Three Related Articles
- We make any object thread-safe
- We make a std::shared_mutex 10 times faster
- Thread-safe std::map with the speed of lock-free map
Introduction
In these three articles, I’ll tell in detail about atomic operations, memory barriers and the rapid exchange of data between threads, as well as about the “sequence-points” by the example of “execute-around-idiom”. At the same time, we will try to do something useful together.
There are no thread-safe containers (array, list, map ...) in the standard C++ library, which could be used in multiple threads without additional locks. In case of usage of standard containers for multithreading exchange, there is a danger for you to forget to protect one of the code sections with mutex or by mistake to protect it with another mutex.
Obviously, a developer will make more mistakes if he/she uses his/her own solution instead of a standard one. And if the task is so complex that there is no any standard solution, then the developer, while trying to find a solution, will be awash with errors.
Relying on the “practicality beats purity” principle, we will try to create not an ideal, but a practical solution to this problem.
In this article, we will realize a smart pointer that makes any object thread-safe, with the performance equal to that of optimized lock-free containers.
A simplified, non-optimized example of using such a pointer:
int main() {
contfree_safe_ptr< std::map< std::string, int > > safe_map_string_int;
std::thread t1([&]() { safe_map_string_int->emplace("apple", 1); });
std::thread t2([&]() { safe_map_string_int->emplace("potato", 2); });
t1.join(); t2.join();
std::cout << "apple = " << (*safe_map_string_int)["apple"] <<
", potato = " << (*safe_map_string_int)["potato"] << std::endl;
return 0;
}
We will cite a quotation from the standard, which guarantees the necessary behavior, for each step of our algorithm.
We will consider C++ memory model, as well as different possible versions of synchronization and data exchange between threads, in detail.
In this article, we will develop a thread-safe pointer safe_ptr<>. In the second article, we will realize an optimized “contention-free shared-mutex” and an optimized pointer contfree_safe_ptr<> on its basis. And in the third article, we will show examples of optimal utilization of contfree_safe_ptr<> and provide performance tests, and we will compare it with highly optimized lock-free containers.
Background
We will start with developing a safe_ptr<T> smart pointer template that will be thread-safe for any type of T and will show multithreaded performance at the level of optimized lock-free algorithms.
Besides, it will enable us to work atomically and consistently with several different objects at the same time, where one would have to use locks even for lock-free data structures, and where the risk of eternal deadlocks would appear. However, we will develop a special mutex lock class that resolves the situations of deadlocks. Then we will realize our own high-performance contention-free shared-mutex, which is much faster than the standard std::shared_mutex. And, on its basis, we will create an optimized version of safe pointer safe_ptr<T>, named contfree_safe_ptr<>. At the end, we will run performance tests, while comparing with the lock-free library libCDS. We will see performance that is close to libCDS (SkipListMap and BronsonAVLTreeMap) by the example of contfree_safe_ptr<std::map<>>.
As a result, to make any of your classes thread safe, you do not need much time, you should just write: contfree_safe_ptr<T> ptr_thread_safe;
The performance will be almost such as if you’d been developing lock-free algorithms in your class methods for a month. In addition, it will be possible to atomically change several contfree_safe_ptr<> at once. As well as std::shared_ptr<>, our smart pointer will contain a reference count. It can be copied, and after removing the last copy, the dynamically allocated memory will be automatically released.
In the end, 1 safe_ptr.h file will be provided, which is enough to be connected through #include “safe_ptr.h” in order to let you use this class.
