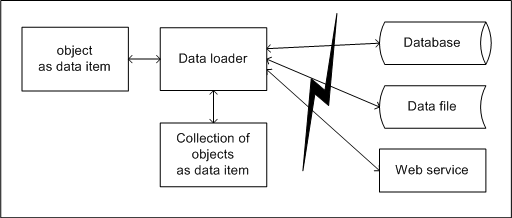
Overview of the data loader framework
Contents
Imagine the scenario
You've been asked by your boss to write a new system that comprises a desktop application that needs to talk to a web application via a web service and all using a database on your internal company network in Uruguay. What this system does is not important, but let's pretend it is an order tracking system ranging from the customer ordering online to the fulfillment in the warehouse. Your client sells books.
Your boss wants the system running by Sunday evening because your big client is going to sign it off on Monday morning at 9am. If he doesn't, you won't get paid this month.
Whilst I will be happy to come in and consult for $600 per hour... that might not be necessary. Look carefully at the system, and break it down into what you see as being the biggest development requirements. My list would look like this:
- Design the data requirements.
- Define the business logic.
- Create the database.
- Implement the data access layer.
- Develop the web service, the web site, and the desktop application.
- Book a long vacation.
Your boss has just sent you a memo – it is thirty minutes until the client will be on site: they will be running a MySQL database not SQL Server as previously thought. That isn't a problem, is it? Surely, you didn't use SqlConnections and T-SQL specific queries? Oh, you did? So did I.
Take a step back
Now, imagine if you could just ignore the data and work with real objects. No more SELECT Field FROM BigTable WHERE Id=1, but instead a new BigObject(1). That is where data loaders come in.
In broad terms, a data loader loads data into data items. A data item is any object that contains a definition of its data requirements and usually all of its logic. Data items don't care where they get their data from; it could be a Microsoft Access database, SQL Server, or an encoded text file on a floppy disk. The data loader takes the definition of the data item and directions to the data source, and maps them together.
Data loaders work both ways – that is loading and unloading data from data items. Data items are not connected in any way to their data source, nor indeed do they ever know about it. You do not even set up your data source yourself – the data loader will take care of creating your database structures ensuring they are valid for your data requirements.
Now read that again, because it is very important.
Sadly, this is almost too good to be true so there are compromises. If you follow the guidelines, you will lose some of the functionality you would have when writing database-aware applications such as being able to use stored procedures or DBMS-specific SQL functions; and in some high-volume cases, you will lose performance if you are not very careful. (This is unlikely to present a problem with non-database-data loaders.) Data loaders are required to expose members that allow you to break the ‘data source transparency' rule if your implementation does not need it, but this is otherwise not recommended as you won't be able to use the write-once-use-anywhere capabilities.
As briefly mentioned, a data loader can take its data from anywhere capable of providing it. The source code accompanying this article contains implementations for optimized SQL Server, MySQL and Microsoft Access data loaders, but data loaders that work over SOAP, using XML files, or using a bespoke data source are all possible.
If you follow the rules, then for rapid data-based object creation without limiting to a specific data source, there is virtually no parallel.
Out of the frying pan
Back to our example system. With data loaders, you can revise your development requirements considerably:
- Design the data requirements.
- Define the business logic.
- Develop the web service, the web site, and the desktop application.
- Take the weekend off.
It should be noted that removing the redundant steps from your requirements doesn't drastically increase the development time of the others – it merely increases their scope a little. Once you have created a few data items, you won't even notice.
Into the fire
Let's look at a very basic data item. This is for a book. I have split it into sections to explain what is going on. To start with, we define our new object and implement the IDataItem interface.
public class Book : Bttlxe.Data.IDataItem
{
protected int m_nId = -1;
protected string m_strTitle = "New Book";
protected DateTime m_dtPublished = DateTime.Now;
public int ID
{
get
{
return m_nId;
}
set
{
m_nId = value;
}
}
public string Title
{
get
{
return m_strTitle;
}
set
{
m_strTitle = value;
}
}
public DateTime Published
{
get
{
return m_dtPublished;
}
set
{
m_dtPublished = value;
}
}
So far we have just set up a standard object that exposes its data. Now, we will implement IDataItem. It may help to read the definition for the Schema property before the Data property.
