Introduction
When you update JavaScript or CSS files that are already cached in users' browsers, most likely many users won’t get that for some time because of the caching at the browser or intermediate proxy(s). You need some way to force browser and proxy(s) to download the latest files. There’s no way to do that effectively across all browsers and proxies from the webserver by manipulating cache headers unless you change the file name or you change the URL of the files by introducing some unique query string so that browsers/proxies interpret them as new files. Most web developers use the query string approach and use a version suffix to send the new file to the browser. For example:
<script src="someJs.js?v=1001" ></script>
<link href="someCss.css?v=2001"></link>
In order to do this, developers have to go to all the html, aspx, ascx, master pages, find all references to static files that are changed, and then increase the version number. If you forget to do this on some page, that page may break because browser uses old cached script. So, it requires a lot of regression test effort to find out whether changing some CSS or js breaks something anywhere in the entire website.
Another approach is to run some build script that scans all files and updates the reference to the JavaScript and CSS files in each and every page in the website. But this approach does not work on dynamic pages where the JavaScript and CSS references are added at run-time, say using ScriptManager.
If you have no way to know what JavaScript and CSS will get added to the page at run-time, the only option is to analyze the page output at runtime and then change the JavaScript, CSS references on the fly.
Here’s an HttpFilter that can do that for you. This filter intercepts any ASPX hit and then it automatically appends the last modification date time of JavaScript and CSS files inside the emitted HTML. It does so without storing the whole generated HTML in memory nor doing any string operation because that will cause high memory and CPU consumption on webserver under high load. The code works with character buffers and response streams directly so that it’s as fast as possible. I have done enough load test to ensure even if you hit an aspx page million times per hour, it won’t add more than 50ms delay over each page response time.
First, you add set the filter called StaticContentFilter in the Global.asax file’s Application_BeginRequest event handler:
Response.Filter = new Dropthings.Web.Util.StaticContentFilter(
Response,
relativePath =>
{
if (Context.Cache[physicalPath] == null)
{
var physicalPath = Server.MapPath(relativePath);
var version = "?v=" +
new System.IO.FileInfo(physicalPath).LastWriteTime
.ToString("yyyyMMddhhmmss");
Context.Cache.Add(physicalPath, version, null,
DateTime.Now.AddMinutes(1), TimeSpan.Zero,
CacheItemPriority.Normal, null);
Context.Cache[physicalPath] = version;
return version;
}
else
{
return Context.Cache[physicalPath] as string;
}
},
"http://images.mydomain.com/",
"http://scripts.mydomain.com/",
"http://styles.mydomain.com/",
baseUrl,
applicationPath,
folderPath);
}
The only tricky part here is the delegate that is fired whenever the filter detects a script or CSS link and it asks you to return the version for the file. Whatever you return gets appended right after the original URL of the script or css. So, here the delegate is producing the version as “?v=yyyyMMddhhmmss” using the file’s last modified date time. It’s also caching the version for the file to make sure it does not make a File I/O request on each and every page view in order to get the file’s last modified date time.
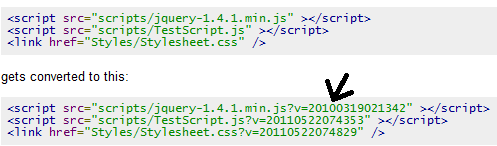
For example, the following scripts and CSS in the HTML snippet:
<script type="text/javascript" src="scripts/jquery-1.4.1.min.js" ></script>
<script type="text/javascript" src="scripts/TestScript.js" ></script>
<link href="Styles/Stylesheet.css" rel="stylesheet" type="text/css" />
It will get emitted as:
<script type="text/javascript" src="scripts/jquery-1.4.1.min.js?v=20100319021342" ></script>
<script type="text/javascript" src="scripts/TestScript.js?v=20110522074353" ></script>
<link href="Styles/Stylesheet.css?v=20110522074829" rel="stylesheet" type="text/css" />
As you see, there’s a query string generated with each of the file’s last modified date time. Good thing is you don’t have to worry about generating a sequential version number after changing a file. It will take the last modified date, which will change only when a file is changed.