Basic Principles of Multithreaded Data Exchange
As you know, we can read and change the same object from different threads only in the following four cases:
- Lock-based. The object is protected by
lock: spin-lock, std (mutex, recursive_mutex, timed_mutex, shared_timed_mutex, shared_mutex ...): http://en.cppreference.com/mwiki/index.php?title=Special%3ASearch&search=mutex - Atomic. The object is of type
std::atomic<T>, where T is the pointer, bool or integral type (std::is_integral<T>::value == true), and only if there are atomic operations existing for T type at CPU level: http://en.cppreference.com/w/cpp/atomic/atomic (2+1) - (Lock-based-Atomic) Otherwise, if T type is trivially copyable type, i.e., it satisfies the condition std::is_trivially_copyable<T>::value==true, then std::atomic<T> works as Lock-based - a lock is automatically used inside it. - Transaction-safe. Functions, which are realized for work with the object, provide a thread-safe guarantee transaction_safe (Transactional Memory TS (ISO/IEC TS 19841:2015) - Experimental C++): http://en.cppreference.com/w/cpp/language/transactional_memory
- Lock-free. Functions for work with the object are realized on the basis of lock-free algorithms, i.e., they provide a lock-free thread-safe guarantee.
If you perfectly know all four ways to ensure thread-safety, then you can skip this chapter.
Let us consider the reverse order:
(4) Lock-free algorithms are quite complex, and, often, several scientific works are required to create each complex algorithm. Examples of lock-free algorithms for work with containers - unordered_map, ordered_map, queue ... - and links to the scientific works can be found in the library - Concurrent Data Structures (CDS) library: https://github.com/khizmax/libcds.
These are very fast and reliable multithreaded data structures, but so far, there are no plans to include them in the standard C++17 or C++20 libraries, and they are not included in the standards draft: http://www.open-std.org/JTC1/SC22/WG21/.
(3) Transaction-safe is planned to be included in the experimental part of C++ standard, and there is already a draft of ISO/IEC TS 19841:2015 at http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/N4514.pdf.
But even not all STL-containers are planned to be made transaction-safe. For example, std::map container is not even planned to be made transaction-safe, as only the following functions are defined as transaction-safe for it: begin, end, size, max_size, empty. But the following functions are not defined as thread-safe: find, modify, insert. And it is not easy at all to realize own object with transaction-safe member functions, otherwise it would be done for std::map.
(2) Atomic. This approach has already been standardized in C++11, and you can easily use it. For example, it’s enough to declare the variable std::atomic<int> shared_val, then to pass a link or a pointer to it in several threads, and all calls through member functions and operators std::atomic will be thread-safe: [3] http://coliru.stacked-crooked.com/a/9d0219a5cfaa3cd5.
Member functions, specialized member functions: http://en.cppreference.com/w/cpp/atomic/atomic
It is important to understand that if you perform several atomic variable operations (it does not matter, if it happens in one expression or in several expressions), then another thread between them can change the value of that variable. Therefore, for the atomic execution of several operations, we use the Lock-free approach, which is based on CAS-function (Compare-And-Swap) compare_exchange_weak() - namely: we read the value from the atomic variable into the local variable (old_local_val), perform a lot of necessary operations and write the result to the local variable (new_local_val), and at the end, we compare the current value of the atomic variable with the initial value (old_local_val) by means of CAS-function; if they are not equal, then we perform the cycle anew, and if they are equal - it means that during this time another thread has not made any changes, then we change the atomic variable value with a new value (new_local_val). At that, the comparison and assignment are done by means of one operation: compare_exchange_weak() - it is an atomic function and until it is fully executed, no one can change the value of the variable: [4] http://coliru.stacked-crooked.com/a/aa52b45150e5eb0a.
This approach with a cycle is known as an optimistic lock. Pessimistic locks are: spin-lock, mutex ...
And if all operations of such a cycle are performed without pessimistic locks, then such an algorithm is called lock-free. And more precisely, such an algorithm can have some of the guarantees: obstruction-free, lock-free, wait-free or write-contention-free.
Often, the atomic CAS-function replaces the pointers, namely: a new memory is allocated, a modified object is copied to it, and a pointer to it is obtained; a number of actions are performed on this copy, and at the end, CAS-function replaces the old pointer with a new object pointer, if within this time, another thread has not changed the old pointer. But if the pointer has been changed by another thread, then everything is repeated again.
