Contents
1. Introduction
In this article, we will first discuss the efficiency of the most popular implementations of the search_n STL algorithm. Afterwards, I will demonstrate a new search_n
specialization for random access iterators, which outruns by far the
most commonly used implementations. This is, in fact, a substantially
improved search_n algorithm, which has significantly lower time complexity.
My intention is to move straight to the point, without lengthy
introductions about the C++ templates or the STL itself. In order to
understand this article, you need to have a good understanding of the
C++ templates, the standard template library (STL) and, of course, the
C++ language. Finally, I have to admit that search_n is
not the most notable algorithm in STL, and improving it is not going to
make a big difference to the majority of the C++ developers. On the
other hand, speeding-up an algorithm 2 - 8 times can be sometimes
useful...
2. The algorithm usage and behavior
The search_n algorithm is already sufficiently documented. [2,4,6]
Hence, in order to describe the usage and behavior of the algorithm, I
have borrowed the following three paragraphs (2.1, 2.2 & 2.3) from
the excellent SGI STL documentation. [1,2].
2.1 Prototype
Search_n is an overloaded name; there are actually two search_n functions.
template <class ForwardIterator, class Integer, class T>
ForwardIterator search_n(ForwardIterator first, ForwardIterator last,
Integer count, const T& value);
template <class ForwardIterator, class Integer,
class T, class BinaryPredicate>
ForwardIterator search_n(ForwardIterator first, ForwardIterator last,
Integer count, const T& value,
BinaryPredicate binary_pred);
2.2 Description
search_n searches for a subsequence of count consecutive elements in the range [first, last), all of which are equal to value. It returns an iterator pointing to the beginning of that subsequence, or else last if no such subsequence exists. The two versions of search_n differ in how they determine whether two elements are the same: the first uses operator==, and the second uses the user-supplied function object binary_pred.
The first version of search_n returns the first iterator i in the range [first, last-count) such that, for every iterator j in the range [i, i+count), *j == value. The second version returns the first iterator i in the range [first, last-count) such that, for every iterator j in the range [i, i+count), binary_pred(*j, value) is true.
2.3 Complexity
Linear. search_n performs at most last-first comparisons. (The C++ standard permits the complexity to be O(n(last-first)), but this is unnecessarily lax. There is no reason for search_n to examine any element more than once.)
3. The usual implementations
All the search_n implementations that I know are quite
similar to each other and, in all known cases, the same algorithm is
being used for both forward and random access iterators. The following flow chart 1 illustrates in some detail such a typical search_n implementation. Among all these search_n versions, we can easily distinguish the VC++ and SGI implementations as the dominant ones. We are going to discuss both these versions in the following subsections [s3.1.] and [s3.2.] respectively. For simplicity, we are discussing only the first variant of search_n, which is testing equality by using the operator==, instead of the user-supplied function object binary_pred. [s2] Apart from the use of the binary_pred,
both the design and behavior of the second variant are identical to the
design and behavior of its counterpart. Hence, everything that we
discuss about the first variant applies to the second as well.
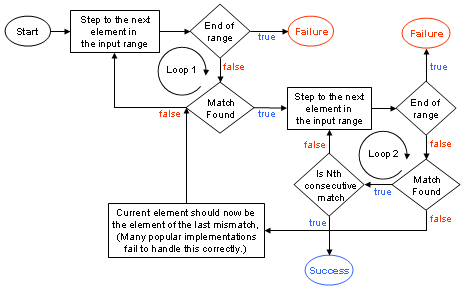
3.1. The VC++ implementation
This search_n implementation is part of the STL that is
accompanying the popular Microsoft Visual C++ 6.x-7.0 compilers.
Moreover, it is also very similar to the implementation that the STL of
Metrowerks CodeWarrior 8.x-9.x provides (although, Metrowerks version
has some advantages discussed in the point of interest 4 below). In
other words, this is one of the most frequently used search_n implementations.
The source code
The source code of the VC++ search_n
implementation is not presented here, in order to avoid a potential
copyright violation. Nevertheless, anyone who owns a Visual C++ 6.x-7.0
compiler can very easily find this piece of code inside the algorithm header file.
Points of interest
- According to the VC++
search_n documentation in the MSDN site, [4] its time complexity is: linear with respect to the size of the searched (see also performance tests B1, B2 & C in section 5 [s5]).
