Overview
This article is the first of a planned series intended to show that, despite the common (mis)belief among developers on the Windows platform, especially those less or not at all familiar with the language, programming in C++ is not harder or less fun than programming in other languages, such as Java, C#, VB.NET, Ruby, Python, etc. This series is mostly intended (but not exclusively) for developers not very familiar with C++, though perhaps experienced with other programming languages.
In this article, I will show how one can solve a (rather) mathematical problem with little effort in C++. Though there could be multiple approaches, more or less optimal, in this example, I will not focus on getting the best performance out of an algorithm. Many say C++ should be used only when performance is a must and one must get the best of memory use or clock cycles. While it is true that C++ tops at that, we must not forget that C++ is a general programming language that can be used for many purposes. My intentions for this article is to show how one can easily make use of containers, algorithms, random number generators, tasks, clocks and others in delivering a simple solution to the proposed problem.
I will be using Visual Studio 2012 for writing the program. I will assume you know how to create a C++ console application and write a main() function (the entry point of a C++ program) so that you can follow and be able to compile and run the code.
The Problem
The problem I'm going to solve was proposed by Ross Eckler in his book Making the Alphabet Dance: Recreational Wordplay. It is called Optimal alphabetical order and is described in more details here.
Assume we have a list of all the words in the English language. Under the normal ordering of the alphabet in English (A, B, C, ..., Z), some number of these words have all their letters in alphabetical order (for example, DEEP, FLUX, and CHIMPS). However, if we change the ordering of the alphabet, we will change the number of words having their letters in "alphabetical" order. What arrangement of the letters of the alphabet maximizes this number? What arrangement minimizes it?
A list containing 67230 words to test the solution is available here. 860 words from this list have their letters in alphabetical order using the Latin alphabet.
The Solution
The first thing to consider is how we shall represent the alphabet. There could be multiple choices (with advantages and disadvantages). It could be an array or a vector of 26 characters, or even a string. For simplicity in determining whether a letter comes before another in a particular alphabet, I will use a map that associates each letter with its index in the alphabet. The Latin alphabet would then look like this:
'A' => 0
'B' => 1
...
'Z' => 25
To use a map, we must include the <map> header. In order to avoid verbosely writing std::map<char, int> in many places, I will define a type called alphabet_t.
#include <map>
typedef std::map<char, int> alphabet_t;
The following method called base_alphabet() creates an instance of this type and initializes it with the values corresponding to the Latin alphabet.
alphabet_t base_alphabet()
{
alphabet_t alpha;
for(int i = 0; i < 26; ++i)
alpha.insert(std::make_pair(static_cast<char>('A' + i), i));
return alpha;
}
Notice that all the containers, algorithms and types used throughout this article are available in the Standard Template Library (aka STL, the library defined by the C++ standard that all compilers make available) in the namespace std. We could import all the symbols from this namespace into the global namespace with a using namespace std; directive. However, for clarity, I will not use it and prefer to fully qualify all the types and functions with the std:: namespace qualifier.
Just for fun and the sake of testing, the following function produces an alphabet that is the reversed Latin alphabet (Z is the first letter and A is the last).
alphabet_t reversed_alphabet()
{
alphabet_t alpha;
for(int i = 25; i >=0; i--)
alpha.insert(std::make_pair(static_cast<char>('Z' - i), i));
return alpha;
}
A first handy function would be one that transforms (or folds) this map into a string (that can be compared with other strings or printed to the console). Such a method shall take an alphabet_t object and return a std::string. I'll go ahead and write a test for this function.
#include <assert.h>
void test_alphabet_string()
{
auto alpha1 = base_alphabet();
auto alphastr1 = alphabet_string(alpha1);
assert(alphastr1 == "ABCDEFGHIJKLMNOPQRSTUVWXYZ");
auto alpha2 = reversed_alphabet();
auto alphastr2 = alphabet_string(alpha2);
assert(alphastr2 == "ZYXWVUTSRQPONMLKJIHGFEDCBA");
}
Notice the auto keyword that is a placeholder for a type and tells the compiler to infer the type from the expression on the right side of the assignment operation.
This transforming function will have to put into a string the letters in the increasing order of their index. To simplify this, I will use a second map that associates each index in the alphabet with a letter. For the Latin alphabet, that means:
0 => 'A'
1 => 'B'
...
