The problem
Many modern applications are very complex and consist from various components frequently built by different teams and even companies. Components are exploiting data models of the application on multiple threads, may perform long running operations, and expect high level of data integrity. When user is modifying data she usually expecting to have Undo/Redo available. For performance and usability reasons application wants to update UI only incrementally changing only areas affected by recent changes in the model. The good example of such applications can be any IDE you are familiar with, or some sort of CAD editors, or anything else - you name it.
When some component is performing long running processing of data while user continue editing it bringing a great deal of problems. The easiest set of problems is just a data access synchronization. Usually this level of problems resolve by various lock, semaphores, and reference counters. But essentially all of them is a simple freeze everything around to perform its own action. There are many disadvantages of using such mechanisms. You can refer to this Wikipedia article: http://en.wikipedia.org/wiki/Lock_(computer_science)#Disadvantages to get more details. But building lock based multicomponent application so hard that it is next to impossible.
Another set synchronization problems comes from higher level of data semantic. Which boils down to the fact that a component want to see all parts of data in the same version. For example if the data consists of two fields X and Y you’d expect these two values are representing the same point, not when another component already changed one field and is about to change another.
The Idea
There are many ways to do lock free programming. But the one that is nicely blends with semantic data integrity and private sets of data is persistent data types. You can refer to this Wikipedia article for more details: http://en.wikipedia.org/wiki/Persistent_data_structure, I also like this brilliant presentation by Rich Hickey: http://www.infoq.com/presentations/Value-Identity-State-Rich-Hickey. The main idea behind persistent data types is you can have multiple versions of the data at the same time. So if one module doing long running data analysis it can just operate with immutable set of data while other modules on other threads may continue changing the actual data. Moreover having data in multiple versions can be used to perform Undo/Redo operations without any need for additional data.
The use of persistent data types is covering reading part of the problem, but if your application and hence data model is complex and consists of many various classes you want modifications to be atomic. Atomic means that multiple modification happening all at once or none of them. In another words you want all the changes in all persistent sets are occurred as one operation and if something went wrong, all of them are rolled back. So the next data consumer will get all the data available in consistent state.
These two concepts are very well understood and well known in database world as transactions and snapshots. They give you desired atomicity, consistency and isolation. The fact that persistent data structures keep multiple versions of data allows to not only Undo and Redo operations but also enable calculation of differences between two snapshots in some implementations. Such difference may play very important role to incremental update of screen but also allow better and faster algorithms that process or verify data. For example if you have a component that calculates an aggregation of the data, than it can calculate such aggregation on the difference and merge it to the total aggregation.
So all of this considerations brings us to some sort of store with transactions, snapshots, and ability to enumerate all the changes between two snapshots. Finally all of this should look like a number of instances of some classes so you can deal with them normally in your OO language.
All the databases have transactions, some of them have snapshots, but it is impractical to use them for this purpose by a few reasons. First data in the database is way too far from application, even if use of in memory database. Second there are no functionality to easy enumerate changes and undo/redo. So it is look like there is need for special purpose store.
Let me introduce one implementation of such store.
SnapStore
SnapStore is special purpose in memory relational database with fast access to records in any desired version. The object oriented access to records provided via wrapper classes that holds record identifier and properties just redirecting data to and from the actual record.
Here is how the store works:
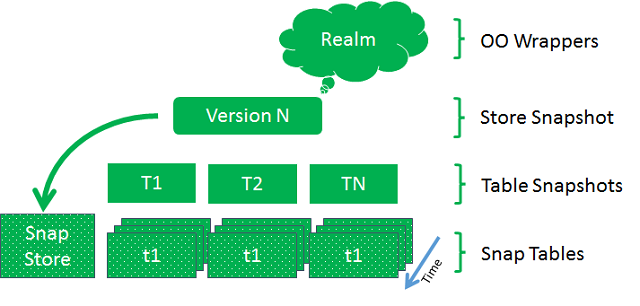
The cloud on the top represents objects wrappers that provide access to the actual data.
Next layer from the top is snapshot of the entire store. It consists of set of snapshots of tables on the next level. Each table snapshot actually querying corresponding SnapTable for data at version provided by store snapshot. This allow all the data in the snapshot to be consistent. Finally SnapTable is internal construct that holds data in all versions and shown on the bottom layer. The Snap Store is a set of Snap Tables that coordinates transactions. Both Snap Store and Snap Tables are not visible outside of the store and only snapshots exposing data.