A possible problem called “ABA” can appear here - https://en.wikipedia.org/wiki/ABA_problem when other threads have time to change the pointer twice, and, there, the pointer changes to the initial value for the second time, but at this address other threads have already been able to delete the object and create a new one. That is to say, the value of the pointer already indicates another object, but we see that the value has not changed and think that the object has not been replaced. There are many ways to solve this problem, for example: LL/SC, RCU, hazard_pointer, garbage collector ...
Atomic is the fastest way to exchange data between threads. Besides, for all atomic operations, less stringent and faster memory barriers can be used, which will be discussed in detail later. By default, the most secure and stringent reordering barrier is used: std::memory_order_seq_cst. But as we noted above: you need a lot of effort to realize complex logic by using atomic variables.
(2) - (1) Atomic & Lock-based.
But if you need to read or change several variables at once - std::atomic<int> a, b, c, and you do not want to realize a lock-free algorithm and solve the ABA-problem, then you need to use a lock. The CPU atomic CAS-function (in most CPUs) can check whether only one variable with a maximum width of 64-bit has been changed, but at that time another variable could have been changed. The solution: std::atomic<T> allows using structures of any size for T-type.
In C++ standard, it is possible to use any type of T for std::atomic<T>, if it is a “trivially copyable type”, i.e., if it satisfies the condition std::is_trivially_copyable<T>::value == true.
What does C++ standard tell: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
§29.5 / 1
Quote:
There is a generic class template atomic<T>. The type of the template argument T shall be trivially copyable (3.9). [Note: Type arguments that are not also statically initializable may be difficult to use- end note]
§3.9 / 9
Quote:
Scalar types, trivially copyable class types (Clause 9), arrays of such types, and cv-qualified versions of these types (3.9.3) are collectively called trivially copyable types
But if the CPU atomic CAS-function can check whether only one variable with a maximum width of 64-bit has been changed, and we have three 32-bit variables, then how would CAS-function work in std::atomic<T>? CAS-function and all other functions will automatically use the lock (std::mutex or some other), which is contained in the standard realization of std::atomic<T>, for T - trivially copyable types.
To change several variables atomically, we can use a structure of variables struct T {int price, count, total; }; as a type for std::atomic<T> template.
Example: [5] http://coliru.stacked-crooked.com/a/bdfb3dc440eb6e51
Example output: 10, 7, 70
In this example, at any time, the last value of 70 will be equal to the product of the first two values p- 10*7 - i.e., the whole structure changes only atomically.
This code in gcc and clang for x86 is to be compiled with the -latomic flag.
In this case, each call to std::atomic<T> shared_val; will cause a lock inside it, as indicated by the value of the function shared_val.is_lock_free() == false.
I.e., globally, we used an optimistic lock (cycle), and locally used 2 pessimistic locks when addressing an atomic variable: getting the old value and calling CAS-function.
(1) Lock-based
But we cannot use std::atomic<T> for any types of T that you have created because of the “trivially copyable” necessary condition for T type. Of all the STL-containers, we can only use std::array<>. For example, we cannot use std::atomic<std::map<int, int>>, because std::map<> type is not trivially copyable for any arguments of its template. And, most likely, your own classes also cannot be used as a T type for std::atomic<T>.
In this case, you have to create mutex objects by yourself and to lock them each time before using shared objects and unlock after that. Concept: http://en.cppreference.com/w/cpp/concept/Mutex
In C++, the following mutexes exist: std::mutex, std::recursive_mutex, std::timed_mutex, std::recursive_timed_mutex, std::shared_timed_mutex, std::shared_mutex. For more information, see: http://en.cppreference.com/w/cpp/thread.
For example, we create any std::map<int, T> object shared among the threads and create a mutex protecting it, then we pass their links to several threads. And in each thread, we lock the mutex before using a shared object: [6] http://coliru.stacked-crooked.com/a/a97e905d54ae1fbb.
And we perform locking by using the RAII-idiom:
std::lock_guard<std::mutex> lock(mtx); - When this object is being created, its constructor locks the mutex, and at the end of the object’s lifetime, the destructor unlocks the mutex. So, we definitely will not forget to unlock it, because the destructor will be called automatically.
