A similar algorithm has been already published in Russian on my site.
Introduction
Sooner or later, any programmer runs into the necessity of the obvious use of one or the other method of sorting. Not looking at that, this theme is well investigated and there are many wonderful sorting algorithms, there are some nuances at their practical use. At first, it is a problem of choice. Indeed, how to choose the best, especially as clear recommendations are not present. As the saying goes, every algorithm is good in its own fashion. Secondly, there is always a problem of realization as it applies to a practical task. Possibly, the experience of the author in this area can appear useful to someone; therefore, we will describe our researches and practical results.
Although usually choosing a concrete algorithm of sorting is an arduous duty, it is fully possible to be determined with a class of algorithms, depending on a given task. In my case, this was the necessity of the independent sorting of string data from the set column of tabular database (concretely dbf file) in an external file buffer, i.e., sorting on determination must be external because a source file can be large enough (gigabyte and more) and in addition sorting can be carried out for a few columns simultaneously. A sorting purpose is a creation of index file for one or a few the fields of data. Here, we will not discuss whether it is needed or not needed to do the similar sorting, when there exists a great number of software products, especially oriented to work with databases, and are already doing this well enough. There are cases, when it is not desirable without an absolute necessity to attract external programs for your own programs which are not very difficult. Therefore, we will make an effort to decide on this task in the indicated formulation.
So, we were determined, that we were interested by an algorithm of external sort. As we were not going to modify the source of data, for sorting of one data column, we may have needed two file buffers, their sizes being equal to the amount of data multiplied into the length of field of data. Really, we will yet interest to the row number of every string data field for the purpose of indexing. As for Win32, the size of long integer equals 32 bits or 4 bytes, we need be increase the field length in bytes yet on 4 bytes.
It is known that the Merge Sort method is comfortable for the general sorting of a few long ordered subsequences. This method chooses a maximal or minimum value consistently from data queues and writes it down in the sought-for sequence. If basic data are not presented as a few Ordered SubSequences which we will name OSS too, such OSS should be got, that is be split by any way. Let us say, the relatively small sequence of casual data are sorting out in memory by anything comfortable for these aims algorithm, for example, by the quick sort algorithm. It is clear that instead of merger a few OSS we can limit by any two of them, when one will not be a unique OSS.
It is obvious that there are a lot of variants of Split functions and on this theme are published enough information. Thus, an external sort is not limited to only the Merge Sort method; however, we will not use other methods, because we are fully arranged by the base class of algorithms of external sort examined here.
So, we need to be determined with the choice of a Split function and amount of OSS simultaneously in-use for the Merge function. The second question decides easily, we will simply choose a pair wise merge technique, because it is very comfortable for realization. Remainder will be determined with a Split function.
The Split function can assort in memory relatively small data subsequences or in some way to extract OSS from the given sequence. We at once renounce the additional sorting in memory, at first, it complicates a general algorithm, and secondly, this is more substantial, already existent ordered subsequences (OSS) are lying idle. It is logical to name methods of extraction in natural way already ordered, subsequences from the given data sequence as Natural Split, and the method of sorting as Natural Merge Sort. Similar terms indeed exist, so in literature there are the followings types of the Natural Split and Merge:
- The initial data sequence is examined as a great number of OSS of length 1 byte, which are ordered on definition. Two OSS of length 1 are joined in one two, in the second buffer, double two in a four into the first buffer (or into the source file, if this change is admitted) and so alternately.
- The initial data sequence fissions on successive series, i.e. non-decreasing OSS. At confluence at the first series’ distributing of initial A file is executed alternately into temporary files of B and C, and then confluence of B and C files in A file etcetera while there will not be one series.
- The initial data sequence fissions on series simultaneously with beginning and ending with these series at once unite into the first buffer alternately in its beginning (in direct order) and ending (in reverse order). Then this buffer becomes by the data source and result is directed into the second buffer (or into the source file, if its change is admitted). Then the first and second buffers switch places et cetera. The name of this algorithm is Natural Two-Way Sort Merge.
Obvious lacks of these algorithms are that the first case is not taken into account by the already being order of data, and the second and third does not take into account decreasing OSS. In addition, three buffers are actually used in second case, if we set a condition do not change source of data, while it is easily possible to treat two, as in the first and third cases.
I have not found in literature the fourth variant of the «natural splitting and merging» of initial data described below, although it does not mean, that it is not yet known. In this case, it is easy to «reopen» this algorithm, than to find it. - The initial sequence of file data is split in OSS of random order (both non-decreasing and decreasing). Then all of OSS in pairs (for various pair, including accrued) is merged into the proper file buffer, into proper place.
