Introduction
There is none. I dare not give an “introduction” to Interop and risk exposing the extent of my ignorance.
Please Google for Interop and you will find a better explanation about it than what I can provide.
Background
As I was working in some of my recent projects, I had a need to work with C# and COM Interop extensively.
I had to pass on various varieties of information between the Managed & Unmanaged worlds and naturally,
I looked to Google so that I can reuse a.k.a. copy/paste the code from various sources.
To my discomfort, I found the code I wanted but not in a single location. It was spread all over the world and I
want to congregate all the information into a single webpage usable as a reference for any one.
The below is the first in a series of articles I intend to write regarding C#/ATL COM Interop. As I learn more and
more information, I will revise these articles. (At least, I hope to. But as God is my witness, I am a lazy slob!!!)
In the beginning, there was a bug…
When I started with my project work, my manager knew that I was faking my resume about
“extensive .Net experience”. So, he was kind enough to give me a little task which involved
debugging an existing Interop code rather than writing a new one.
The first problem I faced with it was how to debug the code??? The COM code was written in
one project and C# code was written in another. They had different .sln files and when I start
one of them in debugger, the breakpoints set in the other solution simply refused to hit!!! The
DLLs loaded properly and code flow was happening the way it is written. But how am I supposed
to debug the problem if the breakpoints are not hit!!!
One solution I tried was to run the C# solution file in debugger when needed to debug C# side
of the code and VC++ solution file when debugging the unmanaged code. This helped me only
for a little while. There was very soon a need to debug them together and the problem
resurfaced.
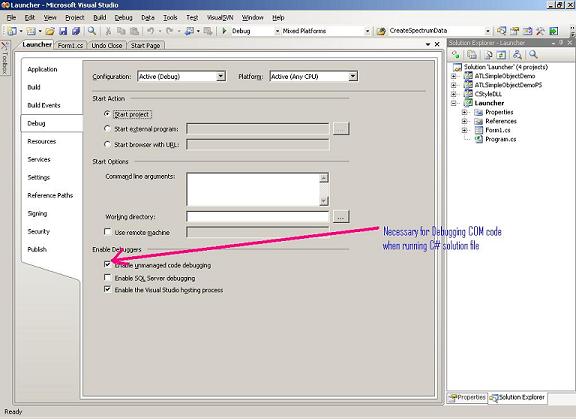
The solution is to set the Debugger Type in Visual Studio. In the project properties >
Debugging, there exists a small option called “Enable Unmanaged Debugging”. Check this box
and rerun the solution. Voilla!!! You can now debug the COM code from C# solution. See the
Image below for illustration.
If you are debugging from the Unmanaged VC++ solution, then you will have a different option
to set. See the image below to find it out.

These options carry drawbacks. Enabling "Unmanaged Debugging" in C# robs you of the
facility to Edit-and-Continue in C#. Luckily, you get a message whenever to attempt such a
thing. Check this out.
In VC++ the case is slightly different. Here, the default option is "Auto" which tells the
debugger to debug the environment in which the EXE file is built. If EXE file is built in
unmanaged environment, then you can walkthrough the COM code. If it is built in Managed
environment, then you can walk through C# code but not the COM code (even though you have
launched the debugger from that very project). Making it “Mixed” helps you to walk across
these worlds but you can edit and continue only COM code.
This done, I was able to walkthrough the Managed & Unmanaged worlds and fixed the bug. My
manager saw my work and was happy.
On the second day, my manager said….
“You are ready for the next task” he said. “You are going to learn more exciting things” he said. He left unsaid
that he is rewarding my work with more work. Phew…..Life. I geared up. This time, I am supposed to write a
function in the COM component and call it from C#. The fun began….
The process of sending data between the two worlds is called Marshalling & Unmarshalling. I want to marshal a
single dimensional array of real number.
Marshalling uni-dimensional real arrays (the bad way)
My IDL file declaration looks as shown below.