- The VC++
search_n first calculates the breadth of the search range [_First1, _Last1)
and it is henceforth using this breadth value, in order to form the
logical expressions that control the loops. The breadth calculation has
obviously constant time complexity when _FwdIt1 is a
random access iterator but linear time complexity otherwise. In other
words, we will experience significant overhead when using this search_n implementation with lists and other sequences that don't provide random access iterators (see also performance test E in section 5 [s5]).
- The VC++
search_n frequently examines many of the search range elements more than once. Like mentioned above, search_n is searching for a subsequence of _Count consecutive elements in the range [_First1, _Last1), all of which are equal to _Val. In case that the VC++ version meets a subsequence of only M (M < _Count) consecutive elements equal to _Val,
it will decide that this particular subsequence is not long enough and
it will continue its search, starting from the second element of the
current subsequence (instead of the element that is next to the last
mismatch). Then it will immediately meet M-1 consecutive elements equal to _Val, which are in fact the M-1 last elements of the initial subsequence of M elements. Afterwards, it will also revisit the last M-2 elements of the initial subsequence and then again the last M-3 elements, and so on.
Namely, when meeting M (M<_Count) consecutive elements equal to _Val , VC++ search_n will eventually make M(M+1)/2 redundant comparisons! Hence, the VC++ search_n implementation is rather inefficient in cases when it's probable that many elements in the search range [_First1, _Last1) are equal to _Val (see also performance test D in section 5 [s5]).
- The Metrowerks version of
search_n is very similar to its VC++
counterpart, but it has the significant advantage to never examine any
element of its search range more than once. Hence the above point of
interest 2 does apply to the Metrowerks implementation as well, whereas
the point of interest 3 doesn't.
3.2. The SGI implementation
The following search_n implementation is part of the excellent SGI STL (version 3.3). [1,2]
This implementation is mainly used in all the modern versions of the
GCC compiler (including GCC for Darwin and MinGW). Thus, this is also
one of the most popular search_n implementations.
The source code
template <class _ForwardIter, class _Integer, class _Tp>
_ForwardIter search_n(_ForwardIter __first, _ForwardIter __last,
_Integer __count, const _Tp& __val) {
__STL_REQUIRES(_ForwardIter, _ForwardIterator);
__STL_REQUIRES(typename iterator_traits<_ForwardIter>::value_type,
_EqualityComparable);
__STL_REQUIRES(_Tp, _EqualityComparable);
if (__count <= 0)
return __first;
else {
__first = find(__first, __last, __val);
while (__first != __last) {
_Integer __n = __count - 1;
_ForwardIter __i = __first;
++__i;
while (__i != __last && __n != 0 && *__i == __val) {
++__i;
--__n;
}
if (__n == 0)
return __first;
else
__first = find(__i, __last, __val);
}
return __last;
}
}
Points of interest
- According to the SGI
search_n documentation [2], its time complexity is: Linear. search_n performs at most last-first comparisons (see also performance tests B1, B2 & C in section 5 [s5]).
- The SGI
search_n is using the find algorithm internally, whenever appropriate. Hence, it can utilize potential specializations of the find algorithm and, therefore, increase its performance significantly. (For instance, if _ForwardIter is of type (char *), then find is probably using the memchr function internally.) A very good design choice indeed!
- The iterator advancements inside the SGI
search_n are significantly restrained, compared to the VC++ implementation. This implementation does not need to calculate the breadth of the search range [__first, __last)
and is much more suitable for use with lists and other sequences that
don't provide random access iterators (see also performance test E in section 5 [s5]).
- The SGI documentation correctly states that there is no reason for
search_n to examine any element more than once, [2] but unfortunately the SGI implementation of search_n does not fully comply with this notion. Again, search_n is searching for a subsequence of __count consecutive elements in the range [__first, __last), all of which are equal to __val. In case that the SGI version meets a subsequence of only M (M < __count) consecutive elements equal to __val,
it will decide that the particular subsequence is not long enough and
it will continue its search, starting from the element of last mismatch
(instead of the element that is next to the last mismatch). Namely, the
__first = find(__i, __last, __val) expression in the above code always examines the *__i element, while *__i could be the element that caused the mismatch (and therefore has been already examined) in the *__i == __val logical expression of the previous while loop.