25 => 'Z'
I will define a second type in the same way I have defined alphabet_t.
typedef std::map<int, char> inversed_alphabet_t;
A function called inverse_alphabet_map takes an alphabet_t and returns an inversed_alphabet_t. It iterates through all the elements of the alphabet_t object and inserts each key-value pair into the second map as value-key pair.
inversed_alphabet_t inverse_alphabet_map(alphabet_t const & alphabet)
{
inversed_alphabet_t inversedalpha;
for(auto const & elem : alphabet)
inversedalpha.insert(std::make_pair(elem.second, elem.first));
return inversedalpha;
}
Going back to the alphabet_string function, it takes an alphabet_t object, produces a new map with the inversed keys and values and then uses std::transform to produce the string. std::transform is a general purpose algorithm available in header <algorithm> that applies an operation to a range and stores the result in another range (possible the same range). The (unary) operation I supply to the algorithm is a lambda function that takes a std::pair<int, char> (the value type of inversed_alphabet_t) and returns a character.
#include <string>
#include <algorithm>
std::string alphabet_string(alphabet_t const & alphabet)
{
std::string alphabet_string(alphabet.size(), ' '); auto reversed = inverse_alphabet_map(alphabet);
std::transform(
begin(reversed), end(reversed), begin(alphabet_string), [](std::pair<int, char> const & elem){return elem.second;} );
return alphabet_string;
}
Notice the alphabet is passed as a constant reference to the function. Passing by reference, as opposed to passing by value, prevents making a copy of the object. Marking the argument const prevents us from modifying the object inside the function (any such attempt is flagged by the compiler as an error). All arguments that should not be modified inside a function should be passed as constant.
Calling the test_alphabet_string function from main should not trigger an assertion.
int main()
{
test_alphabet_string();
return 0;
};
If we made an error somewhere, either in the functions or the test, we'd get an assert. Here is an example: the expected string for the base (Latin) alphabet is "BAC...Z" instead of "ABC...Z". In this case, an assertion is triggered.
auto alpha1 = base_alphabet();
auto alphastr1 = alphabet_string(alpha1);
assert(alphastr1 == "BACDEFGHIJKLMNOPQRSTUVWXYZ");
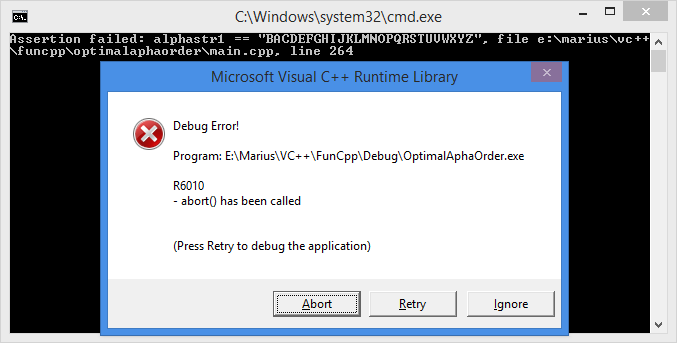
You can attach the native Visual Studio debugger to the process and then press Retry. Browsing through the call stack, you can reach the line in the code where the assertion occurred.

The next functions I will write is one that swaps two letters in the alphabet. So if we have the alphabet "ABC...Z" and swap 'A' with 'B' we get the alphabet "BAC...Z". A test for this function could look like this (testing the margins at both ends and middle letters).
void test_swap_letter()
{
auto alpha1 = base_alphabet();
swap_letter(alpha1, 'A', 'B');
auto alphastr1 = alphabet_string(alpha1);
assert(alphastr1 == "BACDEFGHIJKLMNOPQRSTUVWXYZ");
auto alpha2 = base_alphabet();
swap_letter(alpha2, 'Y', 'Z');
auto alphastr2 = alphabet_string(alpha2);
assert(alphastr2 == "ABCDEFGHIJKLMNOPQRSTUVWXZY");
auto alpha3 = base_alphabet();
swap_letter(alpha3, 'A', 'Z');
auto alphastr3 = alphabet_string(alpha3);
assert(alphastr3 == "ZBCDEFGHIJKLMNOPQRSTUVWXYA");
auto alpha4 = base_alphabet();
swap_letter(alpha4, 'I', 'O');
auto alphastr4 = alphabet_string(alpha4);
assert(alphastr4 == "ABCDEFGHOJKLMNIPQRSTUVWXYZ");
}
The swap_letter function is pretty simple. It uses the std::swap algorithm from the <algorithm> header to swap the values corresponding to the supplied keys in the map.