But there are still four main problems:
- Deadlocks - If you write the code in such a way that thread-1 locks
mtx1, and thread-2 locks mtx2, and, while holding the lock, thread-1 tries to capture mtx2, and thread-2 tries to capture mtx1, then these threads would wait for each other forever. This problem does not exist for lock-free algorithms, but not any logic can be realized with the help of lock-free - we will demonstrate it with the example of consistent atomic change of several containers. - If you write the code in such a way that while the mutex is locked you assign a shared object link to a pointer, the lifetime of which is longer than that of
std::lock_guard lock, then after unlocking you can refer to the shared object by this pointer - this will lead to Data races problem, i.e., it will cause non-consistent state of the shared object and incorrect operation or crash of the program. The same thing happens if the iterator is used after unlocking the mutex. - You can confuse with mutexes and lock a mutex that protects another object - Data races.
- You can just forget to lock the mutex in the right place - Data races.
Execute Around Pointer Idiom
Besides the RAII-idiom, there is another interesting idiom - Execute Around Pointer, which helps to solve the last two problems:
- The mutex will be fused with your object, and you will be able to lock your object itself, but not a separate mutex.
- The mutex will be locked automatically when addressing to any member of the
protected object class - there, it will be locked for the duration of an expression execution.
As a result, you cannot forget to lock the mutex, and you cannot confuse with the mutexes.
We Make Any Object Thread Safe
Execute Around Pointer Idiom is a well-known idiom with a strictly defined order of execution, which is used for various purposes from visualization to logging:
https://en.wikibooks.org/wiki/More_C%2B%2B_Idioms/Execute-Around_Pointer
Example: [7] http://coliru.stacked-crooked.com/a/4f3255b5473c73cc
execute_around< std::vector< int > > vecc(10, 10);
int res = my_accumulate(vecc->begin(), vecc->end(), 0);
First, proxy type temporary objects will be created. They will lock the mutexes inside execute_around, then the iterators returned by the functions begin() and end() will be passed to the function, and then my_accumulate() function will be executed, and only after its completion, the proxy type temporary objects will be deleted, and their destructors will unlock the mutexes.
For more details, see article: C++ Patterns Executing Around Sequences. Kevlin Henney: http://hillside.net/europlop/HillsideEurope/Papers/ExecutingAroundSequences.pdf
In C ++, there are two definitions that strictly define the order of operations of C++ Standard § 1.9 (13): sequenced before and sequenced after. In the below quotations of the standard, you will see “sequenced before” twice.
The principle and sequence of execution of all actions in the Execute Around Pointer Idiom are strictly described in the standard. First, we will cite five quotations from the C++ standard, and then we’ll show you how each of the quotations explains the behavior of the Execute Around Pointer Idiom.
Five quotations from the C++ standard, Working Draft, Standard for Programming Language C++ N4606 2016-07-12: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
- For all the types that are different from raw-pointers:
x->m is interpreted as (x.operator->())->m, i.e., expression (x->m) will expand repeatedly ((x.operator->().operator->())->m, till we get the raw-pointer. Example with three expressions identical in their meaning: [8] http://coliru.stacked-crooked.com/a/dda2474024b78a0b
Quote:
§ 13.5.6
operator-> shall be a non-static member function taking no parameters. It implements the class member access syntax that uses ->.
postfix-expression -> template opt id-expression
postfix-expression -> pseudo-destructor-name
An expression x->m is interpreted as (x.operator->())->m for a class object x of type T if T::operator->() exists and if the operator is selected as the best match function by the overload resolution mechanism (13.3).
- When a function is called, even if it is “inline”, absolutely any calculations and effects from expressions that evaluate the arguments of a function are executed before the body of the function starts executing.
Quote:
§ 1.9 / 16
When calling a function (whether or not the function is inline), every value computation and side effect associated with any argument expression, or with the postfix expression designating the called function, is sequenced before execution of every expression or statement in the body of the called function.