#region IDataItem Members
public virtual DataSet Data
{
get
{
DataTable dt = Schema.Tables["Book"].Clone();
DataRow oRow = dt.NewRow();
oRow["ID"] = m_nId;
oRow["Title"] = m_strTitle;
oRow["Published"] = m_dtPublished;
dt.Rows.Add(oRow);
DataSet ds = new DataSet("Book");
ds.Tables.Add(dt);
return ds;
}
set
{
m_nId = (int)value.Tables["Book"].Rows[0]["ID"];
m_strTitle = (string)value.Tables["Book"].Rows[0]["Title"];
m_dtPublished =
(DateTime)value.Tables["Book"].Rows[0]["Published"];
}
}
public virtual DataSet Schema
{
get
{
DataTable dtSchema = new DataTable("Book");
dtSchema.Columns.Add("ID", System.Type.GetType("System.Int32"));
dtSchema.Columns.Add("Title",
System.Type.GetType("System.String"));
dtSchema.Columns.Add("Published",
System.Type.GetType("System.DateTime"));
dtSchema.Columns["ID"].AllowDBNull = false;
dtSchema.Columns["ID"].AutoIncrement = true;
dtSchema.Columns["ID"].AutoIncrementSeed = 1;
dtSchema.Columns["ID"].AutoIncrementStep = 1;
dtSchema.PrimaryKey = new DataColumn[]{dtSchema.Columns["ID"]};
dtSchema.Columns["Title"].AllowDBNull = false;
dtSchema.Columns["Title"].DefaultValue = m_strTitle;
dtSchema.Columns["Published"].AllowDBNull = false;
dtSchema.Columns["Published"].DefaultValue = m_dtPublished;
DataSet ds = new DataSet("Book");
ds.Tables.Add(dtSchema.Copy());
return ds;
}
}
Hopefully, the above code is easy to follow. For the schema that describes the data the data item uses, we are creating a data table of the required format, and adding columns in the standard way to represent attributes of the Book object we are defining. The primary key (or keys) are important as they will be singled out to identify data items for operations requiring unique identification (such as updates).
Note: we are setting the ‘ID' attribute to be self-incrementing on the data source.
The Schema property wraps this schema into a normal DataSet object. (The reason a DataSet is required by the IDataItem interface is so that a data item can expose more than one DataTable as discussed later.)
The Data property both exposes the data in the schema format (for use by the data loader) and reads the data from a matching format into \ the object's attributes (for use by your objects).
public virtual string Condition
{
get
{
return string.Empty;
}
set
{
}
}
public virtual string Sort
{
get
{
return string.Empty;
}
set
{
}
}
#endregion
The Condition and Sort properties are redundant for objects that represent a single item. If this data item was representing a list of books, you would implement these properties using standard SQL conditions and order-by clauses (or if the data source is not a database, then XPath, or other query language).
public Book()
{
}
public Book(int nId)
{
string strSql = "SELECT * FROM [Book] WHERE [ID]=" + nId;
this.Data = Bttlxe.Data.GlobalDataLoader.Loader.Execute(strSql).Data;
}
public Book(int nId, ref Bttlxe.Data.IDataLoader loader)
{
string strSql = "SELECT * FROM [Book] WHERE [ID]='" + nId;
this.Data = loader.Execute(strSql).Data;
}
}
This is the ‘glue'. Both constructors that load the Book object perform the same task. GlobalDataLoader.Loader, as used in the first function, is merely a static/shared data loader that you can use to avoid passing references around once you have your data loader set up.
The first line simply constructs a SQL query that uses the Book.ID passed in with the parameters to select all of the data for a specific book. Nothing new there.