void swap_letter(alphabet_t & alphabet, char const l1, char const l2)
{
std::swap(alphabet[l1], alphabet[l2]);
}
A key aspect of the implementation is finding if a word is ordered, given a particular alphabet mapping. The is_ordered function takes a string representing a word and an alphabet_t and returns a bool. I will first write a simple test for this function:
void test_is_ordered()
{
auto alpha1 = base_alphabet();
assert(true == is_ordered("ABCD", alpha1));
assert(true == is_ordered("AABCDXYZ", alpha1));
assert(false == is_ordered("AACB", alpha1));
swap_letter(alpha1, 'A', 'B');
assert(false == is_ordered("ABCD", alpha1));
assert(false == is_ordered("AABCDXYZ", alpha1));
assert(true == is_ordered("BAC", alpha1));
assert(true == is_ordered("BBAAC", alpha1));
assert(false == is_ordered("BCA", alpha1));
}
bool is_ordered(std::string const & word, alphabet_t const & alphabet)
{
if(word.size() < 2) return true;
for(size_t i = 1; i < word.size(); ++i)
{
auto lpos1 = alphabet.find(word[i]);
auto lpos2 = alphabet.find(word[i-1]);
if(lpos1->second < lpos2->second)
return false;
}
return true;
}
The next step is determining the score of a list of words for a particular alphabet. Function alphabet_score takes a vector of strings representing the words and an alphabet_t and returns the count of words that are ordered in the given alphabet. A simple test function may look like this:
void test_alphabet_score()
{
std::string arrwords[] = {"THIS", "IS", "A",
"SIMPLE", "ALPHABET", "SCORE", "TEST"};
std::vector<std::string> words(begin(arrwords), end(arrwords));
assert(2 == alphabet_score(words, base_alphabet()));
}
The alphabet_score uses the std::count_if algorithm from header <algorithm> to count the elements of a range that match a criteria. The supplied predicate is a lambda function that takes a string representing the word and calls is_ordered to check the ordering of the word within the given alphabet.
#include <string>
int alphabet_score(std::vector<std::string> const & words, alphabet_t const & alphabet)
{
return std::count_if(
begin(words), end(words),
[&alphabet](std::string const & word) {return is_ordered(word, alphabet);});
}
In the beginning of the article, I mentioned a compiled list of 67230 words that contains 860 ordered words in the Latin alphabet. We can extend the testing of the alphabet_score with an additional test:
assert(860 == alphabet_score(read_words(), base_alphabet()));
Function read_words uses a std::ifstream file stream from header <fstream> to read the file and stores the read words into a vector of strings.
std::vector<std::string> read_words()
{
std::ifstream file("words.txt");
std::istream_iterator<std::string> start(file), end;
std::vector<std::string> words(start, end);
return words;
}
At this point, we have everything in place for testing the score of a list of words for a given alphabet. The next part is finding an optimal alphabet that has the highest score. To do that, we'll use a hill-climbing algorithm: we start with an alphabet (can be the Latin or a random alphabet) and compute the score. We then alter the alphabet by swapping two random keys. If the score with the new alphabet is bigger, we store the score as the best so far. Every 1000 iterations, we alter the alphabet twice, and every 5000 iterations, we alter the alphabet three times. To potentially boost the finding of a new local maximum every 50000 iterations, we shuffle the whole alphabet. The algorithm could run either for a given number of iterations or for a given time interval.
What we are missing from this description are functions for altering the alphabet by swapping two random letters and for completely shuffling the alphabet (that doesn't mean some letters cannot maintain their position in the new alphabet mapping).
To be able to pick random letters, we will use facilities available in the <random> header. STL supports generating (pseudo-)random numbers with generators (that produce uniformly distributed numbers) and distributions (that transforms the sequences of numbers produced by a generator into sequences that follows specific distributions). From this header, we will use the mt19937 Marsenne Twister generator and the uniform_int_distribution for generating random numbers uniformly in the range [0, 25].
The first function, alter_alphabet takes an alphabet_t, a mt19937 generator and a uniform_int_distribution. It picks two different letters in the range 'A' ... 'Z' and swaps their position in the alphabet.