[id(1), helpstring("method NotGoodInterop")]
HRESULT NotGoodInterop([in]long nAraySize, [in]float *RealNumbersList);
And the prototype in the header file is
STDMETHOD(NotGoodInterop)(long nAraySize, float *RealNumbersList);
Now calling this function in C# as simple as
float[] Numbers = new float[_NumbersCount];
_SomeClassObject = new ATLSimpleObjectDemoLib.SomeClassClass();
_SomeClassObject.NotGoodInterop(2, ref Numbers[3]);
_SomeClassObject.NotGoodInterop(3, ref Numbers[25]);
It is as simple as that. We call the function and we are done. The data crosses the world like a Penguin
crossing the ocean.
The reason for calling this as NotGoodInterop is purely personal. I don’t like this way of specifying the
array size and array’s starting position. This can be very helpful but is confusing for me. So, when writing this
example I have named it so, but it might not be bad. I leave it for you to decide. I personally prefer the way
described below.
Marshalling uni-dimensional real arrays (the good way)
The IDL declaration is as below
[id(2), helpstring("method PutRealNumbers")]
HRESULT PutRealNumbers([in] long nAraySize, [in,size_is(nAraySize)]float RealNumbersList[]);
[id(3), helpstring("method GetRealNumbers")]
HRESULT GetRealNumbers([in] long nAraySize, [ref,size_is(nAraySize)]float RealNumbersList[]);
Note the use of size_is attribute in the IDL file. Please read more about it here and here.
The second one is from Adam Nathan and I am indebted to him for his excellent article. And prototype in
header file is as below:
STDMETHOD(PutRealNumbers)(long nArraySize,float RealNumbersList[]);
STDMETHOD(GetRealNumbers)(long nArraySize,float RealNumbersList[]);
Calling this from C# is the same as in the case of NotGoodInterop. Repeating it here
_SomeClassObject.PutRealNumbers(_NumbersCount - 3, ref Numbers[2]);
_SomeClassObject.GetRealNumbers(2, ref Numbers[4]);
My manager saw my work and was happy. He rewarded me with more work.
Marshalling Multi-dimensional real arrays
Now I have to Marshall a two dimensional array of real numbers. This gets tricky. Marshalling
multidimensional arrays is not the same as marshalling single dimensional arrays. This is because,
when we send the pointer to array, the unmanaged world has no clue what-so-ever about
the dimensions of the array. In C++ a multi-dimensional array is actually stored in a single memory
sequence. Compiler does a little magic and when we use arr[][] notation and passes on the
appropriate memory location. In order to have this done appropriately, compiler enforces the developer
to specify the array’s column size unambiguously. i.e. to say, in C++ you cannot declare something like:
float fltArr[][] = new float[10][20];
Don’t even think about sending the data as float ** and specifying the array sizes in
two explicit variables. If we have more than 3 arrays to Marshall in the same function, this
becomes very very cumbersome. If the arrays are all of different dimensions, then it is simply a
pain.
Kim Kartavyam??? (That is Sanskrit for ‘What is the solution’?) Use SAFEARRAYs
SafeArray is a very elegant way to Marshall data across functions written in various
programming languages. It binds very well with CLR and with a little pain at the language
boundaries, we can achieve a cool way of marshalling data. Please read more about SafeArray
here. Though for the rest of the discussion I will not assume you are familiar with SafeArray, I
will not discuss it exhaustively either.
Using SafeArrays, my IDL declaration becomes simple
[id(4), helpstring("method PutMultiDimensionalArray")]
HRESULT PutMultiDimensionalArray([in] SAFEARRAY(float) saNumbers);
[id(5), helpstring("method GetMultiDimensionalArray")]
HRESULT GetMultiDimensionalArray([out] SAFEARRAY(float) *saNumbers);
Please pay due attention to two facts here:
- The SAFEARRAY needs a Type to be specified. In this case float.
- IDL declaration for Put does not have a ‘*’ for SAFEARRAY but has one for Get.
After noting this, please observe the prototype necessary in the header file
STDMETHOD(PutMultiDimensionalArray)(SAFEARRAY* saNumbers);
STDMETHOD(GetMultiDimensionalArray)(SAFEARRAY **saNumbers);
Data Type is not specified here for SAFEARRAY. Also, Put has a ‘*’ and Get has ‘**’.