To do the similar splitting only one time and not take under the data structures of Split function, the array of data proportional the size of initial file; we will at once use derivable information. In this case, we may need the additional array of structures of the fixed size. For Win32, the maximal dimension of array will be equal to 32. Non-decreasing OSS merge from beginning, and decreasing from the end into any free file buffer. If one OSS is into the first buffer, and second into the second, before their merging the OSS from the first buffer simply are copied into the second, and then two OSS of the second buffer meet into the first buffer in the proper positions. Obviously, only two buffers are enough, and if we do not want to do the operation of copying, three. However, we prefer the transfer of data block to the third buffer, for the sake of economy of disk space.
Realization of this algorithm is enough difficult and depends on substantial appearance from binary decomposition of number of ordered subsequences. An algorithm disintegrates in two parts. The first part does even (various pair wise) associations and the second one merges odd («hangings up») OSS. Information about odd OSS are kept in the array of structures mentioned above by a dimension 32. We are interested by those elements of the array whose indexes coincide with the degrees of binary decomposition of this number of OSS. Naturally, if amount of all initial OSS is the degree of two, we need not do the second part of algorithm. For the detailed illustration of the algorithm, we demonstrate many pictures.
Advantage of the indicated algorithm is that it uses the present partial order of data on a maximum. Moreover, even in the case of the absolute evenly distributed casual data sequence, middle length L0 of their OSS are more than 2, because any two comparable values always form an OSS. In the special case of «zigzag» data sequence of arbitrary even length, middle length L0 of the OSS is equal in exactness to two. For example, for any even sequence of zeros and ones:
{0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,0,1, . . .} : L0 = Lmin = 2.
Actually, this sequence possesses the minimum order for the aims of our algorithm. However, our advantage is one passageway for Split function, fixed size of data for its parameters and presence only of two file buffers (taking into account invariability of initial data).
However, let us go back to the case of the evenly distributed casual data sequence. What middle length L0 (determined as relation of total length of sequence per the amount of its OSS) is? Clearly, that in this case:
L0 > Lmin = 2
and therefore we can use this additional order for more quick sort. It maybe is already algorithmic advantage.
A task of the calculation of middle length L0 of OSS for the evenly distributed casual data sequence does not seem very difficult, however although we tried hard, we did not find the answer in the Internet. It was therefore necessary to perplex a Russian forum of mathematicians and after the joint discussion of the problem (in the theme: Distributing of order into all transpositions where I am under nickname Scholium) we were able to calculate this value:
L0 = 2e – 3 = 2.436563656918 .
It is interesting, is not it? Any casual sequence possesses partial order more minimum! The order of real data is always higher than absolutely evenly distributing of casual values. That is why we are especially attracted by this algorithm.
Now, we go directly to description of our algorithm.
Description of the Algorithm
It consists of two basic operations.
- Splitting given sorted sequence S on set of locally arranged (by increase (not to decrease) or by decrease) subsequences {S1, S2, S3, . . . , SN} where all subsequences, except, perhaps, last contain more than one record (key). Arranged subsequence Sn for brevity we will name OSS Sn.
- Merging adjacent pairs of OSS of one level in one (from left to right or from top to down), taking into account an order of streamlining of these subsequences, i.e., the decreasing sequence merges from «end», and increasing with «beginning».
These two operations repeat themselves until all sequences of S do not consist of one only subsequence, i.e., while it is not arranged.
The example of usage of the given sort algorithm is shown in fig. 1. The first line is the given (invariable) sequence, last is required (sorted) one.
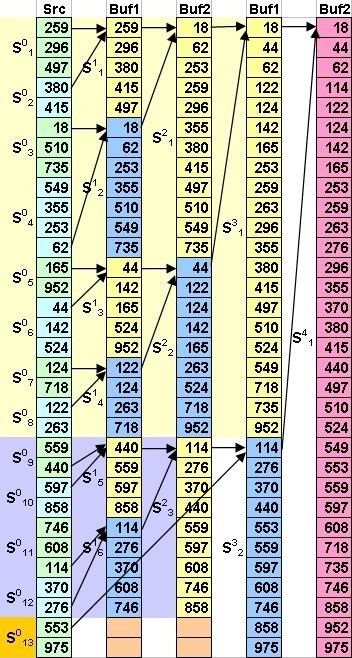
Fig. 1. A sorting example by «Natural Merge» for an invariable source. The order of operations merging / splitting is specified by red digits.