#include <random>
void alter_alphabet(alphabet_t & alphabet, std::mt19937 & generator,
std::uniform_int_distribution<int> & uniform_distribution)
{
auto l1 = 'A' + uniform_distribution(generator);
auto l2 = 0;
do {
l2 = 'A' + uniform_distribution(generator);
} while(l2 == l1);
swap_letter(alphabet, l1, l2);
}
The second function, shuffle_alphabet, takes an alphabet and randomly shuffles its letters by using the std::random_shuffle algorithm from header <algorithm>. This algorithm does not work with maps, so the first thing is to copy the values of the alphabet_t (the indexes of the letters in the alphabet) into a vector. This vector is then shuffled and its values and then copied back to the map.
void shuffle_alphabet(alphabet_t & alphabet)
{
std::vector<alphabet_t::mapped_type< values(alphabet.size());
std::transform(
begin(alphabet), end(alphabet),
begin(values),
[](alphabet_t::value_type const & elem) {return elem.second;});
std::random_shuffle(begin(values), end(values));
auto crtvalue = begin(values);
for(auto & elem : alphabet)
{
elem.second = *crtvalue++;
}
}
The implementation of finding the optimal alphabet follows the description above. Function find_optimal_alphabet takes a vector of strings representing the words and an integer representing the timeout in seconds after which the algorithm should stop and returns a pair of an integer, representing the best score, and a string, representing the alphabet ordering of the best score.
#include <chrono>
std::pair<int, std::string> find_optimal_alphabet(std::vector<std::string>
const & words, int const timeout)
{
std::mt19937 rndgenerator(static_cast<unsigned int>
(std::chrono::system_clock::now().time_since_epoch().count()));
std::uniform_int_distribution<int> distribution(0,25);
auto bestscore = std::make_pair<int, std::string>(0, "");
auto alpha = base_alphabet();
int iteration = 0;
auto start_time = std::chrono::system_clock::now();
while(true)
{
auto crt_time = std::chrono::system_clock::now();
if(std::chrono::duration_cast<std::chrono::seconds>(crt_time-start_time) >
std::chrono::seconds(timeout))
break;
auto score = alphabet_score(words, alpha);
if(score > bestscore.first)
{
bestscore.first = score;
bestscore.second = alphabet_string(alpha);
std::cout << score << " \t" << alphabet_string(alpha)
<< " iteration=" << iteration << std::endl;
}
alter_alphabet(alpha, rndgenerator, distribution);
iteration++;
if((iteration % 1000) == 0)
alter_alphabet(alpha, rndgenerator, distribution);
if((iteration % 5000) == 0)
alter_alphabet(alpha, rndgenerator, distribution);
if((iteration % 50000) == 0)
shuffle_alphabet(alpha);
}
return bestscore;
}
Notice that in order to seed the Marsenne Twister number generator, we use a std::chrono::system_clock available in the <chrono> header that represents the system-wide real time clock. The same system_clock is also used for determining the running time of the algorithm. There are several clocks available in this header, including a high_resolution_clock that is a clock with the smallest tick period available. For the purpose of this sample, the system clock will suffice.
The main function of the program will look like this:
int main()
{
auto bestscore = find_optimal_alphabet(read_words(), 60);
std::cout << "best score:" << std::endl;
std::cout << bestscore.first << " \t" << bestscore.second << std::endl;
return 0;
}
The output we get may look like this (should be different with each running due to the random nature of the altering of the alphabet).
860 ABCDEFGHIJKLMNOPQRSTUVWXYZ iteration=0
1106 PBCDEFGHIJKLMNOAQRSTUVWXYZ iteration=1
1151 PBRDEAGHMJKLINOFQCSTVUWXYZ iteration=5
1170 TBCVQKGOHUWFDJRPSAXLYMZINE iteration=103
1227 FQZOCUKRNYPWLIAMHXJTVGESDB iteration=289
1293 FQZOCUKRNYPWAILMHXJTVGESDB iteration=290
1353 FQROCUKZNYPWAILMHXJTVGEDSB iteration=292
1364 FCRONUKZQYPWAILMHXETVGJDSB iteration=295
1484 CIMXPFOHUABQWZNDYRTLEGJVKS iteration=887
1497 CIBXPFOHUAMQWZNDYRTLEGJVKS iteration=888
1566 CIBXRFOHUAMQWZNDYPTLEGJVKS iteration=889
1598 BCTFAZNXLRHOIMQGUEKPWJSDVY iteration=2009
1766 BCJFAZNXLRHOIMQGUEKPWTSDVY iteration=2010
1819 BCJFAZNXLOURIMQGHEKPWTSDVY iteration=2012
1896 PGBOCHXRVLAKUDIEMWJZNTFQSY iteration=11955
best score:
1896 PGBOCHXRVLAKUDIEMWJZNTFQSY
Improving the Performance
Writing the solution above was not very hard, but it has a disadvantage: it runs sequentially, in a single thread, using a single core of the CPU. Being able to run this algorithm multiple times in parallel should have the potential of finding a more optimal alphabet.