The HttpFilter I will show you here cannot only append version suffix, it can also prepend anything you want to add on image, CSS and link URLs. You can use this feature to load images from a different domain, or load scripts from a different domain and benefit from the parallel loading feature of browsers and increase the page load performance. For example, the following tags can have any URL prepended to them:
<script src="some.js" ></script>
<link href="some.css" />
<img src="some.png" />
They can be emitted as:
<script src="http://javascripts.mydomain.com/some.js" ></script>
<link href="http://styles.mydomain.com/some.css" />
<img src="http://images.mydomain.com/some.png" />
Loading JavaScripts, CSS and images from different domains can significantly improve your page load time since browsers can load only two files from a domain at a time. If you load JavaScripts, CSS and images from different subdomains and the page itself on www subdomain, you can load 8 files in parallel instead of only 2 files in parallel.
How Do They Do It?
The hardest part of the work in the filter is to intercept writes to the Response stream in chunks of bytes and process those bytes to make sense of them without constructing strings. You have to read one character at a time and understand whether a sequence of characters means a <script> tag or not and then find the src attribute of the tag and then extract the value between double quotes. You have to do all of these without using your favorite string manipulation functions like indexOf, substring, etc.
First, the filter overrides the Write method of Stream.
public override void Write(byte[] buffer, int offset, int count)
{
char[] content;
char[] charBuffer = this._Encoding.GetChars(buffer, offset, count);
if (null != this._PendingBuffer)
{
content = new char[charBuffer.Length + this._PendingBuffer.Length];
Array.Copy(this._PendingBuffer, 0, content, 0, this._PendingBuffer.Length);
Array.Copy(charBuffer, 0, content, this._PendingBuffer.Length, charBuffer.Length);
this._PendingBuffer = null;
}
else
{
content = charBuffer;
}
Up to this point, nothing interesting happening but to make sure we always have a complete buffer that has a complete HTML tag. For example, if the last Write call ended with an incomplete buffer that ended half way through a tag like “<script sr”, we want to wait for the next Write call and get more data so that we get a complete tag to process.
The following loop does the real work:
int lastPosWritten = 0;
for (int pos = 0; pos < content.Length; pos++)
{
char c = content[pos];
if ('<' == c)
{
pos++;
if (HasTagEnd(content, pos))
{
if ('/' == content[pos])
{
}
else
{
if (HasMatch(content, pos, IMG_TAG))
{
lastPosWritten = this.WritePrefixIf(SRC_ATTRIBUTE,
content, pos, lastPosWritten, this._ImagePrefix);
}
else if (HasMatch(content, pos, SCRIPT_TAG))
{
lastPosWritten = this.WritePrefixIf(SRC_ATTRIBUTE,
content, pos, lastPosWritten, this._JavascriptPrefix);
lastPosWritten = this.WritePathWithVersion(content, lastPosWritten);
}
else if (HasMatch(content, pos, LINK_TAG))
{
lastPosWritten = this.WritePrefixIf(HREF_ATTRIBUTE,
content, pos, lastPosWritten, this._CssPrefix);
lastPosWritten = this.WritePathWithVersion(content, lastPosWritten);
}
if (lastPosWritten > pos)
pos = lastPosWritten;
}
}
else
{
this._PendingBuffer = new char[content.Length - pos];
Array.Copy(content, pos, this._PendingBuffer, 0, content.Length - pos);
this.WriteOutput(content, lastPosWritten, pos - lastPosWritten);
return;
}
}
}
The logic is, loop through each character in the character buffer and look for a tag start ‘<’. Then found, look if the buffer has a tag end ‘>’. If not, wait for the next Write call to get a complete buffer. If we have a complete tag, then match the tag name and see if it’s either IMG, SCRIPT or LINK.