The second line calls the Execute member of the data loader you're about to create in the next section which returns a generic object implementing IDataItem. By setting our Book object's Data property to the Data property of the returned data item, we load the data into our object.
Creating a Book object is now as simple as calling:
Book oBook = new Book(1);
What if you want to save a Book object though? It is easier than you might think – you just reverse the way you use the data loader's Execute member:
Bttlxe.Data.IDataItem di = (Bttlxe.Data.IDataItem)oBook;
Bttlxe.Data.GlobalDataLoader.Loader.Execute(ref di,
Bttlxe.Data.DataOperation.Update);
First, we cast our object back to its interface, and then we pass the data item to the data loader and instruct it to perform an ‘update' operation. Behind the scenes, the data loader constructs an optimized UPDATE statement and executes it (assuming the data loader works with a DBMS).
But hang on – update what? We don't have any database structure!
Bttlxe.Data.GlobalDataLoader.Loader.Execute(ref di,
Bttlxe.Data.DataOperation.Create);
Now we do. (To make this easier, there is a DataSourceValidator object which lets you check the validity of a data item on a data source and optionally create it automatically or throw you back an exception.)
Read, Write, Update, Create, Delete and Drop are all valid operations. For example, if you would prefer not to include SQL statements in your Book object constructor (say if you were using an XML-based data loader):
public Book(int nId, ref Bttlxe.Data.IDataLoader loader)
{
m_nId = nId;
Bttlxe.Data.IDataItem
di = (Bttlxe.Data.IDataItem)this;
loader.Execute(ref di, DataOperation.Read);
}
Your existing objects can easily implement the IDataItem interface to take advantage of this approach.
Creating a data loader
There are two ways to do this. A more customizable approach is discussed later on, but for simplicity's sake, this is how you would create a data loader that deals with a SQL Server database:
Bttlxe.Data.SqlDataLoader oLoader = new Bttlxe.Data.SqlDataLoader();
oLoader.Database = "BOOKDB";
oLoader.Server = "SERVERNAME";
oLoader.UserID = "sa";
oLoader.Password = "IShouldntUseBlankPasswords";
oLoader.IntegratedSecurity = false;
oLoader.RemoteServer = "";
Bttlxe.Data.GlobalDataLoader.Loader = oLoader;
Here, we create a new SqlDataLoader and tell it some information about our database. The final step is to optionally store the data loader in the static/shared GlobalDataLoader.Loader object.
(Note that not all of those properties need to be set, but are shown for completeness. Each data loader can implement different properties – these ones are obviously only suitable for a DBMS data source, so check the data loader documentation for the correct syntax.)
For comparison, this is how you would create a Microsoft Access data loader:
Bttlxe.Data.AccessDataLoader oLoader = new Bttlxe.Data.AccessDataLoader();
oLoader.Provider = Bttlxe.Data.AccessProviderVersion.MicrosoftJetOLEDB_4_0;
oLoader.DatabasePath = @"c:\mypath\data.mdb";
Moving forward
By now, I hope you have an understanding of how and why data loaders are useful. The real power comes from being able to implement your objects without having any pre-requisites on the data source. Greater power comes from being to hot-swap data loaders, or mix and match them throughout your applications without any consideration being given to your implementations. I strongly encourage you to spend a few moments with a notepad and pencil thinking about our example system and how the data loaders and data items can help with it to get a better idea for their purpose, before continuing.
Now, we will step inside the data loaders and explore some of the more advanced tasks you can perform with them. We'll start by looking at the data loader interface and supporting classes. I have stripped out some comments but be sure to read those remaining because I won't elaborate much:
public interface IDataLoader
{
be present for the lifetime of the data loader.
void Initialise();
void Terminate();
object ExecuteScalar(string strQuery);
query to evaluate.</param>
any result.</returns>
DataTable ExecuteDataTable(string strQuery);
IDataReader ExecuteReader(string strQuery);
XmlReader ExecuteXmlReader(string strQuery);
int ExecuteNonQuery(string strQuery);
IDataItem Execute(string strQuery);
void Execute(ref IDataItem dataItem, DataOperation operation);
event NameMappingCallbackHandler NameMappingCallback;
}
The Execute methods are the recommended way of using data loaders with data items. The other members exist to give you greater control, but care must be taken not to introduce incompatibilities in your code if you plan to use different data loaders.