Simple Algorithm of External Sort by «Natural Merge»
Let it be given external (file) source of OSS S0 and enough M of external (file) buffers {S1, . . . , SM} into the necessary size. Source S0 should not vary, and buffers {S1, . . . , SM} can change of their contents. It is required to receive sorted source S0 in some buffer, using paired merging of the arranged subsequences.
- If source of OSS S0 is empty, the algorithm is ended (there is no data).
- If source S0 contains only one OSS then it is required, taking into account a sort order of this OSS. The algorithm is ended.
- If quantity of OSS of a source is more than one, then S0 mutually (it is defined by function Split) merges (function Merge) into S1, S1 into S2 etc., while into SM does not remain unique OSS. If in flowing Sk (1 <= k < M) is available not merged OSS (at odd quantity of all OSS of the given level k) it is simply copied in the nearest buffer SM where also contains not merged OSS, on its place (K > k) provided that k and K have different parity. Then again derivated pair OSS merges. If k and K have identical parity, i.e. actually are in one buffer then they merge at once, without copying. And so before reception unique finite OSS. The algorithm is ended.
Optimization of Simple Algorithm
It is easy to see that the M number can be reduced to two. Besides, last odd OSS there is no necessity to copy some times before its merging, it is enough to do no more than once. The truth in this case maybe merging from two different sources is required (fig. 1) in the free buffer that will a little complicated function Merge. Function Split needs to be applied no more an once and to use its results at once, not to store the superfluous data.
- We select current adjacent pair of OSS at pass on all required records of the source. The data odd OSS is saved in a zero array cell of structures of this data.
- The current data even OSS is merged with the saved data previous odd OSS by means of function
Merge in the appropriate buffer. - If in the merging buffer given merged OSS is odd, then it saved its parameters in a following array cell of OSS data structures, else (for even OSS) it is merged into other buffer.
The Description of Function Split
Function Split, which is fulfilled only once (in one pass), should define the beginning and the end of a current subsequence, its length, a sort order (1 for a non-decreasing subsequence, –1 for decreasing one and 0 for the OSS consisting only of one element, closing a current data series), and also addresses of sources of OSS and the target buffer, the parameters characterizing data proper, etc.
To do that, it is enough to have quantity of the elements more than two, i.e. three and more. If elements are less than three they already derivate one OSS, its parameters are defined trivially. For more quantities of elements we define an initial order, comparing the first two ones. Then consistently we compare the second and third, third and fourth elements and so on until their order coincides with the initial. As soon as the order has varied, at once we receive boundary next OSS, the data about which can be used into function Merge. For this purpose, the information about odd OSS we save in the set array of structures with an element 0 <= k < M, where M is dimension of a long-integer in operating system. For Win32 M is equal to 32.
Further, as function Split is used for us only once that we are not selecting it in separate function, and here function Merge we do.
The Description of Function Merge
Here, we use classical implementation of this function, i.e. as already it was mentioned above, from queues of the data we will consistently select (with removal from the queue) maximum or minimum value and to write it in the required sequence.
Function which control Split and Merge for us we name NaturalMergeSort.
The Description of Function NaturalMergeSort
This function consists of two main bodies. The first handles all even OSS, in process of their appearance, and the second all remained odd.
Let's show and tell in the following figures. The first part of algorithm deals with number OSS being a maximum degree of two not exceeding initial quantity of these OSS (fig. 2).

Fig. 2. A sorting example of «Natural Merge» for an invariable source at quantity OSS equal to a degree of two. The order of operations of splitting / merging is specified by red digits.
Let's consider further that multi-colored rectangles contain various arranged subsequences of the data. The second part of algorithm deals remained OSS after performance of the first part of algorithm (fig. 1). It is natural, if quantity OSS is equal to a degree of two the second part is not required. On fig. 3-7 the second part of algorithm is shown for various values of quantity OSS.
Fig. 3. A sorting example of «Natural Merge» for an invariable source at quantity OSS equal 3.
Fig. 4. A sorting example of «Natural Merge» for an invariable source at quantity OSS equal 5.
Fig. 5. A sorting example of «Natural Merge» for an invariable source at quantity OSS equal 6.
Fig. 6. A sorting example of «Natural Merge» for an invariable source at quantity OSS equal 7.
Fig. 7. A sorting example of «Natural Merge» for an invariable source at quantity OSS equal 99.