It matches the buffer for a tag name using pure character matching, no string operation at all, thus no overhead on garbage collector.
private bool HasMatch(char[] content, int pos, char[] match)
{
for (int i = 0; i < match.Length; i++)
if (content[pos + i] != match[i]
&& content[pos + i] != char.ToUpper(match[i]))
return false;
return true;
}
As you see, there’s no string allocation and thus no new variable is introduced. It does pure character matching.
As soon as it finds the right tag it is looking for, it finds the URL of the file from href or src attribute. Then it checks whether the URL is absolute or relative. If relative, then it prepends the prefix.
private int WritePrefixIf(char[] attributeName, char[] content,
int pos, int lastWritePos, byte[] prefix)
{
int attributeValuePos = this.FindAttributeValuePos(attributeName, content, pos);
if (attributeValuePos > 0)
{
if (HasMatch(content, attributeValuePos, HTTP_PREFIX))
{
return lastWritePos;
}
else
{
this.WriteOutput(content, lastWritePos, attributeValuePos - lastWritePos);
if (prefix.Length > 0)
this.WriteBytes(prefix, 0, prefix.Length);
else
{
}
if (HasMatch(content, attributeValuePos, _ApplicationPath))
{
attributeValuePos = attributeValuePos + _ApplicationPath.Length;
}
else
{
if (this._CurrentFolder.Length > 0)
this.WriteBytes(this._CurrentFolder, 0, this._CurrentFolder.Length);
}
if ('/' == content[attributeValuePos]) attributeValuePos++;
return attributeValuePos;
}
}
else
{
return lastWritePos;
}
}
The code is heavily documented, so I am not going to repeat what it does.
Similarly, the version is appended by looking at the URL and appending the version on it.
private int WritePathWithVersion(char[] content, int lastPosWritten)
{
if (!HasMatch(content, lastPosWritten, HTTP_PREFIX))
{
int pos = lastPosWritten + 1;
while ('"' != content[pos]) pos++;
var relativePath = new string(content, lastPosWritten, pos - lastPosWritten);
this.WriteOutput(content, lastPosWritten, pos - lastPosWritten);
lastPosWritten = pos;
var version = this._getVersionOfFile(relativePath).ToCharArray();
this.WriteOutput(version, 0, version.Length);
}
return lastPosWritten;
}
It first extracts the path, makes sure it is relative, and then it fires the callback to get the version of the file. Whatever the callback returns, it appends it to the relative path.
How Fast Is It?
It’s pretty fast. I did some Visual Studio performance profiling. VS says the whole code in the filter is faster than .NET Framework code like getting items from cache or calling Server.MapPath() or getting the file’s last modified date time.
If you look at the breakdown of the time spent on the Write function, majority of the time spent is in getting the version number added:

All the for loops, if conditions, etc. are negligible compared to the call to WritePathWithVersion which fires the callback to get the version for each file.
Inside the WritePathWithVersion, you see all the time is spent on calling the callback to get the version number.
LastWriteTime of the file. it proves that all the code written in the filter is faster than reading an item from cache or getting the last modification date of a file.
When I do load testing by producing 20 concurrent users each making 30 consecutive calls, then the CPU consumption without the filter shows:
This is without the filter. You can see there’s nothing but ASP.NET stuff doing their work. CPU consumption is avg between 40% to 60%.
Now when I turn on the filter, the CPU consumption looks like:
The CPU consumption is still between 40% to 60%. So, there’s no visible impact on CPU when the filter is added. I have made sure the filter does enough work by producing a page output around 200 KB. This ensures there were many calls to Write and the filter code did a lot of work.
I am Convinced, How Do I Use It?
Go to http://code.google.com/p/autojscssversion/ and download the sample project. In App_Code, you will find the filter. All you need to do is to register the filter in Application_BeginRequest in Global.asax as shown in the example. That’s it!
Conclusion
You need to cache JavaScripts, CSS, images on the browser and proxies to provide as fast browsing experience as possible. But that means you can't update the static files and deliver them to all the browsers unless you change the URL of the file. Manually updating file references throughout the website is difficult and error prone. This HttpFilter does it automatically for you.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 :
: