Introduction
A programmer usually wants to write easily readable, maintainable, and extensible code. However, in some cases, performance becomes the most important thing. This article provides several useful tips on boosting the performance of common string operations without using unsafe code.
Background
I recently spent some time working on a simple code editor, and one of the key features of the app is syntax highlighting. When implementing a function like this, performance is crucial, and it took a while for me to optimize my code. I learned a lot when working on that project, and I would like to share my experience with all of you.
The project attached to this article contains a simple benchmark application to compare all the methods described below.
Searching for a word in a string
Searching for something inside a string is a very common task. There are several ways to do this, and the following section discusses each option:
Using Regular Expressions
Regular Expressions are a very powerful, useful, and often, very fast tool for data validation and string searching. However, when performance is important, Regular Expressions might become a nightmare, and there are several things you can do to make your code run faster.
Rule #1: Write a good expression
It's easy to write a Regular Expression, but sometimes, it's a challenge to write an efficient Regular Expression. Optimizing Regular Expressions is beyond the scope of this article, and there are many articles on the web and books that cover this topic. The most important rule is: keep it simple. Complex Regular Expressions that include a lot of alternations usually take too long to execute.
Rule #2: Do not use static methods of the Regex class
The Regex class provides several static methods that enable basic operations. The following code finds out whether the string variable input contains a substring given by the variable pattern.
string input = "The quick brown fox jumps over the lazy dog";
string pattern = "fox";
if (Regex.IsMatch(input, pattern)) {
}
The IsMatch method creates a Regex object from the pattern variable, and then tries to match the input string. Performance-wise, this process is slow, and it is only useful if the Regular Expression is not used repeatedly.
Rule #3: Re-use Regex objects if you can
As stated above, the creation of a Regex object takes a while, and you should avoid doing it too often. In some scenarios, you can initialize all necessary Regular Expressions during the startup of your application and then use them multiple times when processing a long text. This will increase the performance significantly.
Rule # 4: Consider using compiled Regular Expressions
The performance may be even better if you use the Compiled option when creating a Regex object.
Regex pattern = new Regex("SomePattern", RegexOptions.Compiled);
There are several disadvantages though - compiled Regular Expressions increase the startup time of your application and cause more memory use. Jeff Atwood wrote a brilliant article that discusses the advantages and the disadvantages of compiled Regular Expressions: http://www.codinghorror.com/blog/archives/000228.html.
Using the IndexOf() method
The IndexOf method of the String type is very useful when searching for a sub-string inside a string. There are a few things you might want to know to use this method efficiently.
Use the char type if you can
There are two basic overloads of the IndexOf method - the first parameter can be a character or a string. The char version is much faster though. If you know the string you are searching for is only one character long, use the char type instead.
An unsuccessful search takes longer than a successful search
This fact is not very surprising - if the IndexOf method succeeds, it returns the position of the first occurrence of the given string or character, and it ignores the rest of the input string. Nonetheless, if the input string does not contain the specified character or string, the IndexOf function has to search the whole input. What's the conclusion?
There is often a way to eliminate unsuccessful searches. For example, if you want to know whether an input string contains any of a set of words, you can first search for the words that are more likely to appear in the input string.
What about writing a text-search method from scratch?
Now, I'm getting to the most interesting part. The IndexOf method is quite fast when searching for a character, but it's slow when searching for a word. What if there is a faster way to search for a word inside a string?
I spent some time looking for the fastest possible solution, and the following method is what I came up with:
static int FastIndexOf(string source, string pattern) {
if (pattern == null) throw new ArgumentNullException();
if (pattern.Length == 0) return 0;
if (pattern.Length == 1) return source.IndexOf(pattern[0]);
bool found;
int limit = source.Length - pattern.Length + 1;
if (limit < 1) return -1;
char c0 = pattern[0];
char c1 = pattern[1];
int first = source.IndexOf(c0, 0, limit);
while (first != -1) {
if (source[first + 1] != c1) {
first = source.IndexOf(c0, ++first, limit - first);
continue;
}
found = true;
for (int j = 2; j < pattern.Length; j++)
if (source[first + j] != pattern[j]) {
found = false;
break;
}
if (found) return first;
first = source.IndexOf(c0, ++first, limit - first);
}
return -1;
}
This function is based on the fact that the IndexOf method is very fast when searching for a character.
The basic idea is simple - the method searches for the first character of the word, and once it is found, it checks for the following characters form the rest of the word. The code is a little messy since it includes a bunch of small optimizations. For example, I found out that the average performance is even better if the method checks the second character (after the first one has been found) before starting the "for" loop that goes through the rest of the word.
Note:
The behavior of this function is very similar to the String.IndexOf() function, but in some exceptional cases, the results may vary. If you need to perform culture-sensitive string searches, or you need to work with characters that are not in the Basic Multilingual Plane of the Unicode standard, the method provided above might not return accurate results.