Name mapping will be discussed in more detail later on, but in broad terms, its purpose is to map the names of the items in a data item schema to the names used on the data source if they are different (for example, the column names in a database table might follow a best-practice naming convention that doesn't translate to your object naming convention). The NameMappingCallback event is defined as such:
public delegate void NameMappingCallbackHandler(string table,
ref DataItemDictionary keys);
Finally, the DataItemDictionary object is defined as:
[Serializable()]
publicclass DataItemDictionary : DictionaryBase
{
}
That's the pre-requisites done; now for the details.
How does a data loader load?
Looking at the SqlDataLoader:
Bttlxe.Data.SqlDataLoader oLoader = new Bttlxe.Data.SqlDataLoader(false, true);
oLoader.Database = "BOOKDB";
oLoader.Server = "SERVERNAME";
oLoader.IntegratedSecurity = true;
Once created, then when any method that requires the database is called, the connection to the database will either be opened or taken from its previous state and reused. SqlDataLoader takes two optional Boolean parameters to the constructor - the first states whether to keep the connection alive for the lifetime of the data loader, and the second whether to output tracing information to help with debugging.
Before we can look at the code that loads and unloads the data from your data items, we need to understand how data loaders use them. Remember that a data item is any object that implements the IDataItem interface to expose a schema that describes its data. This schema is used by the data loader to determine the types, sizes and other metadata that is necessary to both store and retrieve your data on the data source – in this case, a SQL Server database named ‘BOOKDB'. The schema is an instruction guide for using data items, but it doesn't contain any instructions for performing operations on the data source with the data it exposes. This is where each data loader implementation steps in to provide its optimized solution based on the operation it is instructed to perform:
| Read | A read operation, such as selecting data from a data source. |
| Write | A write operation which will execute an Update if the data already exists. |
| Update | A write operation which will update existing data and fail if the data does not exist. |
| Create | A create operation creates a DataTable on a data source. |
| Delete | Deletes data from a data source. |
| Drop | Drops a table from a data source. |
As we are using the SqlDataLoader and the Book object previously defined, it may help to think of each operation in terms of their respective SQL statements:
| Read | SELECT * FROM Book WHERE ID=1 |
| Write | INSERT INTO Book (ID, Title, Published) VALUES (1, 'Title', '1 January 2000') |
| Update | UPDATE Book SET Title='Title', Published='1 January 2000' WHERE ID=1 |
| Create | CREATE TABLE Book (<BR> ID INT NOT NULL IDENTITY(1,1) PRIMARY KEY,<BR> Title TEXT NOT NULL DEFAULT('New Book'), <BR> Published DATETIME NOT NULL DEFAULT(getdate())<BR>) |
| Delete | DELETE FROM Book WHERE ID=1 |
| Drop | DROP TABLE Book |
(Note that a Write operation will perform an Update if the data item already exists on the data source. Syntax and any necessities such as allowing identity columns to be set are handled internally by each data loader.)
If we take the constructor from our Book object and walk through what is happening, the process should become clearer:
public Book(int nId, ref Bttlxe.Data.IDataLoader loader)
{
m_nId = nId;
Bttlxe.Data.IDataItem di = (Bttlxe.Data.IDataItem)this;
loader.Execute(ref di, DataOperation.Read);
}
This version of a data loader's Execute method takes a reference to the data item and the operation it should perform with or on it; in this case, we pass it our Book object and a Read operation. In general terms, this is what happens:
- The data loader retrieves the schema for the
Book object.
- If a name mapping callback event has been registered with the data loader, it will transform the data item column names to those that are present on the data source.
- A SQL statement is constructed using the metadata provided in the schema. As the Book's ID attribute is the primary key (hence unique), it will be used to append a
WHERE clause.