One more than the IDL file. Calling this from C# is deceivingly simple.
float[,] TwoDimNumbers = new float[2, 3];
_SomeClassObject.PutMultiDimensionalArray(TwoDimNumbers);
Array TwoDimNumbers1;
_SomeClassObject.GetMultiDimensionalArray(out TwoDimNumbers1);
The fun is in the C++ method. We have to reach into this SAFEARRAY variable to get the data
sent to us. Like I said, this can be a bit of a pain.
Accessing data in a SAFEARRAY can be done in three ways.
- Creating a C++ array from the SAFEARRAY.
- Accessing SAFEARRAY contents directly.
- Using CComSafeArray<> templates
In the first, we achieve speed. In the latter, we trade away some performance but can be sure
that we are not accessing illegal data. Third is the combination of bests from both.
Both methods have some common ground work to be done. I will cover this common area first
and then move on to the individual methods.
I will first verify the dimensions of the array. From C#, I have sent a two dim array. The below
code is in the C++ method.
nDimensions = SafeArrayGetDim(saNumbers);
nDimensions must be equal to 2.
SafeArrayGetVartype(saNumbers,&vt);
From C# I've sent a float array. vt must be equal to VT_R4
LowerBounds = new LONG[nDimensions];
UpperBounds = new LONG[nDimensions];
for(int inx=1;inx<=nDimensions;inx++) {
_com_util::CheckError(SafeArrayGetLBound(saNumbers, inx, &LowerBounds[inx-1]));
_com_util::CheckError(SafeArrayGetUBound(saNumbers, inx, &UpperBounds[inx-1]));
}
Now get the array boundaries
m_Dimension1Length = UpperBounds[0]-LowerBounds[0]+1;
m_Dimension2Length = UpperBounds[1]-LowerBounds[1]+1;
Method 1 for accessing Safe Array data: Using SafeArrayAccessData()
I create a C++ array and copy the data from SafeArray into this array. This saves me
performance especially if I have to repeatedly access array contents.
Please read this :
float *pfNumbers = NULL;
_com_util::CheckError(SafeArrayAccessData(saNumbers,(void HUGEP* FAR*)&pfNumbers));
float **CppArr = NULL;
CppArr = (float **)malloc(sizeof(float*)*m_Dimension1Length);
for(int inx=0; inx<m_Dimension1Length; inx++)
{
CppArr[inx] = new float[m_Dimension2Length];
for(int jnx=0; jnx<m_Dimension2Length; jnx++)
{
long SafeArrayIndex = jnx*m_Dimension1Length + inx;
long CppArrayIndex = inx*m_Dimension2Length + jnx;
float f;
f = pfNumbers[SafeArrayIndex];
CppArr[inx][jnx] = f;
m_vecFloatingNumbers.push_back(f);
}
}
_com_util::CheckError(SafeArrayUnaccessData(saNumbers));
Note: It is not necessary to create a copy of the Safe Array into C++ array.
do this only for demonstration purpose. If you want to access pfNumbers directly for downstream computing, it
is absolutely OK. Only, remember to calculate the array index appropriately. Else, you will end up
accessing wrong array location.
Method 2 for accessing Safe Array data: Using SafeArrayGetElement()
Here we will access the array elements via the safearray. We will not get our hands dirty with
the raw memory. This method is safe and gives proper error handling mechanism BUT consumes
time for locking and unlocking SafeArray when SafeArrayGetElement() is invoked. This can be a
performance hit.
for(int inx=0; inx<m_Dimension1Length; inx++)
{
for(int jnx=0; jnx<m_Dimension2Length; jnx++)
{
long ArrayIndex[2] = {LowerBounds[0]+inx,LowerBounds[1]+jnx};
float f;
_com_util::CheckError(SafeArrayGetElement(saNumbers,ArrayIndex,(void*)&f));
}
}
This is for Put()ting the data. Getting the data is a corollary to this. Please see the sample
project I have attached to this article. It gives you the complete documented code.
Very Important Note: Why do we need to bother with array index calculation when accessing
data? Because SAFEARRAYs are designed to marshall data to and from all languages. And some
languages have arrays as Row-Major and others have them as Column-Major.
