Introduction
It always struck me as odd that the gap between primes appears to be stochastic. In thinking about the problem, I realized the solution is to view prime numbers as fractal because of the data recursion which drives it. In this article, I will describe the structure of prime numbers using this mindset. Examination of this structure will show the positions of all prime numbers, as well as twin primes, and proves that there are indeed infinitely many twin primes.
Algorithm
An accepted algorithm for finding primes, Sieve of Eratosthenes, works by repetitively marking products of each prime number such that marked values cannot be considered prime and is therefore establishing a pattern of exclusion:
static void Sieve()
{
uint size = 1 << 20;
bool[] notPrime = new bool[size];
for( int x = 2; x < size; x++ )
if( !notPrime[x] )
for( int n = x + x; n < size; n += x )
notPrime[n] = true;
System.Console.Write( "Primes: " );
for( int x = 2, index = 0; x < size && index < 100; x++)
if( !notPrime[x] )
System.Console.Write( "{0}, ", x, index++ );
System.Console.WriteLine();
}
In my algorithm, the sieve algorithm is reductive; instead of maintaining state information for each candidate integer, we simply remove that integer from the potential number line. A naïve way to achieve this is to extend the previous algorithm such that the next loop is reinitialized with only values that are still potentially prime:
static void ReductiveSieve()
{
int size = 1 << 16;
int[] numberLine = Enumerable.Range( 2, size ).ToArray();
int pointer = 0;
while( pointer < numberLine.Length )
{
int x = numberLine[pointer];
int index = pointer;
for( int n = x + x; n < size; n += x )
{
if( numberLine[index] != n )
while( numberLine[++index] < n ) ;
if( numberLine[index] == n )
{
numberLine[index] = 0;
}
}
numberLine = numberLine.Where( n => n > 0 ).ToArray();
pointer++;
}
System.Console.WriteLine( "Primes: {0}", String.Join( ", ", numberLine.Take( 100 ) ) );
}
For each prime number that is passed through the algorithm, count the number of values that are emitted as potentially prime before a number must be excluded as not prime. This produces a pattern as the result of finding virtually-consecutive potentially prime numbers. Due to the fact that the number line is modified between successive passes (introducing the recursion), each pattern is specific and unique to the prime used to generate it; however note that given the correct information, one pattern can be used to generate the next.
static void GeneratePrimePattern( int ordinal )
{
if( ordinal < 1 )
throw new ArgumentOutOfRangeException( "ordinal" );
int size = 1 << 18;
int[] numberLine = Enumerable.Range( 2, size ).ToArray();
int pointer = 0;
while( pointer < numberLine.Length )
{
int x = numberLine[pointer];
int index = pointer;
List<int> pattern = new List<int>();
int skips = 0;
for( int n = x + x; n < size; n += x )
{
if( numberLine[index] != n )
while( numberLine[++index] < n )
skips++;
if( numberLine[index] == n )
{
numberLine[index] = 0;
pattern.Add( skips );
skips = 0;
}
else skips++;
}
numberLine = numberLine.Where( n => n > 0 ).ToArray();
if( pattern.Any() && pointer == ordinal - 1 )
{
int previousValue = 3;
System.Console.WriteLine( "Pattern P({0}) = {1} :: p({0}) = {2}", pointer + 1, numberLine[pointer], String.Join( ", ", pattern.TakeWhile( value => previousValue > 2 && ( previousValue = value ) > 0 ) ) );
return;
}
pointer++;
}
System.Console.WriteLine( "Primes: {0}", String.Join( ", ", numberLine.Take( 100 ) ) );
}
* These code snippets are in the source project, but not part of the call graph; they are commented out in Main.
The pattern emitted by the reductive sieve has a few interesting properties. Each pattern is repeating, and is terminated in all cases by a number <= 2. It is in fact, 2, for all patterns except that of P(1) = 2, which is simply a repeating 1. These patterns, when considered without their terminators, have an odd length and are symmetric from the center digit ( e.g. A, B, C, B, A, 2 ). In addition, the sum of all of the digits in a given pattern is the length of the next pattern:
| Index | Value | Pattern Length | Pattern | Sum | Average |
| 1 | 2 | 1 | 1 | 1 | 1 |
| 2 | 3 | 1 | 2 | 2 | 2 |
| 3 | 5 | 2 | 6, 2 | 8 | 4 |
| 4 | 7 | 8 | 11, 6, 3, 6, 3, 6, 11, 2 | 48 | 6 |
| 5 | 11 | 48 | 25, 4, 9, 4, ..., 4, 9, 4, 25, 2 | 480 | 10 |
| 6 | 13 | 480 | 33, 8, 6, 10, ..., 10, 6, 8, 33, 2 | 5760 | 12 |
| 7 | 17 | 5760 | 54, 5, 12, 18, ..., 18, 12, 5, 54, 2 | 92160 | 16 |
| 8 | 19 | 92160 | 64, 12, 18, 6, ..., 6, 18, 12, 64, 2 | 1658880 | 18 |
| 9 | 23 | 1658880 | 90, 22, 6, 20, ..., 20, 6, 22, 90, 2 | 36495360 | 22 |
Notation
For this article, I will refer to a function which generates primes from their index values: P(x) = n
P(4) = 7
As well as the patterns that are generated for each prime: p(x) = [...]
p(4) = 11, 6, 3, 6, 3, 6, 11, 2
When referring to the entire set, the format is P(x) = n :: [...]
P(4) = 7 :: [11, 6, 3, 6, 3, 6, 11, 2]
A tick denotes that a pattern is reversed: dp(x)’ A double tick denotes that a pattern has been specially mirrored: dp(x)”
dp(4) = 4, 2, 4, 2, 4, 6, 2
dp(4)' = 2, 6, 4, 2, 4, 2, 4
dp(4)" = 4, 2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2, 4 + 6, 2, 6
The dot operator performs special concatenation while paying attention to an overlapping digit in the series.
dp(4)" = dp(4) . dp(4)' + [ . ]
The [ . ] notation is odd, I know. I mean to say that we must establish how dp and dp’ were combined (e.g. with a [6,2,6], which is tail( dp(x), 2)”, but I don’t mean to recurse). I apologize that I don’t know the mathy way to describe this. It’s ironic that the abstract method of conceptualizing this long-standing problem is a bit of a hindrance in expressing the notion. Another way of looking at our symmetric pattern is to say: it’s already a mirror, let’s mirror the mirror in a way that has smooth edges formed by both sides of the original symmetric pattern. Please note that while p(4) was short enough to express this, the simplicity of this pattern does not imply that the dot operation I describe is needed. Examining larger patterns shows that it is a special type of mirroring operation which is demonstrated in the attached code using Linq extension methods inside the RepeatingPattern.Expand function.
Obtaining the Pattern
For P(1) = 2 :: [1], we should exclude even digits from being considered potentially prime. This means that we are emitting one value (3), excluding one value (4), emitting (5) and excluding (6). Therefore P(1) will emit all of the odd numbers greater than 2:
3, [4], 5, [6], 7, [8], 9, [10], 11, [12], 13, [14], 15, [16], 17, [18], 19, [20], 21 ...
This results in the pattern [1] because we emit 1 potentially prime number before ruling out a value.
For P(2) = 3 :: [2], we follow the same pattern, only this time we emit two values as potentially prime before excluding a number. Starting with n = 3, we emit 5, then 7, and then remove 9. Emit 11, 13, and remove 15. The process continues, emitting:
5, 7, [9], 11, 13, [15], 17, 19, [21], 23, 25, [27], 29, 31, [33], 35 ...
This results in the pattern [2] because we emit 2 potentially prime numbers before ruling out a value.
For P(3) = 5 :: [6, 2], we follow the same pattern but increment the index of the value in the pattern to use as the number of values to emit after each skip is processed. Emit 6 values, skip 1 value, emit 2 values, and again skip 1 value:
7, 11, 13, 17, 19, 23, [25], 29, 31, [35], 37, 41, 43, 47, 49, 53, [55], 59, 61, [65] ...
This results in the pattern [6,2] because we emit 6 potentially prime numbers before ruling one out, followed by two more potentially prime numbers before ruling one out. The pattern then repeats. Subsequent patterns are continually generated ad nauseam.
Rendering from the Pattern, a Naïve Approach
Already we can see how this can be used to generate primes if we have the patterns already stored in memory. Start by iterating all of the natural numbers sequentially, starting at 3 (the first value after P(1)). Pass each value as input to a set of filters configured with respective patterns [P(1) .. P(x)]. The operation of each filter will either skip to the next iteration or emit the input value into the next filter in the chain. The last filter will emit prime values while the input value is less than the square of P(x).
The filter operates by tracking the count of input values it has received and an index within the pattern. The input value is emitted into each successive filter while the counter is less than the value of the pattern at the current index. When the counter reaches the current pattern value, the counter is reset and the index is incremented, modulating on the length of the pattern. If a value is not emitted into the next filter, the next iteration should begin immediately.
Analysis
My ultimate goal when starting this research was to find the formula that allows finding prime values by index. With this in mind, we can conclude that in order to generate a prime we only need the patterns whose seed prime value is equal to and less than the square root of the value we are attempting to find.
During pattern generation, the first exclusion of each pattern occurs at the pattern’s prime value squared:
- P(1) = 2 First exclusion is 4
- P(2) = 3 First exclusion is 9
- P(3) = 5 First exclusion is 25
During pattern generation, we can also emit the values which correspond to each skipped number. These numbers are not prime themselves, as they are effectively marked non-prime, however which pattern causes the skip is of interest. Examining the pattern for P(4) = 7 whose set is [11, 6, 3, 6, 3, 6, 11, 2]. The values which are skipped are therefore, respectively: [49, 77, 91, 119, 133, 161, 203, 217]. All of the numbers here inherently divisible by 7; when factored the list becomes: [7, 11, 13, 17, 19, 23, 29, 31]. It’s worth noting that because the patterns repeat, the list would technically continue. However, the point where a pattern enforces a skip is of interest in understanding the relationships of the values we have produced.
For the previous pattern, P(3) = 5 is [6,2], the values that are skipped start with: [25, 35, 55, 65, 85, 95, 115, 125]. Factoring we see 5 * [5, 7, 11, 13, 17, 19, 23, 25]. We see that the values that this pattern can generate are prime up to 23. The number of primes that can be emitted, not including the value associated with the pattern used for generation, is the first value of the pattern [6]. In fact, if we continue our sample, we will see [145, 155, 175, 185], factoring to 5 * [29, 31, 35, 37]. This means we have found 2 more consecutive primes before needing to reject an emitted value. This property is consistent for any established pattern: The values associated with skip points are directly divisible into a sequence of prime numbers which starts with the n for P(x) = n and includes m sequential prime numbers where m is the value at the particular index of p(x).
Understand the Pattern
The analysis above shows that the values associated with skipped values can be directly divided into a prime. We see that for pattern value we store, we have an associated prime. We see that because each pattern starts with the associative prime, there is a great deal of overlap between successive patterns:
P(2) = 3 :: [3]
P(3) = 5 :: [5, 7]
P(4) = 7 :: [7, 11, 13, 17, 19, 23, 29, 31]
P(5) = 11 :: [11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, ...]
This is good news because if we can devise the math to get from pattern values (aka emit counts) we can use a pattern to directly output a prime without calculating other primes. Assuming we can generate the pattern for any base prime, and that we can select the correct base prime pattern to generate, it is likely we can seriously reduce the complexity of generating prime numbers.
Let’s examine p(4):
P(4) = 7 :: [11, 6, 3, 6, 3, 6, 11, 2]
The value noted for each skip was:
[49, 77, 91, 119, 133, 161, 203, 217]
Knowing that each pattern starts with P(x)^2, we can exclude the first value: 49. We can then reduce the list by the distance between each value by performing a running subtraction: 77 - 49, 91 - 77 ... Since these are again multiples of P(x), we can further simplify by factoring out the associated prime and produce dp(x):
[28, 14, 28, 14, 28, 42, 14] / 7 = [4, 2, 4, 2, 4, 6, 2]
An interesting new feature appears. Patterns are still terminated with a 2, but 2s are now legal within the pattern. There is still symmetry, but now the last two digits are excluded. This is reinforced by how dp(x)” will need to be constructed. The rest of the digits demonstrate the same type of pattern, and graphs similarly to that of the output of p(x), but the second to last digit now seems to be the average of the values contained within p(x).