- If the data item provides
Condition or Sort properties, they are merged into the SQL statement.
- The operation is now described in a SQL Server-specific format so the
ExecuteDataTable member is called to fetch the results of the SQL query. This function will open the connection if not already available and process the request.
- The data returned is now mapped back into the data item we passed in via its
Data property and using reverse name mapping if necessary.
Our Book object now contains the data in its own attributes and properties ready to be used by our system.
The other version of a data loader's Execute method doesn't take a reference to the data item, but instead is passed a data source-specific language statement (such as a SQL statement), and using the data returned by the data source, constructs its own generic data item using the schema it retrieves from the data source, and returns that. This is the method used in the other Book object constructors:
public Book(int nId, ref Bttlxe.Data.IDataLoader loader)
{
string strSql = "SELECT * FROM [Book] WHERE [ID]='" + nId;
this.Data = loader.Execute(strSql).Data;
}
How does a data loader unload?
In much the same way it loads data into data items, a data loader can take the data with the schema and construct Insert and Update SQL statements, send objects over SOAP to be stored, write a data item to disk, etc. The specific implementations are outside the scope of this article but you are encouraged to read into the data loader implementations to fully understand how they work.
Stepping in and taking control
What we have covered so far is all you need to know to start using data loaders. Sometimes, we might need a little bit more control over the process than we have had so far though, and that is where callback events come in.
IDataLoader requires all data loaders to issue a NameMappingCallback event, defined as:
public delegate void NameMappingCallbackHandler(string table,
ref DataItemDictionary keys);
If we subscribe to this event, then every time we call one of the data loader's Execute members (including non-data item functions such as ExecuteDataTable or ExecuteScalar), we can step in, and using a DataItemDictionary, control how the data item is mapped onto the data source. It is easier to explain this with an example:
Bttlxe.Data.SqlDataLoader oLoader = new Bttlxe.Data.SqlDataLoader(false, true);
oLoader.Database = "BOOKDB";
oLoader.Server = "SERVERNAME";
oLoader.IntegratedSecurity = true;
oLoader.NameMappingCallback += new
NameMappingCallbackHandler(Loader_NameMappingCallback);
public void Loader_NameMappingCallback(string table,
ref Bttlxe.Data.DataItemDictionary keys)
{
keys.Clear();
switch (table)
{
case "Book":
keys.Add("ID", "bk_id");
keys.Add("Title", "bk_title");
keys.Add("Published", "bk_published_date");
break;
}
}
Using an example given earlier, with this name mapping callback, the following SQL query using data item names...
INSERT INTO Book (ID, Title,
Published) VALUES (1, 'Title', '1 January 2000')
...would be transformed into the following SQL query using data source names:
INSERT INTO Book (bk_id, bk_title,
bk_published_date) VALUES (1, 'Title', '1 January 2000')
Name mapping is especially useful if your data loader is connecting to existing data, or you need to take data from different sources and load them into the same data items. For example, a database might contain the book information, but a web service is used to return the current price direct from the publisher.
True transparency
Whilst what we've covered allows you a great deal of separation from your data source, you can't easily change from, say, a SQL Server data source to a MySQL one without changing all your data loader references from SqlDataLoader to MySqlDataLoader. If you use the GlobalDataLoader.Loader static/shared object, then you may only need to change one or two lines of code, but that's still not true separation.