SafeArray has a standard way of accessing them which is Column-Major. Unfortunately, the
method in which SafeArray stores arrays is not same as the C++ Row-Major order. So, we have
to worry about array index calculation.
Method 3 for accessing Safe Array data: Using CComSafeArray<>
I will cover this in more detail when marshalling strings. The only reason for dealing this
separately is, I learnt using this class when marshalling strings and it became a habit for me to
use it whenever dealing with strings. So, my sample code was written so and hence I am
explaining it there.
Marshalling array of strings
I was told to send an array of User IDs collected from a C# UI form to a database access
component written in COM. This is almost exactly the same as marshalling arrays of floating
point numbers. The only difference is the IDL file prototype contains a BSTR as SAFEARRAY’s
data type.
The IDL declaration will be
[id(6), helpstring("method PutStrings")]
HRESULT PutStrings([in] SAFEARRAY(BSTR) Strings);
[id(7), helpstring("method GetStrings")]
HRESULT GetStrings([out] SAFEARRAY(BSTR) *Strings);
And the prototype in header file is
STDMETHOD(PutStrings)(SAFEARRAY * Strings);
STDMETHOD(GetStrings)(SAFEARRAY **Strings);
Please compare this with marshalling multi-dimensional arrays part of the code and you will see
the similarities and differences.
Calling from C# is also the same way:
string[] Strings = new string[5];
_SomeClassObject.PutStrings(Strings);
And then we are done. On the C++ side, the processing is same as in Marshalling
Multi-dimensional real arrays except that we deal with strings. I will not discuss
them here again. You can try them by your own. The sample project I have attached
contains these methods and you can try them to your heart’s content.
Method 3 for accessing Safe Array data: Using CComSafeArray<>
std::vector<BSTR> vecStrings2;
CComSafeArray<BSTR> saBSTRs;
saBSTRs.CopyFrom(Strings);
vecStrings2.clear();
for (long inx=0; inx<cElements; inx++)
{
vecStrings2.push_back(saBSTRs[inx]);
}
As simple as that!!! This gives the simplicity and elegance of array style data
access and avoids all the hassles of lower bounds and upper bounds. I am
not sure of the performance impact but, personally, I don’t care in this case.
The simplicity of code means a lot more to me and I am sure MS has incorporated
all the necessary performance tweaks. A lot of SAFEARRAY related coding can be
avoided by using CComSafeArray wrappers. Method 1 & 2 are necessary if we are
using SAFEARRAY in C style code.
Marshalling Structures and Enums
Even though I’ve put the heading as marshalling structures & Enums, I am going to
discuss very little about it. I will explain the general case first and then list the
points which I have left uncovered and the reasons for doing so.
I need to Marshall a data structure and Enum values. These, I will declare in my IDL file as
below
typedef enum MyEnum
{
Good,
Bad,
Ugly
} MyEnum;
typedef struct SData
{
int Id;
BSTR Name;
MyEnum eEnumVal;
} Data;
I also declare a function which accepts these an input.
[id(8), helpstring("method SampleEnumAndStruct")]
HRESULT SampleEnumAndStruct([in] MyEnum enumVal,[in]Data data);
The prototype in Header file becomes
STDMETHOD(SampleEnumAndStruct)(MyEnum enumVal,Data data);
This is the standard declaration method in any IDL file. Now calling this from C# is a breeze. In
fact, it does not feel any different at all.
ATLSimpleObjectDemoLib.SData data = new ATLSimpleObjectDemoLib.SData();
data.eEnumVal = ATLSimpleObjectDemoLib.MyEnum.Bad;
data.Id = 0;
data.Name = "Lee Van Cleef";
_SomeClassObject.SampleEnumAndStruct(ATLSimpleObjectDemoLib.MyEnum.Bad, data);
The implementation part in C++ is
STDMETHODIMP CSomeClass::SampleEnumAndStruct(MyEnum enumVal,Data data)
{
if(enumVal == Bad)
{
MessageBox(NULL,L"The Baddies was Lee Van Cleef",
L"Did you know that?",MB_OK|MB_ICONQUESTION);
}
return S_OK;
}
Quite simple and straight forward. Isn't it???