The changes we have to make to the function in order to be able to call it from different threads are minimal. We should remove the printing to console (which is a shared resource and would require synchronization). However, a key aspect is seeding the Marsenne Twister number generator. The previous implementation used the current time (std::chrono::system_clock::now().time_since_epoch().count()) to initialize the algorithm. If we call this several times in a short period, we risk initializing the algorithm with the same value in different threads, and the result is all these generators will produce the same sequence of numbers. To avoid that, we'll have to make sure we initialize it with a different seed. Therefore, we'll make the seed an argument to the function. The rest is basically the same.
std::pair<int, std::string> find_optimal_alphabet_async
(std::vector<std::string> const & words, int const timeout, int const seed)
{
std::mt19937 rndgenerator(seed);
std::uniform_int_distribution<int> distribution(0,25);
auto bestscore = std::make_pair<int, std::string>(0, "");
auto alpha = base_alphabet();
shuffle_alphabet(alpha);
int iteration = 0;
auto start_time = std::chrono::system_clock::now();
while(true)
{
auto crt_time = std::chrono::system_clock::now();
if(std::chrono::duration_cast<std::chrono::seconds>
(crt_time-start_time) > std::chrono::seconds(timeout))
break;
auto score = alphabet_score(words, alpha);
if(score > bestscore.first)
{
bestscore.first = score;
bestscore.second = alphabet_string(alpha);
}
alter_alphabet(alpha, rndgenerator, distribution);
iteration++;
if((iteration % 1000) == 0)
alter_alphabet(alpha, rndgenerator, distribution);
if((iteration % 5000) == 0)
alter_alphabet(alpha, rndgenerator, distribution);
if((iteration % 50000) == 0)
shuffle_alphabet(alpha);
}
return bestscore;
}
What changes more is the main function. Here, we'll create several tasks, each task executing the find_optimal_alphabet_async function in a separate thread. The function is executed asynchronously by calling the std::async function from header <future>. The result of the function call is available in a std::future<T> (from the same header). After the tasks are created, we try to get the result of each function call. Function get() blocks until the result is available. We look through all the results of the functions and select the best score.
#include <future>
int main()
{
auto words = read_words();
int timeout = 60;
std::vector<std::future<std::pair<int, std::string>>> futures(8);
unsigned int seed = static_cast<unsigned int>
(std::chrono::system_clock::now().time_since_epoch().count());
unsigned int index = 0;
for(auto & f : futures)
{
f = std::async(std::launch::async, [&]()
{return find_optimal_alphabet_async(words, timeout, seed + index++);});
}
auto bestscore = std::make_pair<int, std::string>(0, "");
for(auto & f : futures)
{
auto score = f.get();
std::cout << score.first << " \t" << score.second << std::endl;
if(score.first > bestscore.first)
bestscore = score;
}
std::cout << "best score:" << std::endl;
std::cout << bestscore.first << " \t" << bestscore.second << std::endl;
return 0;
}
Here is a possible result for running this parallel version of the algorithm (also for 60 seconds). As you can see, we got some improvements. The more you let it run, the better scores you can get.
1842 VJDTPUCHWROZANBKIMGQYFELSX
2002 BRMOZPTWYXHAJIVULNKQCEGDSF
1887 MBCPYDOVQRWULGAZTKJIFNEXSH
2097 FGQHCUWBJAONVXILKRETPDYMZS
1926 BWRZPCVGHQUOAMIYXFJTLESDNK
1826 QPFYBCJVHLUTEMXOAWIKZNRGDS
1887 CFDGBWZHMUAIVLJQTKYXOPENRS
2032 PDBOMWCAIUFJHLNZVKEYXGRTSQ
best score:
2097 FGQHCUWBJAONVXILKRETPDYMZS
If you look at the CPU loading, you can see that this algorithm utilizes 100% of the CPU.