Performing the same translation on p(5):
P(5) = 11 : [25, 4, 9, 4, 10, 14, 3, 15, 9, 4, 8, 14, 15, 4, 14, 9, 4, 14, 10, 13, 19, 10, 4, 8, 4, 10, 19, 13, 10, 14, 4, 9, 14, 4, 15, 14, 8, 4, 9, 15, 3, 14, 10, 4, 9, 4, 25, 2]
The value noted for each skip was:
[121, 143, 187, 209, 253, 319, 341, 407, 451, 473, 517, 583, 649, 671, 737, 781, 803, 869, 913, 979, 1067, 1111, 1133, 1177, 1199, 1243, 1331, 1397, 1441, 1507, 1529, 1573, 1639, 1661, 1727, 1793, 1837, 1859, 1903, 1969, 1991, 2057, 2101, 2123, 2167, 2189, 2299, 2321]
After performing a running subtraction and division, dp(5):
[2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 6, 6, 2, 6, 4, 2, 6, 4, 6, 8, 4, 2, 4, 2, 4, 8, 6, 4, 6, 2, 4, 6, 2, 6, 6, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2, 10, 2]
Once again, all but the last two digits form a symmetric pattern, which the average of p(5) being 10, and the terminator carried through. I believe the terminator serves a few purposes, one being to allow stripping of the two end values. When running successively large patterns, the first and second to last digit of each p(x) are relatively high values when compared to the rest of the set. Comparing just the inner set of p(x) to p(x)[i] – p(x)[i-1], we find a striking similarity:
11: 6, 3, 6, 3, 6 :11
4, 2, 4, 2, 4
25: 4, 9, 4, 10, 14, 3, 15, 9, 4, 8, 14, 15, 4, 14, 9, 4, 14, 10, 13, 19, 10, 4, 8, [mirror]
2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 6, 6, 2, 6, 4, 2, 6, 4, 6, 8, 4, 2, 4, [mirror]
This demonstrates that these patterns share the same wave form, although the amplitudes differ greatly. Another notable component is that each successive pattern contains the previous pattern:
p(4) . p(4)' = [ 4, 2, 4, 2, 4, 6, 2 ] . [ 2, 6, 4, 2, 4, 2, 4 ] =
[4, 2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2+4]
p(5) = [2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 6, 6, 2, 6, 4, 2, 6, 4, 6, 8, 4, 2, 4, [mirror]]
When building dp(4)”, the patterns are mirrored and merged on the last/first element. Paying attention to the alignment of the sets, you can see that the first pattern is embedded in the beginning (and also therefore end) of the second pattern, with the exception of the first digit. The skipped portion is the exact length of the first portion. The last two digits were added to produce the final direct overlap. This would seem to be stretching it a bit; however the same pattern continues to occur. Let’s look at overlaps from dp(4) and dp(5). The first row is a repeating dp(4)” offset by one, and the second row is dp(5). Where the values are not identical, a correction can be made by summing with the next digit in the sequence in the mirrored sequence. Pay attention to when these additions occur:
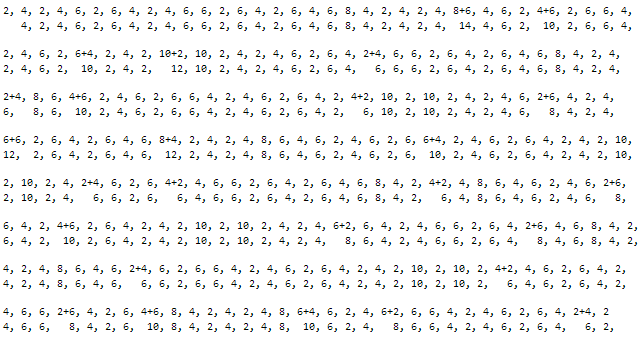
Do you see it? It is clear that when patterns are put on equal terms by reducing to them to differential skip counts, we can predict the successive pattern. But how do we know where the additions occur?
Let’s examine this construct for p(4):
P(4) = 7
p(4) = [11, 6, 3, 6, 3, 6, 11, 2]
dp(4) = [4, 2, 4, 2, 4, 6, 2]
Attach the mirror sequence dp(4)’ overlapping the center value:
m = [4, 2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2, 4]
The meta portion of the sequence (6, 2) should be reflected in the same manner:
w = [6, 2, 6]
The length of m+w is known:
r * ( len( m ) + len( w ) ) = sum( p( 4 ) ) = 48
This means we should repeat the pattern 3 times: mwmwmw
Examining the output offset with the target pattern, dp(5):
4, 2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2+4, 6, 2, 6, 4, 2, 4+2, 4, 6, 2+6, 4, 2, 4, 2, 4, 6+2,
2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 6, 6, 2, 6, 4, 2, 6, 4, 6, 8, 4, 2, 4, 2, 4, 8,
6, 4, 2+4, 2, 4, 6, 2, 6, 4+2, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2, 4+6, 2,
6, 4, 6, 2, 4, 6, 2, 6, 6, 4, 2, 4, 6, 2, 6, 4, 2, 4, 2, 10, 2,
We see that there are locations where we must add the values together. Thinking back to what the patterns represent (emissions and skips), this makes sense because there are locations that are rendered unavailable by specific patterns. We have shifted the math such that we are now counting consecutiveness and therefore skipping a value is the same as adding against next value in the sequence. In this case, the consecutive values that are passed through when generating the next pattern come with in a pattern themselves. Before 2+4 there are 10 values, therefore the position of 2+4 is 11. Between this addition and the next addition, 4+2, there are 5 values, giving it a relative position of 6. Following this trend, you produce the following pattern:
[11, 6, 3, 6, 3, 6, 11]
This shows how a pattern dp(x+1) can be expanded from a seed p(x) and the corresponding dp(x).