Comparison
I've done a lot of testing on randomly generated strings to compare the three options listed above, and here are the results:
- The
IndexOf function was always approximately 20% slower than my custom FastIndexOf method when searching for a word. - Regular Expressions are the fastest way to find a word inside a string if both the word and the input string are long enough.
The graph below is based on the values I measured, and it shows which of the two fastest options is better depending on the length of the input strings:
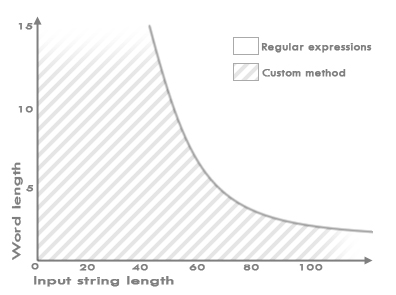
The vertical axis indicates the length of the word being searched for (in characters), and the horizontal axis shows the length of the input string (in characters). The striped area is where a custom search method outperforms Regular Expressions.
Please note that all measured values are approximate.
Replacing characters with escape sequences
Another common task when working with strings is to replace a set of characters with a set of escape sequences. Sometimes the replacement is very easy - you only have to place a backslash (or another character) before every occurrence of an escaped character.
Imagine the following scenario: you are building an RTF file and you want to insert a string into the file. The "{", "}", and "\" characters have a special meaning in RTF and, therefore, must be preceded with a backslash. The question is: what is the fastest way to replace each of the characters with a corresponding escape sequence?
Regular Expressions
Using the Replace method of the Regex class is one of the possible solutions. However, Regular Expressions are by far the slowest option in this case.
The Replace() method of String
Another simple option is to use the Replace method of the string type. When building an RTF file, the replace procedure would be the following:
string input;
input.Replace("\\", "\\\\").Replace("{", "\\{").Replace("}", "\\}");
It's easily readable, short, and clean, but it's not always the fastest option.
Writing a custom method from scratch
Just like in the previous case, I tried to write a custom method that does the same task. Here is the code:
static string Escape1(string source, char[] escapeChars, char escape) {
int i = source.IndexOfAny(escapeChars);
while (i != -1) {
source = source.Insert(i, escape.ToString());
i = source.IndexOfAny(escapeChars, i + 2);
}
return source.ToString();
}
The first parameter is the input string, the second one is an array of characters that should be escaped, and the last parameter is the escape character. As you probably know, editing a string directly is not very efficient if you need to do many operations in a row. The StringBuilder class provides an efficient way to edit strings although it takes a bit of time to initialize a StringBuilder object, and it's only reasonable to use a StringBuilder if you know that you will need to edit the string repeatedly.
I created another version of the method above using StringBuilder:
static string Escape2(string source, char[] escapeChars, char escape) {
StringBuilder s = new StringBuilder();
int j = 0;
int i = source.IndexOfAny(escapeChars);
while (i != -1) {
s.Append(source.Substring(j, i - j));
s.Append(escape);
j = i;
i = source.IndexOfAny(escapeChars, j + 1);
}
s.Append(source.Substring(j));
return s.ToString();
}
Comparison
I used the three methods described above to replace a set of three characters with an escape sequence. The graph below shows which method is the fastest, depending on the input string:
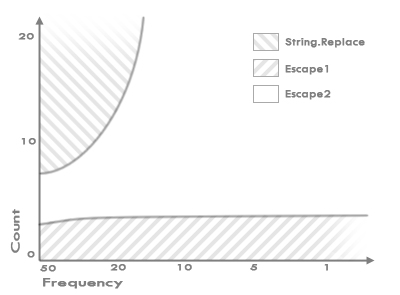
The vertical axis shows the number of escaped characters in a string, while the horizontal axis shows the frequency of escape characters in %. A frequency of 50 means that every other character in the input string needs to be escaped, and a frequency of 1 means that only 1% of the characters in the input string (every 100th character) is escaped.
The String.Replace method shows to be the fastest one if there are enough characters to be escaped and if the frequency of escaped characters is high enough (the striped area in the top-left corner of the graph).
As the rest of the graph shows, a custom character-escaping method is the fastest option in most cases. As expected, the StringBuilder version of the method is faster if the number of replaced characters is high enough, in this case, approximately 5 characters.
If you want to know a little bit more about String/StringBuilder performance comparison, I recommend the following two resources:
Conclusion
If you want an excellent performance, you have to know what kind of data you are going to work with, and you will have to spend some time comparing all available options, just like I did.
I hope this article pushed you in the right direction and helped you to increase the performance of your code. Any feedback is greatly appreciated!
Sample benchmark application
Here is the source code of the project I used to compare the performance of all the methods listed above. Feel free to download it and use it any way you like:
History
- Edited: 2010-01-10: Added a note about the differences between the
FastIndexOf and IndexOf functions. - Edited: 2010-01-07: The
FastIndexOf function has been improved a little bit. Thanks to James Curran for his suggestion. - Posted: 2010-01-06.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 , but I have to point out that this optimization is not necessary
, but I have to point out that this optimization is not necessary  in case anyone who reads this article take it as the solution.
in case anyone who reads this article take it as the solution.