To Dos:
- When marshalling a structure, we can specify how the marshalling of individual members
can be done. We can use attributes like MarshalAs, MarshalAsAttribute etc. I have
never used this and I don’t know how to. If any one can please add it here, I would
be very thankful. - In some websites, there is mention of editing the tlbimp file generated from the COM
component. I don’t know how this can be done. I also wonder how helpful this method
will be especially in case of large projects where nightly builds keep rebuilding the COM
component and regenerating the tlbimp file. But these might be the questions of an
ignorant simpleton. So, please do not take them seriously. As I get my hands-on on
these, I will add them here.
Marshalling data across C-Style functions
You might ask, what else is left. If Method 1 and Method 2 are for C-Style access of
SAFEARRAY, what are we left with? Very little, actually. I will quickly run through
them here as this is the appropriate place to do so.
Consider a sample function which puts a uni-dimensional array of integers.
extern "C" void SamplePutFunction(int nArraySize,int * Arrays);
For calling this in C#, we first of all need to tell the compiler where it can find
the DLL at runtime and also how the function is declared in C. We do that
using the DllImport attribute in the C# file.
[DllImport("CStyleDLL.dll")]
public static unsafe extern void
SamplePutFunction(int nArraySize, int* InputArray);
And now we can call this function from wherever required. Please note that C#
compiler will not check for the validity of function prototype you have written
in C# file with DLL. If there is a mismatch, then you will get an exception or
worse. If you are importing more than one function from the same DLL, please
remember that you have to write a DllImport for each function. Missing it for
one function shall not give a compiler error. You will only get an exception at
runtime.
Marshalling pointers
[DllImport("CStyleDLL.dll")]
public static unsafe extern void
SamplePutFunction(int nArraySize, int* InputArray);
private void btnPutCStyleArray_Click(object sender, EventArgs e)
{
int[] IntArray = new int[100];
unsafe
{
fixed (int* pArray = IntArray)
{
SamplePutFunction(IntArray.Length, pArray);
}
}
}
That is how the cookie crumbles. Please pay close attention to the unsafe and fixed
keywords in this snippet. They can wreak havoc in coding and I have spent sleepless nights chasing
after the elusive bug.
Even though this seems unnecessary from the code above, unsafe and
fixed code is especially helpful when we need to marshal pointer to a
structure to the C function. Using fixed is always advisable because
it saves you from pointers being relocated during Garbage Collection.
If you don’t fixed your pointer variable, you will run a potential risk
of page faults and access violations - The perfect entry point for hackers.
In VS 2008, using unsafe keyword in the code requires a compiler option to
be set explicitly in UI. Please see below image
The unmentioned piece of code
What I have not mentioned here is – For all the COM components to be called from C#,
we need an AxInterop and Interop DLLs. I believe these DLLs take the responsibility
of doing the necessary operation for converting the C# arrays into SAFEARRAYS and
then pass them to the COM functions. These DLLs are auto-generated when we add
the COM component in the project references. Please see the below screen shots for
how to add a COM component as reference.
From the C# project’s References option choose “Add Reference”.
Choose the tab COM. Select the required COM component and click on OK.
These steps create the AxInterop and Interop DLLs and put them in the appropriate
folders. But it is often required (in large software projects) that these DLLs are to
be placed in locations elsewhere than the default locations and signed approprately.
For achieving this, please use the TlbImp.exe and axImp.exe utilities. Please see a
sample use of these utilities here. Read more about them here and here.
TlbImp /silent /nologo /sysarray /publickey:"PublicKey.snk"
/delaysign /out:"Interop.ComComponent.dll"
/namespace:ComInteropDemo "InteropDemo.dll"
"/asmversion:1.0.0.0"
aximp /silent " InteropDemo.dll"
/out:"AxInterop.InteropDemo.dll"
/rcw:"InteropDemo.dll"
/publickey:"PublicKey.snk"
/delaysign /silent /nologo
For the examples we have been discussing here, we don’t need aximp. If we are creating an
ActiveX component, then aximp is necessary. The snippets we have seen above are not ActiveX components.
So, we don’t need it. I will try to deal with it in Part2 of this series.
Epilogue
My manager was very happy. And what did he do? Please read next article to find out what he
did :-)


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