This code isn't part of the data loader / data item framework per se, but it can be useful in situations when you want to be able to change your data loaders without changing your code. App.Configuration is an object that contains configuration properties for your application, maybe taking information you have specified via the command line or in a configuration file:
switch (App.Configuration.DataSourceType)
{
case DataSourceType.MicrosoftAccess:
{
AccessDataLoader oLoader = new AccessDataLoader(
App.Configuration.DatabaseKeepAlive,
App.Configuration.DatabaseTraceEnabled);
oLoader.Provider = AccessProviderVersion.MicrosoftJetOLEDB_4_0;
oLoader.DatabasePath = App.Configuration.Database;
oLoader.UserID = App.Configuration.DatabaseUserId;
oLoader.Password = App.Configuration.DatabasePassword;
oLoader.Initialise();
GlobalDataLoader.Loader = oLoader;
break;
}
case DataSourceType.MySql:
{
MySqlDataLoader oLoader = new MySqlDataLoader(
App.Configuration.DatabaseKeepAlive,
App.Configuration.DatabaseTraceEnabled);
oLoader.Database = App.Configuration.Database;
oLoader.Server = App.Configuration.DatabaseServer;
oLoader.UserID = App.Configuration.DatabaseUserId;
oLoader.Password = App.Configuration.DatabasePassword;
oLoader.Initialise();
GlobalDataLoader.Loader = oLoader;
break;
}
case DataSourceType.SqlServer:
{
SqlDataLoader oLoader = new SqlDataLoader(
App.Configuration.DatabaseKeepAlive,
App.Configuration.DatabaseTraceEnabled);
oLoader.Database = App.Configuration.Database;
oLoader.Server = App.Configuration.DatabaseServer;
oLoader.UserID = App.Configuration.DatabaseUserId;
oLoader.Password = App.Configuration.DatabasePassword;
oLoader.IntegratedSecurity =
App.Configuration.DatabaseIntegratedSecurity;
oLoader.RemoteServer = App.Configuration.DatabaseRemoteServer;
oLoader.Initialise();
GlobalDataLoader.Loader = oLoader;
break;
}
}
So if App.Configuration was reading in an xml.config file, it could look like this:
="1.0"="utf-8"
<configuration>
<datasource>
type="SqlServer"
database="BOOKDB"
server="SERVERNAME"
intergratedAuthentication="true"
keepAlive="false"
traceEnabled="true"
/>
</datasource>
</configuration>
And it could easily be changed to this:
="1.0"="utf-8"
<configuration>
<datasource>
type="MySql"
database="BOOKDB"
server="MyServer"
userId="username"
password="password"
keepAlive="false"
traceEnabled="true"
/>
</datasource>
</configuration>
Performance
This is especially relevant for web applications: Cache and cache often. A desktop application can load a data item once and keep it locally, but web applications will typically need to load data items on each request. For small user loads, this won't present a problem, but if you have one thousand users hitting your web site every minute and each time twenty book objects are being loaded into data items, then your data source is going to be in a lot of pain. Something as simple as caching your objects and performing a quick "if object is cached then clone it else get a new one and cache it" can improve your performance by many hundreds of percent.
Lists of data items
You may have spotted a limitation with the approach discussed so far – how do you select everything for a list of objects from a data source? In SQL, you can do a SELECT * FROM Books to retrieve all of the books at once. Obviously, this is considerably better than hitting the data source individually for each book. But you can't do this with data items.
Well, you can if you think about it logically: Create a BookList data item whose schema supports Book items and retrieves all of the books from the data source at once.
Consider the following data item implementation:
[Serializable()]
public class BookList : IEnumerable, IEnumerator, Bttlxe.Data.IDataItem
{
private ArrayList m_aItems = new ArrayList();
private int m_nPosition = -1;
protected string m_strCondition = string.Empty;
protected string m_strSort = string.Empty;
As this data item represents a list of data on the data source, we will implement the Condition and Sort properties when we implement IDataItem below.
#region Enumerator
public IEnumerator GetEnumerator()
{
m_nPosition = -1;
return (IEnumerator)this;
}
public bool MoveNext()
{
m_nPosition++;
if (m_nPosition < m_aItems.Count)
return true;
else
{
m_nPosition = -1;
return false;
}
}
public void Reset()
{
m_nPosition = -1;
}
public object Current
{
get
{
return m_aItems[m_nPosition];
}
}
public ArrayList Items
{
get
{
return m_aItems;
}
}
public void Add(Book oItem)
{
m_aItems.Add(oItem);
}
#endregion
By implementing the .NET Framework's IEnumerable and IEnumerator interfaces, we can do things like data binding our data item to controls and use the foreach construct - foreach (Book oBook in oBooklist).