In other words, the SGI search_n is making one redundant comparison every time it meets a subsequence of elements equal to __val. Practically, this shouldn't be a big problem in most of the real world situations, but it's for sure a flaw in the SGI implementation of search_n (see also performance test D in section 5 [s5]).
4. An enhanced implementation for random access iterators
In this section, I am introducing an enhanced search_n
implementation, which can only be used with random access iterators.
The strength of this implementation lies in the way that its main loop
works [flow chart 2: loop 1]. When searching for N consecutive elements that meet the search_n criteria, this main loop examines only one of every N elements of the search range, whereas the VC++ and SGI versions [s3] examine the search range elements one by one [flow chart 1: loop 1]. Of course, when the main loop finds a match, this search_n version has to backtrack, because the matched element could be in the middle of a subsequence that meets the search_n criteria. Therefore, it will first move backward [flow chart 2: loop 3] and then again forward [flow chart 2: loop 2]
in order to accurately estimate the start and length of the particular
subsequence. Nevertheless, the backtracking happens rather infrequently
and then again no element is ever examined more than once.
Consequently, it is expected that this search_n implementation will be always faster than the VC++ and SGI versions. For convenience (and for brevity's sake), I will henceforth use the name "DPX search_n" when I refer to this particular algorithm.
Below follows a demonstration of the DPX search_n
implementation in both the forms of the flow chart and the source code.
Afterwards, we will also discuss some points of interest regarding this
implementation.

The source code
template <class _RandomAccessIter, class _Integer, class _Tp> inline
_RandomAccessIter search_n(_RandomAccessIter __first,
_RandomAccessIter __last, _Integer __count, const _Tp& __val)
{
if (__count <= 0)
return __first;
if (__count == 1)
return std::find(__first, __last, __val);
typedef std::iterator_traits<_RandomAccessIter>::difference_type iter_diff;
iter_diff __tailSize = __last - __first;
const iter_diff __pattSize = __count;
if (__tailSize >= __pattSize)
{
_RandomAccessIter __backTrack;
iter_diff __remainder, __prevRemainder;
const iter_diff __skipOffset = __pattSize - 1;
_RandomAccessIter __lookAhead = __first + __skipOffset;
for ( ; ; __lookAhead += __pattSize ) {
assert( __tailSize >= __pattSize );
__tailSize -= __pattSize;
for ( ; ; ) {
if (*__lookAhead == __val)
break;
if (__tailSize < __pattSize)
return __last;
__lookAhead += __pattSize;
__tailSize -= __pattSize;
}
assert( __tailSize == (__last - __lookAhead) - 1 );
__remainder = __skipOffset;
for ( __backTrack = __lookAhead - 1; *__backTrack ==
__val; --__backTrack )
{
if (--__remainder == 0)
return (__lookAhead - __skipOffset); }
for ( ; ; )
{
if (__remainder > __tailSize)
return __last;
__lookAhead += __remainder;
__tailSize -= __remainder;
if (*__lookAhead == __val)
{
__prevRemainder = __remainder;
__backTrack = __lookAhead;
do
{
if (--__remainder == 0)
return (__lookAhead - __skipOffset);
} while ( *--__backTrack == __val);
__remainder += __pattSize - __prevRemainder;
}
else
break;
}
if (__tailSize < __pattSize)
return __last;
}
}
return __last; }
Points of interest
- DPX
search_n performs at most last-first comparisons, hence its worst case complexity is linear, similar to the average complexity of the VC++ and the SGI
implementations. But this worst-case is actually extremely rare to
happen with this algorithm. On the other hand, its average time
complexity will be O((last-first)/count) (see also performance tests A, B1, B2 & C in section 5 [s5]).
- Apart from the fact that the DPX
search_n
actually examines only few of the elements that meets, I have also done
my best to ensure that no element of the search range is ever examined
more than once (see also performance test D in section 5 [s5]). Consequently, this search_n version is ideal for use in cases where the comparison of the elements is a rather slow procedure.