Rendering Primes
Given a particular p(x), it is possible to generate n consecutive primes in near O( log N ) time by exchanging computation with memory. Because dp(x) holds the consecutive gaps of length P(x), and P(x)^2 is the first prime emitted by filter p(x), and of course we know x, we can directly calculate the prime:
P( x + i ) = ( sum( first( dp( x ), i ) ) * p + p^2 ) / p
x is the index of the pattern we are using p is the associated prime / lowest value that dp(x) can generate i is the desired index of the available primes from dp(x)
With dp(4) as an example:
// Conceptually
dp(4) = [4, 2, 4, 2, 4, 6, 2]
p = P(n = 4) = 7
i = 2
P(6) = ( sum( [4,2] ) * 7 + 49 ) / 7
= 91 / 7
= 13
// Simplified
P(8) from dp(4) => 7 + sum( [4,2,4,2] )
= 7 + 12
= 19
The operation is not linear, sadly, but we’re getting closer! Unfortunately, considering that patterns get very long very quickly, the load time required to inflate a pattern would not be a happy trade for reducing the math required to generate primes by index.
A clever implementation of this algorithm could start with a known pattern and expand it in place disregarding values above the desired index and just keeping a running sum which would allow the proper values to be found with a relatively small memory footprint, provided the mirroring nature of pattern expansion can be correctly handled.
Twin Primes
The discovery of this structure also proves that there are infinitely many twin primes. The first two patterns: [1], [2] are the basis for all twin primes. The first pattern ensures that every other value is skipped, yielding only odd numbers. The second allows two odd numbers to be emitted consecutively before another skip occurs, generating the twin prime candidates. The next applied value comes from the next pattern [6, 2] whereby 6 becomes the number of values emitted, and values emitted are pairs of twin prime candidates. Therefore the 6 would emit 3 pairs of potentially twin primes.
In order to solve which pairs are prime, we look at the algorithm for expanding patterns: dp(x). We can conclude that each 2 in dp(x) is a twin prime because dp(x) represents the relative jumps between primes. Also, because each prime represents a pattern, each P(x) is the start of a twin prime pair where dp(x) starts with a two. Subsequent patterns will cause skips to occur (at known boundaries), but it can be assured that while iterating the chain of patterns (see filter-based naïve approach), p(2) will produce infinitely many twin primes such that p' - p = 2k for k = 1 is not bound. I hereby offer Alphonse de Polignac a posthumous round on me.
Because dp(x+1) can be generated by applying p(x) to dp(x)”, it can be shown that both primes and twin primes occur very specifically. There is no randomness in the structure of prime numbers. Also, it is quite likely that the maximum value between twin primes can be found by careful analysis of the mechanism for expanding patterns in conjunction with permutation-based mathematics.
Is 1 Prime?
I did spend some time pondering the legitimacy of 1 being a prime number: P(0) = 1. I feel like the rule preventing this is one of semantics. 1 is divisible by 1 and itself. It’s sort of arbitrary to just say: “No dupes!” to exclude exactly one case. It would seem that one is indeed the loneliest number. With the development of this solution, I came to realize that p(0) cannot be described (as much as I would like it to have been). If p(0) == [0], then p(1) must have a length of 0, and so this is incorrect. The next pattern has a length of one, and so p(0) == [1]? False. The algorithm prescribes a skipping strategy, and therefore a number that does not prescribe a skipping strategy has an undefined effect. And so at long last I jump on board with the opinion that 1 should be excluded as not prime. Then again, one is the number that seeds all of the patterns considering you start generating patterns from P(1) = 2 :: [1], and so I take solace in the fact that one is excluded because it represents the fundamental unit from which all primes and prime gap patterns emerge.
Software Architect by day, Theoretical Mathematics and Cosmology Hobbyist by night.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