It is possible to get many snapshots for one SnapStore and hence it is possible to have multiple sets of object wrappers. Each set of wrappers associated with one store snapshot called realm. Each realm is not thread safe, so if you need multithread access you need many realms and so as many store snapshots.
For reasons of simplicity of implementation store snapshot can be used not only for reading data but also for opening transaction and performing changes. So you can have many store snapshots each one is exposing its own version of data. Then one of them can decide to make modifications. So it opens transaction, performs as many changes as needed and commits the transaction. All the other snapshots will receive a notification that a new version of data is available, but the version they observing and hence the data will not change. Each snapshot can upgrade itself to the latest or any other version at any convenient moment later on. If the snapshot has realm than the realm get upgraded too.
Demo
To observe behavior of the snap store you can run demo application. In this application you have graphical editor of a surface with number of shapes called marbles on it. You can add, delete, move and change color of the marbles.

The application window consist of marble toolbar on the left, two marble editors, and one table viewer.
You can select shape of marble and color in the toolbar and click at desired point on current marble editor. The selected shape and color appear on the surface of editor. Version sliders will show an extra tick meaning the new version is available. You can select version of not current editor and view the data by moving the slider. You will look into the state of data at the selected version.
Lets’ have a closer look at the implementation of the demo application.
The store here consists from only one table. Structure MarbleData defining fields of the table. There are 4 fields in the structure. Each field has corresponding accessor class that is used by SnapTable to read and manipulate data.
TableSnapshot is generic class with its type parameter required to be a struct. The struct was chosen over class because struct can’t be referenced outside of table and hence changed out of scope of transaction. By this reason it is highly recommended to use value types or immutable classes as fields of the struct.
Class Marble is the wrapper class to access each record of the marble table. It holds id of the row and reference to MarbleStore which is inherited from StoreSnapshot. The properties of marble just calling methods of TableSnapshot with row id and field accessor. For example:
public double X {
get { return this.Table.GetField(this.MarbleRowId, MarbleData.XField.Field); }
set { this.Table.SetField(this.MarbleRowId, MarbleData.XField.Field, value); }
}
Class MarbleSet is wrapper for TableSnapshot and provides services for creating, finding, and enumerating marbles.
Class MarbleStore allows to create another snapshots, starts and commit transactions, and provides event notifications about versions changes.
All the marble classes actually partially generated by the tool ItemWrapper.Generator. This tool takes store description in MarbleStore.xaml and generates all wrappers necessary.
Now as you understand a big picture lets’ look at some implementation details of the snap store itself.
Implementation
The SnapStore is internal class and holds list of tables and a list of transactions. It allows to add tables until it gets frozen. After this is allows to open transactions.
The transaction can be opened by a StoreSnapshot instance associated with the store. If there is another running transaction the new transaction will not start. If your application required to start transactions concurrently, you will need to manage synchronization yourself. Once transaction is started it requires all the changes be made on the thread that started the transaction.
In many places in the SnapStore you will see code with try clause empty that looks like:
RuntimeHelpers.PrepareConstrainedRegions();
try { } finally {
}
This code looks strange at first glance, but if you read documentation about the very first function you’ll learn that this guarantee the thread will not be interrupted in finally clause.
Second important thing to understand is code is written in such way that any exception raised at any moment will not break integrity of the store. To achieve this there is a special class used for storing lists instead of standard generic List. The class called ValueList<T> allows to pre allocate memory required for one new element so the one following add operation will never throw due to out of memory exception. You can see for example that in the StartTransaction function in the try clause there this.version.PrepareAdd() called which will make sure there at least one empty element exists in the version list. Then in the finally clause you see this.version.FixedAdd call that will add new element. So basically the finally clause does not contain any code that can throw any exception at all and it defined as constrained region so no outer exception will interrupt the code. This allows to guarantee that no matter what exception happened the data structure’s integrity is not broken.
When the transaction is started it can be committed or rolled back. There are also two functions for performing Undo and Redo. Both actions will find which previous transaction need to be undone or redone, open new transaction, and performs all necessary modifications to eliminate changes of found transaction.
Now let’s see how the data get stored in the tables.
SnapTable
Each SnapTable consists of three lists. First is the list of rows that ever been added to the table. Second is the list that contains previous versions of data that was modified in any transaction other than transaction where the row was inserted. Finally the list that is called Snap which consist of state of snap table after the transaction that modified this table get closed.
On the picture above in table and log the very first column is not stored in the table, it is just row number. The Data columns in table and log is user defined data. On this picture it represented by string with first number is row number, and second is transaction number that set this value. The Log # filed is index of row in the Log table. The Row # is index of row in table list. The fields of the snap list are: Version is transaction number that inserted this row, Table Size is number of rows in the table list and Log Size is number of rows in the log.