- For the above reasons, I believe that this
search_n implementation outperforms both the VC++ and the SGI
implementations in every possible case. Its only disadvantage is the
fact that it requires random access iterators, thus it cannot be used
with lists and other sequences which only provide forward iterators
(see also performance tests in section 5 [s5] and conclusions in section 6 [s6]).
5. Performance tests
So far we have met three different implementations of the search_n
algorithm, and we have also discussed in theory their expected runtime
performance. In this section, we are going to observe what really
happens when we run these algorithms on a computer. In particular, I
have carried out a series of performance tests, using the code that is
included at the top of this article. In the next subsections, follow a
description of each test and a brief discussion about its results. All
the results of the performance tests have been visualized as graphs at
the end of the section.
Some new symbols, which I am going to use frequently in the next paragraphs, are:
- The symbol
N, which denotes the number of the consecutive elements that search_n is searching for.
- The symbol
M, which denotes the number of the sequence elements that search_n overtakes during the search.
The objective of this test is to observe the behavior of the DPX search_n algorithm [s4], when the number of the overtaken elements M is growing. The test has been repeated three times, for three different values of N. The searched elements in this test are stored in a vector, and the probability of meeting a matching element is 1%.
The results of the test A have been visualized in the corresponding graph A. The vertical axis of the graph represents the elapsed time and the horizontal axis represents the overtaken elements M. This graph shows clearly that the elapsed times grow linearly with respect to M , but it is also clear that DPX search_n performs much better as N is being increased. This is a strong indication that the particular search_n implementation has time complexity O(M/N), whereas the most popular implementations usually have time complexity O(M).
The objective of these tests is to observe and compare the behavior of all three search_n implementations discussed so far, when the number of the overtaken elements M is growing. The only difference between test B1 and test B2 is the value of N, which is equal to 4 and 32 respectively. The searched elements in both tests are stored in a vector and the probability of meeting a matching element is 1%.
The results of the tests B1 and B2 have been visualized in the corresponding graphs B1 and B2. The vertical axes of both these graphs represent the elapsed time and the horizontal axes represent the overtaken elements M. Both graphs show that, in all three search_n implementations, the elapsed times grow linearly with respect to M. The SGI version seems to always perform better than its VC++ counterpart and the DPX version outperforms all its competitors. In the test B2, in which N value is 32 instead of 4, the performance of the SGI and VC++ versions is identical to their corresponding performance in test B1, whereas the performance of the DPX
version is significantly improved. This is exactly what we would
expect, knowing the time complexities of the three algorithms. (DPX search_n has time complexity O(M/N), whereas the other two versions have time complexity O(M)).
The objective of this test is to observe and compare the behavior of all three search_n implementations discussed so far, when the number of the overtaken elements M is kept constant (one million elements), whereas the value of N is growing. The searched elements are stored in a vector and the probability of meeting a matching element is 1%.
The results of the test C have been visualized in the corresponding graph C. The vertical axis of the graph represents the elapsed time and the horizontal axis represents N. The graph shows that the SGI and VC++ versions of search_n are not affected when N is changing, whereas the DPX version performs much better when N is increased. This is another proof that DPX search_n has time complexity O(M/N).
The objective of this test is to observe and compare the behavior of all three search_n implementations discussed so far, when M and N
are kept constant (one million elements and 32 respectively), but the
density of the matching elements is growing. Namely, in this test, we
increase the probability of meeting a matching element. The searched
elements are stored in a vector.
The results of the test D have been visualized in the corresponding graph D.
The vertical axis of the graph represents the elapsed time and the
horizontal axis represents the density of the matching elements. The
graph shows that the performance of the SGI and VC++ search_n versions becomes significantly lower when the density of the matching elements becomes higher, whereas the DPX version remains almost unaffected. That is because the SGI and VC++ versions are making many redundant comparisons (worst case in test D: +100%) when the density of the matching elements is high. In the same circumstances, the DPX version examines only few (worst case in test D: 9%) of the elements that meets.
The objective of this test is to observe and compare the behavior of the SGI and VC++ search_n implementations, when the number of the overtaken elements M is growing and the searched elements are stored in a list. Note that DPX search_n cannot be used in this test, because it requires random access iterators, whereas list only provides forward iterators. N is constantly equal to 16 and the probability of meeting a matching element is 1%.