If you use the Premium or Ultimate versions of Visual Studio, they feature a concurrency visualizer that allows you to examine how a multi-threaded application performs. Here are a couple of screenshots for our application.
Writing Unit Tests
Probably some of you will say that the tests I wrote are not really unit tests. I just wrote some functions that I called in main. I polluted my code with tests. And that is true. But that doesn't mean there are no unit test frameworks so that you can create unit tests separated from the actual code and run them when you build your app, or when you make changes or whenever you want. There are various such unit test frameworks, including one available in Visual Studio. To use it however, we must refactor the project a bit. I will move the core functionality of the solution presented above into a separate Win32 DLL project that will then be linked with the main project and the unit testing project.
The Win32DLL project will contain a header (shown below) with the declaration of the functions exported by the module, a source file with the implementation of these functions, a dllmail.cpp file containing the DllMain function (that is the entry point for a DLL) and an empty export definition file (so that the project will also produce a static library that we can link from our main project).
#pragma once
#include <string>
#include <map>
#include <vector>
#include <random>
#ifdef ALPHAORDER_DLL
#define EXPORTAPI __declspec(dllexport)
#else
#define EXPORTAPI __declspec(dllimport)
#endif
typedef std::map<char, int> alphabet_t;
typedef std::map<int, char> inversed_alphabet_t;
EXPORTAPI alphabet_t base_alphabet();
EXPORTAPI alphabet_t reversed_alphabet();
EXPORTAPI inversed_alphabet_t inverse_alphabet_map(alphabet_t const & alphabet);
EXPORTAPI std::string alphabet_string(alphabet_t const & alphabet);
EXPORTAPI bool is_ordered(std::string const & word, alphabet_t const & alphabet);
EXPORTAPI int alphabet_score(std::vector<std::string> const & words,
alphabet_t const & alphabet);
EXPORTAPI void swap_letter(alphabet_t & alphabet, char const l1, char const l2);
EXPORTAPI void alter_alphabet(alphabet_t & alphabet, std::mt19937 & generator,
std::uniform_int_distribution<int> & uniform_distribution);
EXPORTAPI void shuffle_alphabet(alphabet_t & alphabet);
EXPORTAPI std::vector<std::string> read_words();
EXPORTAPI std::pair<int, std::string> find_optimal_alphabet
(std::vector<std::string> const & words, int const timeout);
EXPORTAPI std::pair<int, std::string> find_optimal_alphabet_async
(std::vector<std::string> const & words, int const timeout, int const seed);
In the main project, we have to include the header with the declaration of the exported functions and a directive to link with the appropriate static library (this can also be put in the project's properties). The rest of the code, i.e., the main function, does not require any additional changes.
#include "..\OptimalAlphaOrderCore\OptimalAlphaOrderCore.h"
#pragma comment(lib, "OptimalAlphaOrderCore")
Notice that you can check the details for this refactoring of the solution in the attached source project.
To write real unit tests and take advantage of the testing framework available in Visual Studio, I will create a Native Unit Test Project.
Here is the solution with the three projects:
There are two things to do before being able to write the unit tests: include the cppunittest.h header and the header with the functions to be tested.
#include "CppUnitTest.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
#include "..\OptimalAlphaOrderCore\OptimalAlphaOrderCore.h"
#pragma comment(lib, "OptimalAlphaOrderCore")
Then we must define a TEST_CLASS that contains TEST_METHODs. These methods represent the unit tests the framework executes. They require very few changes to what we already had in place. Basically, it's only the asserts that are different. Below are the four test methods written earlier migrated to the C++ test framework.