#region IDataItem Members
public DataSet Data
{
get
{
DataTable dt = Schema.Tables["Book"].Copy();
foreach (Book oItem in this)
{
DataRow oRow = dt.NewRow();
oRow["ID"] = oItem.ID;
oRow["Title"] = oItem.Title;
oRow["Published"] = oItem.Published;
dt.Rows.Add(oRow);
}
DataSet ds = new DataSet("Book");
ds.Tables.Add(dt);
return ds;
}
set
{
Items.Clear();
foreach (DataRow oRow in value.Tables["Book"].Rows)
{
Book oItem = new Book();
oItem.ID = (int)oRow["ID"];
oItem.Title = (string)oRow["Title"];
oItem.Published = (DateTime)oRow["Published"];
Add(oItem);
}
}
}
The Data property uses each row in the DataTable to create a new Book object and set its data using its own properties rather than using the Book object's Data property. The process is simply reversed for returning its data to a data loader.
public DataSet Schema
{
get
{
return new Book().Schema;
}
}
The schema for a BookList is exactly the same as the Book object.
public string Condition
{
get
{
return m_strCondition;
}
set
{
m_strCondition = value;
}
}
public string Sort
{
get
{
return m_strSort;
}
set
{
m_strSort = value;
}
}
#endregion
The Condition and Sort properties (if set) will be used to sort the Books in this collection when a BookList is passed in to a data loader's Execute member.
public BookList()
{
string strSql = "SELECT * FROM [Book]";
this.Data = GlobalDataLoader.Loader.Execute(strSql).Data;
}
public BookList(bool bAlphabetical)
{
if (bAlphabetical)
{
string strSql = "SELECT * FROM [Book] ORDER BY [Title]";
this.Data = GlobalDataLoader.Loader.Execute(strSql).Data;
}
else
{
string strSql = "SELECT * FROM [Book]";
this.Data = GlobalDataLoader.Loader.Execute(strSql).Data;
}
}
}
The first constructor is similar to the first Book constructor, but no WHERE condition is specified so the generic data item returned by the data loader will contain data for each book on the data source.
The second constructor shows how to sort the data when it is loaded.
Remember that even when you specify data source-specific statements such as SQL statements in this way, they will still be parsed and subject to name mapping if defined for the data item.
Limitations and considerations
You can't have relationships in your data. This is a big consideration, so make sure you understand it fully before you try and use data loaders: You can't have relationships in your data.
If you're using a data loader that works with a DBMS, if you use joins in any queries you specify yourself, any name mapping will only apply to the first table you are selecting from. Most SQL functions like CONVERT or SUM, etc., should work correctly.
Don't use complex queries without understanding how the data loader you will be using will handle them. I haven't run into any problems that couldn't be easily solved myself, but that doesn't mean you won't. Turn on tracing for your data loader and depending on the type of application you are developing, you will see what is being sent by the data loader to your data source in the web trace or debugger output window.

Example trace shown for a web application
When specifying SQL, always wrap table and column names in square brackets, such as SELECT [Title] FROM [Book] WHERE [ID]=1. The database data loaders use those to help them analyze the query and perform name and schema mapping. If unsupported for the DBMS, the relevant data loader will strip them out internally. Use white space only as necessary.
Ideally, you won't write any data source-specific code anyway.
Remember that if your data item schema allows a DBNull value for a column, then you must check for null values when you load your data.
Conclusion
Data loaders let you build applications without passing thought as to how the data will be stored or transported. Used correctly and for the right reasons, this can be a powerful method for rapid and extensible data to object binding.
This is the first time I have tried to strip something out of a larger code library, and whilst I have tested it prior to publishing this article, there is a chance I have missed something in the rewrite. The accompanying developer documentation contains links to report any problems which I will do my best to resolve.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