Now, when the idea of our algorithm is clear, it is possible to pass to its program implementation. As we write a working variant of the program, we will research the real data source. It is enough for our future purposes if it is a binary file in which there is a block of the string data (fig. 8).
Fig. 8. Structure of the block of the string data in the binary data source.
Similar structure has, for example, dbf files. Therefore, we give test file Sort.dbf. It contains some fields and 360 records. View of this file is shown in fig. 9.
Fig. 9. Contents of test file Sort.dbf.
Parameters of all data fields contain in structure g_DataBlock and are presented in the test program. Name field is current, the others are commented out. Certainly, nothing prevents us from calculating these parameters automatically, but it already does not concern the sorting purposes. However, this possibility is accessible in a program code of article: Creation and memory mapping existing DBF files as alternative of data serialization during work with modified CListCtrl classes in virtual mode on dialogs of MDI application.
As a result of execution of the program from some field of a test dbf file, appropriate records will be extracted and sorted in a temporary file. Besides data proper, the numbers of positions (strings or rows) of the given data field in a current data block will be still presented. These numbers of positions are counted from zero. As numbers of positions are stored as binary data besides a test procedure representing this data in ASCII format will be still started. Both spool files are formed with casual names in the current directory, which will be shown in the appropriate message (fig. 10). Generally, these time files can be to further removal, but we leave them for the demonstration purposes.
Fig. 10. Result of execution of the sort program.
For our convenience, we use technology Memory Mapped Files (MMF) into function SortFileDataBlock, i.e. files map into memory. Though in this case it is not essential and also can be easily removed, by insignificant complicating of a code. However owing to efficiency and convenience of MMF, we leave it for demonstration purposes.
Now it is possible to pass directly to code of the main function of sorting by natural merging with the non-decreasing and decreasing arranged subsequences.
Code of the Main Function NaturalMergeSort
BOOL NaturalMergeSort(NMS *pNms) {
TCHAR *szFileBuf1 = pNms->szFileBuf1; TCHAR *szFileBuf2 = pNms->szFileBuf2; HANDLE hSrcFile = pNms->hSrcFile; HANDLE hFileBuf1 = pNms->hFileBuf1; HANDLE hFileBuf2 = pNms->hFileBuf2; BYTE *pSrcFile = pNms->pSrcFile; BYTE *pFileBufView1 = pNms->pFileBufView1; BYTE *pFileBufView2 = pNms->pFileBufView2;
ULONG nHdrSize = g_DataBlock.nHdrSize; ULONG nRecSize = g_DataBlock.nRecSize; UINT nFldOff = g_DataBlock.nFldOff; UINT nFldLen = g_DataBlock.nFldLen; ULONG nRows = g_DataBlock.nRows;
HANDLE hOut = NULL; BYTE *pOut = NULL; OSS Oss = {0}; DWORD nRecNo = 0; DWORD dwBytes = 0; ULONG nLineInd = 0;
ULONG nRow = 0;
if(nRows > 2) {
int j = 0;
ULONG nNextRow = 0;
ULONG nOldNextRow = 0;
ULONG nInRow = 0;
ULONG nOldRow = 0;
ULONG nOldRows = 0;
int nOldSortSign = 0;
int nLastSortSign = 0;
ULONG nOutRow = 0;
ULONG nOldOutRow = 0;