When the SnapTable get created table list is empty, log lists contains one empty row, and snap contains one record. See the picture where Version is 0.
Lets’ say three rows were inserted in the first transaction. After the first transaction is committed the table list will contain inserted rows, the log will still has only one empty row and snap will have two rows. If in the second transaction row 2 was modified and value: Data 2.2 was set, then table will contain the new data, before the data is set it get copied to log, so log size will increased, Log # filed in table record 2 will be set to 1 - indicating the log row that contains previous data, and new record will be added to the snap. And so on.
So when a new row is inserted it appended to the table list, when existing row gets modified it first appended to log list if it was not done so in current transaction and then data gets modified. In both cases a new row appended in the snap list with current sizes of table and log lists.
When data get acquired from a row it always asked at some version, not necessarily latest and greatest. Reading methods first look for snap row that is best describes the version in order to find correct data. So the version in the Version column of the snap should be greater than asked version. Then if the index of log from the table list is less than log size in found snap record than user is asking for latest version. So the data gets read from table record. However it is possible that during this read some other thread had modified the record. So after the data acquired another check of log size is performed. If there were no any modification occurred then the data at hand is correct data in correct version. Otherwise the correct data is in the log. Reading the log is simple. It just needed to find correct log record and get data from there without any other complications.
As you can see completely lock free and unblocking way of getting data can be implemented fairly easy.
Snapshots
StoreSnapshot has a version number at which is providing data and bunch of functions to find TableSnapshot as well as wrappers for correct call to internal methods of SnapStore. It is also provides methods for changing version it is exposing. There are two public constructors of StoreSnapshot. First is parameter less. It used to create brand new snap store and empty snapshot for it. Later on number of tables expected to be added. The second constructor is getting another StoreSnapshot as a parameter. This constructor is used to create a new snapshot for existing snap store. Another important method is FreezeShape. This method must be called when application finished defining tables and indexes and before opening a new transaction. The transaction can be committed in two phase manner with PrepareCommit and commit itself. Prepare commit is checking for foreign key integrity. If it successfully executed than following commit will not throw any exceptions. You can also perform extra validation that is not changing the store after commit get prepared and before commit. Commit is coming in two forms. First is Commit and the second is Omit. The latest is marking the committed transaction as not undoable. This can be helpful in some cases. Another way to close transaction is to roll it back. The rollback will move the data to state it was before the transaction was started.
TableSnapshot provides number of methods for inserting and deleting rows and to get, search, and modify data in the existing ones. There is only one public constructor of TableSnapshot. In this constructor you will need to provide StoreSnapshot, name of the table and array of fields. This constructor will create SnapTable behind the scene and TableSnapshot itself. When new snapshot of existing snap store is created the other constructor will be called automatically in order to create all table snapshots for each snap table.
Because the store is relational database it is also allows to create some indexes for better searching performance and enforcing uniqueness. There are two indexes one is unique and another is interval. Both indexes implemented on top of SnapTable, so they are also version aware. In other words it indexing data at the correct version. The unique index is a hash table. The interval index is a B-tree.
You can also define foreign keys for tables and they enforced by store during committing transaction.
How to navigate the sources
When you open solution in Visual Studio you will see three solution folders and one project on the top. This project is sources of snap store itself. Demo folder contains marble demo application and it supposed to be a startup application. Tests folder contain unit tests. Finally Tools folder contains two utilities that helps to build solution. The ItemWrapper.Generator is the tool that is generating code for creating the store and realm. The other is also code generating tool that supports generation of resource strings with parameters.
Real life example
Besides the demo application you can see how the snap store is used in real life application. The application called LogicCurcuit and it is open source educational software for designing and simulating digital logic circuits. The application web site: http://www.logiccircuit.org/. You can get source code of the application at: https://logiccircuit.codeplex.com/SourceControl/latest.
The application actually using primarily storage and undo/redo capabilities of the snap store.
It uses multiple tables and whole bunch of indexes. The realm of store is generated in assumption of absence of thread concurrency so there is only one realm in the application. The helper tool that is generating the realm can generate such kind realms as well as multiple realms. The two types of reams called multiverse and universe. The LogicCircuit is using the universe one.
The file that describes the store structure is in Schema\CircuitProject.xml. All the realm and store related code is in CircuitProject folder.
The snap store code is actually right in the executable, so the code is just in DataPersistent folder.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 