- The expression is fully executed before a temporary object is destroyed.
Quote:
§ 1.9 / 10
void f() {
if (S(3).v()) { }
}
- After the entire expression is fully executed, the temporary objects are destroyed in reverse order with respect to the order of their creation.
Quote:
§ 1.9 Footnote 8
As specified in 12.2, after a full-expression is evaluated, a sequence of zero or more invocations of destructor functions for temporary objects takes place, usually in reverse order of the construction of each temporary object.
- Three cases, when a temporary object is destroyed at a different point than the end of the full expression – 2 cases upon initialization of the elements of the array, and the 3rd case - when a reference to a temporary object is created.
Quote:
§ 12.2 Temporary objects
§ 12.2 / 5
There are three contexts in which temporaries are destroyed at a different point than the end of the full expression. The first context is when a default constructor is called to initialize an element of an array with no corresponding initializer (8.6). The second context is when a copy constructor is called to copy an element of an array while the entire array is copied (5.1.5, 12.8). In either case, if the constructor has one or more default arguments, the destruction of every temporary created in a default argument is sequenced before the construction of the next array element, if any. The third context is when a reference is bound to a temporary.
For example, we have a simplified class, execute_around<>:
template< typename T, typename mutex_type = std::recursive_mutex >
class execute_around {
std::shared_ptr< mutex_type > mtx;
std::shared_ptr< T > p;
void lock() const { mtx->lock(); }
void unlock() const { mtx->unlock(); }
public:
class proxy {
std::unique_lock< mutex_type > lock;
T *const p;
public:
proxy (T * const _p, mutex_type& _mtx) :
lock(_mtx), p(_p) { std::cout << "locked \n";}
proxy(proxy &&px) : lock(std::move(px.lock)), p(px.p) {}
~proxy () { std::cout << "unlocked \n"; }
T* operator -> () {return p;}
const T* operator -> () const {return p;}
};
template< typename ...Args >
execute_around (Args ... args) :
mtx(std::make_shared< mutex_type >()), p(std::make_shared< T >(args...)) {}
proxy operator->() { return proxy(p.get(), *mtx); }
const proxy operator->() const { return proxy(p.get(), *mtx); }
template< class Args > friend class std::lock_guard;
};
And we use our template class execute_around<> in the following way, for example:[45] http://coliru.stacked-crooked.com/a/d2e02b61af6459f5
int main() {
typedef execute_around< std::vector< int > > T;
T vecc(10, 10);
int res = my_accumulate(vecc->begin(), vecc->end(), 0);
return 0;
}
Then the last expression can be reduced to the following form after several transformations.
- According to the first quote of the standard,
x->m is interpreted as (x.operator->())->m:
int res = my_accumulate(
(vecc.operator->())->begin(),
(vecc.operator->())->end(),
0);
- As
vecc.operator->() returns the temporary object T::proxy(), then we receive:
int res = my_accumulate(
T::proxy(vecc.p.get(), *vecc.mtx)->begin(),
T::proxy(vecc.p.get(), *vecc.mtx)->end(),
0);
- Further, according to quotations 2, 3 and 4, - temporary proxy type objects will be created before the function starts executing and will be destroyed after the end of the function (after the end of the entire expression):
T::proxy tmp1(vecc.p.get(), *vecc.mtx); T::proxy tmp2(vecc.p.get(), *vecc.mtx); int res = my_accumulate(tmp1->begin(), tmp2->end(), 0);
tmp2.~T::proxy(); tmp1.~T::proxy();
- Again, according to the first quotation:
tmp1->begin() is equivalent to (tmp1.operator->())->begin()tmp1.operator->() returns p
As a result, we get, where p is the pointer to our object of type std::vector<int>:
typedef execute_around< std::vector< int > > T;
T vecc(10, 10);
T::proxy tmp1(vecc.p.get(), *vecc.mtx); T::proxy tmp2(vecc.p.get(), *vecc.mtx);
int res = my_accumulate(tmp1.p->begin(), tmp2.p->end(), 0);
tmp2.~T::proxy(); tmp1.~T::proxy();
In four steps, we described the strict sequence of all idiom actions. Note that the standard does not guarantee a reciprocal order of creation of temporary variables, tmp1 and tmp2, i.e., first, tmp2 can be created, and then - tmp1; but this does not change the logic of our program.