namespace OptimalAlphaOrderTests
{
TEST_CLASS(UnitTest_OptimalAlphaOrder)
{
public:
TEST_METHOD(test_alphabet_string)
{
auto alpha1 = base_alphabet();
auto alphastr1 = alphabet_string(alpha1);
Assert::AreEqual<std::string>
(alphastr1, "ABCDEFGHIJKLMNOPQRSTUVWXYZ", L"Mismatched alphabet string");
auto alpha2 = reversed_alphabet();
auto alphastr2 = alphabet_string(alpha2);
Assert::AreEqual<std::string>
(alphastr2, "ZYXWVUTSRQPONMLKJIHGFEDCBA", L"Mismatched alphabet string");
}
TEST_METHOD(test_swap_letter)
{
auto alpha1 = base_alphabet();
swap_letter(alpha1, 'A', 'B');
auto alphastr1 = alphabet_string(alpha1);
Assert::AreEqual<std::string>(alphastr1, "BACDEFGHIJKLMNOPQRSTUVWXYZ");
auto alpha2 = base_alphabet();
swap_letter(alpha2, 'Y', 'Z');
auto alphastr2 = alphabet_string(alpha2);
Assert::AreEqual<std::string>(alphastr2, "ABCDEFGHIJKLMNOPQRSTUVWXZY");
auto alpha3 = base_alphabet();
swap_letter(alpha3, 'A', 'Z');
auto alphastr3 = alphabet_string(alpha3);
Assert::AreEqual<std::string>(alphastr3, "ZBCDEFGHIJKLMNOPQRSTUVWXYA");
auto alpha4 = base_alphabet();
swap_letter(alpha4, 'I', 'O');
auto alphastr4 = alphabet_string(alpha4);
Assert::AreEqual<std::string>(alphastr4, "ABCDEFGHOJKLMNIPQRSTUVWXYZ");
}
TEST_METHOD(test_is_ordered)
{
auto alpha1 = base_alphabet();
Assert::IsTrue(is_ordered("ABCD", alpha1));
Assert::IsTrue(is_ordered("AABCDXYZ", alpha1));
Assert::IsFalse(is_ordered("AACB", alpha1));
swap_letter(alpha1, 'A', 'B');
Assert::IsFalse(is_ordered("ABCD", alpha1));
Assert::IsFalse(is_ordered("AABCDXYZ", alpha1));
Assert::IsTrue(is_ordered("BAC", alpha1));
Assert::IsTrue(is_ordered("BBAAC", alpha1));
Assert::IsFalse(is_ordered("BCA", alpha1));
}
TEST_METHOD(test_alphabet_score)
{
std::string arrwords[] = {"THIS", "IS", "A", "SIMPLE", "ALPHABET", "SCORE", "TEST"};
std::vector<std::string> words(begin(arrwords), end(arrwords));
Assert::AreEqual(2, alphabet_score(words, base_alphabet()));
Assert::AreEqual(860, alphabet_score(read_words(), base_alphabet()));
}
};
}
When you execute the tests, you see what tests succeeded and what tests failed, where and why they failed, how long it took to execute, etc. You can do different things like re-running the test that failed, or those that didn't run previously, etc. More details about writing native unit tests in Visual Studio can be found here.
Conclusion
The purpose of this article was to show that, despite the common misbelief among people not so familiar with C++, writing in C++ is not that hard. Writing in C++ is not only about directly managing memory (actually in recent years, the use of standardized smart pointers made that obsolete), or doing bitwise operators or other potentially scary, lower level, coding. Using the Standard Template Library and possibly other libraries, one can easily write code with the same productivity as in other mainstream languages. In this article, I've shown how one can use various containers (vector, map, string), algorithms (transform, count_if, swap, random_suffle), generate random numbers (mt19937, uniform_int_distribution), use a clock (chrono::system_clock), run functions asynchronously (async, future), and others. (I didn't use classes and other things usually associated with object-oriented programming because it was unnecessary for the purpose of this article.) I've also presented a sneak peak of some of the available tools in Visual Studio, such as the concurrency visualizer. Lastly, I have shown you how you can take advantage of the testing framework and create and run unit tests for a native project.
I hope that this article has the potential of making those complaining how hard it is to write C++ code that it's not actually so. Writing in C++ can be productive and fun.
History
- 4th October, 2013: Initial version
Marius Bancila is the author of Modern C++ Programming Cookbook and The Modern C++ Challenge. He has been a Microsoft MVP since 2006, initially for VC++ and nowadays for Development technologies. He works as a system architect for Visma, a Norwegian-based company. He works with various technologies, both managed and unmanaged, for desktop, cloud, and mobile, mainly developing with VC++ and VC#. He keeps a blog at http://www.mariusbancila.ro/blog, focused on Windows programming. You can follow Marius on Twitter at @mariusbancila.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






