return;
}
backgroundWorker1.ReportProgress(50, "Writing to target file...");
string tmpLine;
foreach(DataRow dr in dt.Rows)
{
try
{
foreach (DataColumn dc in dt.Columns)
{
tmpLine = dr[dc].ToString();
switch(iFilter)
{
case 0:
if (tmpLine.Contains(strFilter))
sw.Write(tmpLine);
break;
case 1:
if (!tmpLine.Contains(strFilter))
sw.Write(tmpLine);
break;
}
if (!dc.ColumnName.EndsWith("_"+ dt.Columns.Count.ToString()))
sw.Write(strTargetSeperator);
}
sw.Write("\r\n");
}
catch (Exception ex) { MessageBox.Show(ex.Message); }
}
sw.Close();
For filtering the results, we used the following basic verification steps:
tmpLine = dr[dc].ToString();
switch(iFilter)
{
case 0:
if (tmpLine.Contains(strFilter))
sw.Write(tmpLine);
break;
case 1:
if (!tmpLine.Contains(strFilter))
sw.Write(tmpLine);
break;
}
History
- 27th September, 2009: Initial post


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