Note that we did not refer to the fifth quotation of the standard, because it describes 3 cases where the time of removal of an object can differ from the one given, and, as we see, none of these cases can correspond to our case. The first two cases in the quotation of the standard are initialization or copying of the array, they shorten the lifetime of the temporary object, and the third case is extension of the temporary object lifetime due to the presence of its link.
Using the Code
Thread-Safe Associative Array
Agree, it would be convenient to have such a template class safe_ptr<>, to which you can pass any type, and, as a result, receive a thread-safe resulting type?
safe_ptr<std::map<std::string, std::pair<std::string, int> >> safe_map_strings;
Further, you can work with this object as with a pointer to the associative array:
std::shared_ptr<std::map<std::string, std::pair<std::string, int> >> shared_map_string;
But now, we can safely work with it from different threads, and every separate expression will be thread-safe:
(*safe_map_strings)["apple"].first = "fruit";
(*safe_map_strings)["potato"].first = "vegetable";
safe_map_strings->at("apple").second = safe_map_strings->at("apple").second * 2;
safe_map_strings->find("potato")->second.second++;
Let us see a case study of thread safe associative: std::map<>
[9] http://coliru.stacked-crooked.com/a/5def728917274b22
#include < iostream >
#include < string >
#include < vector >
#include < memory >
#include < mutex >
#include < thread >
#include < map >
template< typename T, typename mutex_t = std::recursive_mutex, typename x_lock_t =
std::unique_lock< mutex_t >, typename s_lock_t = std::unique_lock < mutex_t > >
class safe_ptr {
typedef mutex_t mtx_t;
const std::shared_ptr< T > ptr;
std::shared_ptr< mutex_t > mtx_ptr;
template< typename req_lock >
class auto_lock_t {
T * const ptr;
req_lock lock;
public:
auto_lock_t(auto_lock_t&& o) : ptr(std::move(o.ptr)), lock(std::move(o.lock)) { }
auto_lock_t(T * const _ptr, mutex_t& _mtx) : ptr(_ptr), lock(_mtx){}
T* operator -> () { return ptr; }
const T* operator -> () const { return ptr; }
};
template< typename req_lock >
class auto_lock_obj_t {
T * const ptr;
req_lock lock;
public:
auto_lock_obj_t(auto_lock_obj_t&& o) :
ptr(std::move(o.ptr)), lock(std::move(o.lock)) { }
auto_lock_obj_t(T * const _ptr, mutex_t& _mtx) : ptr(_ptr), lock(_mtx){}
template< typename arg_t >
auto operator [] (arg_t arg) -> decltype((*ptr)[arg]) { return (*ptr)[arg]; }
};
void lock() { mtx_ptr->lock(); }
void unlock() { mtx_ptr->unlock(); }
friend struct link_safe_ptrs;
template< typename mutex_type > friend class std::lock_guard;
public:
template< typename... Args >
safe_ptr(Args... args) : ptr(std::make_shared< T >(args...)),
mtx_ptr(std::make_shared< mutex_t >()) {}
auto_lock_t< x_lock_t > operator-> ()
{ return auto_lock_t< x_lock_t >(ptr.get(), *mtx_ptr); }
auto_lock_obj_t< x_lock_t > operator* ()
{ return auto_lock_obj_t< x_lock_t >(ptr.get(), *mtx_ptr); }
const auto_lock_t< s_lock_t > operator-> () const
{ return auto_lock_t< s_lock_t >(ptr.get(), *mtx_ptr); }
const auto_lock_obj_t< s_lock_t > operator* () const
{ return auto_lock_obj_t< s_lock_t >(ptr.get(), *mtx_ptr); }
};
safe_ptr< std::map< std::string, std::pair< std::string, int > > > safe_map_strings_global;
void func(decltype(safe_map_strings_global) safe_map_strings)
{