ULONG nOSS = 0; ULONG nOSSBegin = 0; ULONG nOSSEnd = 0; ULONG nOSSRows = 0; int nSortSign1 = 0; int nSortSign2 = 0; CString *psFldVal1 = NULL;
CString *psFldVal2 = NULL;
BOOL bFirstRec = TRUE;
INROWS aInRows[32] = {0}; Oss.nFldLen = nFldLen;
for(nRow = 0; nRow <= nRows; nRow++) {
nLineInd = nRow*nRecSize + nFldOff;
try {
if(nRow < nRows) {
if(bFirstRec) {
psFldVal1 = new CString((LPCSTR) &pSrcFile[nLineInd],
nFldLen);
bFirstRec = FALSE;
continue;
} else {
psFldVal2 = new CString((LPCSTR) &pSrcFile[nLineInd],
nFldLen);
}
if(!Compare(psFldVal1, psFldVal2, &nSortSign2)) {
return FALSE;
}
} else
nOSS = nOSS;
if((nSortSign1 != 0 && nSortSign1 != nSortSign2)
|| nRow == nRows) {
nOSS++; nOSSEnd = nRow - 1; nOSSRows = nOSSEnd - nOSSBegin + 1;
nLastSortSign = nSortSign1;
nInRow = (nSortSign1 == 1) ? nOSSBegin : nOSSEnd;
if(nOSS%2) { aInRows[0].nInRow = nInRow;
aInRows[0].nInRows = nOSSRows;
nOldSortSign = nSortSign1;
} else { for(j = 0; j <= (int)(log(nOSS)/log(2)); j++) {
if(nOSS % (ULONG) pow(2, j+1) == 0) {
nOutRow = (nOSS == pow(2, j+1)) ? 0 : nOutRow;
if(j == 0) {
Oss.hIn1 = NULL;
Oss.pIn1 = pSrcFile;
Oss.nRecSize1 = nRecSize;
Oss.nRecSize2 = nRecSize;
Oss.nFldOff1 = nFldOff;
Oss.nFldOff2 = nFldOff;
} else {
Oss.hIn1 = (j%2 == 0) ? hFileBuf2 : hFileBuf1;
Oss.pIn1 = (j%2 == 0) ? pFileBufView2 : pFileBufView1;
Oss.nRecSize1 = nFldLen + sizeof(nRecNo);
Oss.nRecSize2 = Oss.nRecSize1;
Oss.nFldOff1 = 0;
Oss.nFldOff2 = 0;
}
Oss.hIn2 = Oss.hIn1;
Oss.pIn2 = Oss.pIn1;
Oss.hOut = (j%2 == 0) ? hFileBuf1 : hFileBuf2;
Oss.pOut = (j%2 == 0) ? pFileBufView1 : pFileBufView2;
nInRow = (j > 0) ? nOldRow : nInRow;
nSortSign1 = (j > 0) ? 1 : nSortSign1;
nOldSortSign = (j > 0) ? 1 : nOldSortSign;
nOutRow = (j > 0) ? nInRow : nOutRow;
nOldOutRow = nOutRow;
Oss.nInRow1 = aInRows[j].nInRow;
Oss.nInRow2 = nInRow;
Oss.nInRows1 = aInRows[j].nInRows;
Oss.nInRows2 = (j > 0) ? nOldRows : nOSSRows;
Oss.nInSS1 = nOldSortSign;
Oss.nInSS2 = nSortSign1;
Oss.nOutRow = nOutRow;
if(!Merge(&Oss)) { return FALSE;
}
nOutRow = Oss.nOutRow;
nOldRow = aInRows[j+1].nInRow;
nOldRows = aInRows[j+1].nInRows;
nOldSortSign = nSortSign1;
aInRows[j+1].nInRow = nOldOutRow;
aInRows[j+1].nInRows = Oss.nInRows1 + Oss.nInRows2;
nSortSign1 = 1;
}
}
}
nOSSBegin = nRow; nSortSign1 = 0;
} else
nSortSign1 = nSortSign2;
psFldVal1 = psFldVal2;
} catch(...) {
_M("CreateIndexFile : Error exception!");
exit(-1);
}
}
hOut = (nOSS == 1) ? NULL : (nOSS%2 == 0) ? hFileBuf1 : hFileBuf2;
pOut = (nOSS == 1) ? pSrcFile : (nOSS%2 == 0) ? pFileBufView1 :
pFileBufView2;
if(nOSS > pow(2, --j)) {
int n1 = 0;
int n2 = 0;
Oss.nInRow1 = 0;
Oss.nInRows1 = 0;
int i = 0;
nOldRow = 0;
nOldRows = 0;
ULONG nOSS1 = nOSS;
while(nOSS1 % 2 == 0) {
nOSS1 /= 2;
i++;
}
n1 = i;
ULONG nOSS0 = nOSS - (ULONG) pow(2, n1);
ULONG nOSS2 = 0;
while(nOSS > (ULONG) pow(2, n1)) {
i = 0;
nOSS2 = nOSS0;
while(nOSS2 % 2 == 0) {
nOSS2 /= 2;
i++;
}
n2 = i;
Oss.hIn1 = (n1 == 0) ? NULL : (n1%2 == 0) ? hFileBuf2 :
hFileBuf1;
Oss.pIn1 = (n1 == 0) ? pSrcFile : (n1%2 == 0) ? pFileBufView2 :
pFileBufView1;
Oss.hIn2 = (n2%2 == 0) ? hFileBuf2 : hFileBuf1;
Oss.pIn2 = (n2%2 == 0) ? pFileBufView2 : pFileBufView1;
Oss.hOut = (n2%2 == 0) ? hFileBuf1 : hFileBuf2;
Oss.pOut = (n2%2 == 0) ? pFileBufView1 : pFileBufView2;