The results of the test E have been visualized in the corresponding graph E. The vertical axis of the graph represents the elapsed time and the horizontal axis represents the overtaken elements M. When compared to the previous graphs B1 and B2, this graph shows that the performance advantage, which SGI search_n has over the VC++ version when using random access iterators, gets even bigger in case that forward iterators are being used.
More details
The vertical axes of all graphs represent the elapsed time and you
may notice that these axes does not provide any information regarding
the exact values of the elapsed time. That is intentional, because we
are not interested in the individual elapsed times, but instead we need
to pay attention to the growth of the times when a problem factor is
being changed. Moreover, the actual elapsed times are only meaningful
on the computer where I have run these tests, with the particular
hardware and software configuration that this computer had at that time.
The code used to carry out these tests is included at the top of
this article. It is a small and simple piece of code, fairly documented
with comments inside the source files, which I believe can be easily
used both for verification of my test results, and also for further
experimentation regarding the runtime behavior of the search_n algorithms.
6. Conclusions
In this article, we have discussed the efficiency of the search_n STL algorithm. In particular, we have discussed the very popular VC++ and SGI versions [s3] and I have also introduced the new DPX search_n [s4], which is an efficient specialization of the search_n algorithm for random access iterators. Furthermore, I have carried out a series of performance tests [s5]
in order to demonstrate what really happens when we run these
algorithms on a computer. The conclusions of all these discussions and
tests can be summarized as follows:
- When it comes to random access iterators, DPX
search_n is by far the best choice. Its average time complexity is much better (see the point of interest 1 in section 4 [s4]) and the performance tests have verified this fact (see tests A, B1, B2, C in section 5 [s5]).
- DPX
search_n performs even better when the
number of the consecutive elements that is searching for gets bigger
(see tests A & C in section 5 [s5]) or the probability of meeting a matching element is increased (see test D in section 5 [s5]).
- For forward access iterators, SGI
search_n performs much better than the VC++ version (see test E in section 5 [s5]).
7. More about this article
7.1. Acknowledgments
Portions of the article's text and code are derived from the SGI/HP implementation and documentation of STL.
Copyright © 1996-1999
Silicon Graphics Computer Systems, Inc.
Permission to use, copy, modify, distribute and sell this
software and its documentation for any purpose is hereby granted
without fee, provided that the above copyright notice appears in all
copies and that both that copyright notice and this permission notice
appear in supporting documentation. Silicon Graphics makes no
representations about the suitability of this software for any purpose.
It is provided "as is" without express or implied warranty.
Copyright © 1994
Hewlett-Packard Company
Permission to use, copy, modify, distribute and sell this
software and its documentation for any purpose is hereby granted
without fee, provided that the above copyright notice appears in all
copies and that both that copyright notice and this permission notice
appear in supporting documentation. Hewlett-Packard Company makes no
representations about the suitability of this software for any purpose.
It is provided "as is" without express or implied warranty.
7.2. Related news
- 2005-09-12
- A
search_n specialization for random access iterators has been incorporated in the libstdc++ library of the GCC package.
(Changelog,
Release-changes)
- 2005-02-27
- A
search_n specialization for random access iterators has been incorporated in the STLPort library.
(Changelog,
Release-changes)
7.3. Revision History
- 2007-03-23
- A bug-fix and performance improvements in the
search_n specialization for random access iterators.
- 2004-04-19
- Potential construction and destruction of objects moved outside the loops (proposed by Simon Hughes).
- 2004-04-12
8. References
- The SGI Standard Template Library.
- The search_n algorithm of the SGI STL.
- The VC++ Standard Template Library.
- The search_n algorithm of the VC++ STL.
- The Rogue Wave Standard Template Library.
- The search and search_n algorithms of the Rogue Wave STL.
- The STLport Standard Template Library.
I live in Greece with my wife and our two daughters. I am a professional software developer since 1999, using mostly C/C++ in my work.
My main expertise are: C/C++, STL, software optimization, generic programming and debugging. I am also very experienced in client–server programming, communications, concurrent programming, software security and cryptography. Finally, in my early professional years, I have worked a lot on cross-platform programming (Mac+Win).
I am familiar with the MFC, wxWidgets and Cplat GUI frameworks and the Python, Java, Pascal, Fortran, Prolog and Rexx programming languages.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