ULONG nRecSize = nFldLen + sizeof(nRecNo);
Oss.nRecSize1 = (n1 == 0) ? g_DataBlock.nRecSize : nRecSize;
Oss.nRecSize2 = nRecSize;
Oss.nFldOff1 = (n1 == 0) ? nFldOff : 0;
Oss.nFldOff2 = 0;
if(Oss.pOut == Oss.pIn1) {
ULONG nOff = (n1 < n2) ? aInRows[n1].nInRow : nOldRow;
nOff *= nRecSize;
ULONG nSize = (n1 < n2) ? aInRows[n1].nInRows : nOldRows;
nSize *= nRecSize;
CopyMemory(
Oss.pIn2 + nOff, Oss.pIn1 + nOff, nSize );
Oss.hIn1 = Oss.hIn2;
Oss.pIn1 = Oss.pIn2;
}
Oss.nInRow1 = aInRows[n1].nInRow;
Oss.nInRow2 = (n1 < n2) ? aInRows[n2].nInRow : nOldRow;
Oss.nInRows1 = aInRows[n1].nInRows;
Oss.nInRows2 = (n1 < n2) ? aInRows[n2].nInRows : nOldRows;
Oss.nInSS1 = (n1 > 0) ? 1 : nLastSortSign;
Oss.nInSS2 = 1;
Oss.nOutRow = Oss.nInRow2;
if(!Merge(&Oss)) { return FALSE;
}
n1 = n2 + 1;
nOldRow = aInRows[n1].nInRow;
nOldRows = aInRows[n1].nInRows;
aInRows[n1].nInRow = Oss.nInRow2;
aInRows[n1].nInRows = Oss.nInRows1 + Oss.nInRows2;
nOSS0 = nOSS0 - (ULONG) pow(2, n2);
}
}
}
BYTE acCRLF[2] = {13, 10};
HANDLE hIn = Oss.hOut;
if(hIn) { HANDLE hOut = (hIn == hFileBuf1) ? hFileBuf2 : hFileBuf1;
if(SetFilePointer(hIn, 0, NULL, FILE_BEGIN) == (DWORD) -1) {
_M("CMainDoc:CreateIndexFile : Failed to call SetFilePointer
function!");
return FALSE;
}
if(SetFilePointer(hOut, 0, NULL, FILE_BEGIN) == (DWORD) -1) {
_M("CMainDoc:CreateIndexFile : Failed to call SetFilePointer
function!");
return FALSE;
}
for(ULONG i = 0; i < nRows; i++) {
BYTE *acStr = new BYTE[nFldLen]; char acNo[2*sizeof(ULONG)];
if(!ReadFile(hIn, acStr, nFldLen, &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call ReadFile function for
acStr!");
return FALSE;
}
if(!ReadFile(hIn, &nRecNo, sizeof(nRecNo), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call ReadFile function for
&nRecNo!");
return FALSE;
}
if(!WriteFile(hOut, acStr, nFldLen, &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acStr!");
return FALSE;
}
sprintf(acNo, "%8d", nRecNo);
if(!WriteFile(hOut, acNo, sizeof(acNo), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acNo! ");
return FALSE;
}
if(!WriteFile(hOut, acCRLF, sizeof(acCRLF), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acCRLF! ");
return FALSE;
}
}
} else { hOut = hFileBuf1; char acNo[2*sizeof(ULONG)];
for(nRow = 0; nRow < nRows; nRow++) {
nLineInd = nRow*nRecSize + nFldOff;
if(!WriteFile(hOut, &pSrcFile[nLineInd], nFldLen, &dwBytes,
NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
&pSrcFile[nLineInd]!");
return FALSE;
}
sprintf(acNo, "%8d", nRow);
if(!WriteFile(hOut, acNo, sizeof(acNo), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
nRow!");
return FALSE;
}
if(!WriteFile(hOut, acCRLF, sizeof(acCRLF), &dwBytes, NULL)) {
_M("NaturalMergeSort : Failed to call WriteFile function for
acCRLF!");
return FALSE;
}
}
}
sprintf(
g_szStr,
_T("NaturalMergeSort : See out files: `%s` and `%s`!"),
szFileBuf1,
szFileBuf2
);
_M(g_szStr);
return TRUE;
}
Let's notice that at attempt of sorting of the first data block (IndNo field) which is already sorted, our function NaturalMergeSort will define that in this case we have an unique OSS and it is not necessary to sort anything. For output of results, the source will be used directly, instead of a spool file.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 .
.