(*safe_map_strings)["apple"].first = "fruit";
(*safe_map_strings)["potato"].first = "vegetable";
for (size_t i = 0; i < 10000; ++i) {
safe_map_strings->at("apple").second++;
safe_map_strings->find("potato")->second.second++;
}
auto const readonly_safe_map_string = safe_map_strings;
std::cout << "potato is " << readonly_safe_map_string->at("potato").first <<
" " << readonly_safe_map_string->at("potato").second <<
", apple is " << readonly_safe_map_string->at("apple").first <<
" " << readonly_safe_map_string->at("apple").second << std::endl;
}
int main() {
std::vector< std::thread > vec_thread(10);
for (auto &i : vec_thread) i = std::move(std::thread(func, safe_map_strings_global));
for (auto &i : vec_thread) i.join();
std::cout << "end";
int b; std::cin >> b;
return 0;
}
Output:
Quote:
potato is vegetable 65042, apple is fruit 65043
potato is vegetable 81762, apple is fruit 81767
potato is vegetable 84716, apple is fruit 84720
potato is vegetable 86645, apple is fruit 86650
potato is vegetable 90288, apple is fruit 90291
potato is vegetable 93070, apple is fruit 93071
potato is vegetable 93810, apple is fruit 93811
potato is vegetable 95788, apple is fruit 95790
potato is vegetable 98951, apple is fruit 98952
potato is vegetable 100000, apple is fruit 100000
end
Thus, we have two conclusions:
- The resulting values of 100,000 mean that each addition in each of the 10 threads has been made in a thread-safe way. Indeed, it is enough to change our code so that
operator-> returns a pointer to the object itself instead of auto_lock_t and auto_lock_obj_t types, as we will see, what would happen if the code would NOT be a thread-safe one - data-race: [10] http://coliru.stacked-crooked.com/a/45d47bcb066adf2e - Intermediate values that are aliquant of 10,000 indicate that the threads were executed in parallel or in pseudo-parallel, i.e., they were interrupted in the middle of any of the operations and at that time another thread was being executed, i.e., before every
operator++ increment, the mutex was locked, and immediately after the increment it was unlocked, and then the mutex could be locked by another thread that performed the increment. We can immediately lock the mutex at the beginning of each thread until the end of execution of the thread function by using std::lock_guard<>, and we will see what would have happened, if the threads were executed sequentially, but not in pseudo-parallel: [11] http://coliru.stacked-crooked.com/a/cc252270fa9f7a78
Both conclusions confirm that our template of safe_ptr<T> clever pointer class automatically ensures the thread-safety of the protected object of type T.
Thread-Safety, Atomicity and Consistency of Several Objects
We’ll demonstrate how you can atomically change several objects at once, so that their consistency is preserved. And we will demonstrate, when it is necessary, how to do it and what happens if it is not done.
Let's give a simplified example, suppose we have two tables:
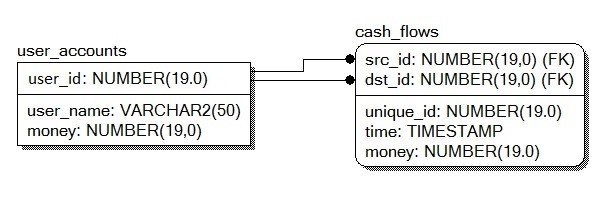
user_accounts(INT user_id, STRING user_name, INT money) - table with the amount of money for each client - sorted by user_id fieldcash_flows(INT unique_id, INT src_id, INT dst_id, INT time, INT money) – table showing the flow of money - each entry is referenced by two associative arrays, which are sorted: by field src_id and by field dst_id
struct user_accounts_t {
std::string user_name; int64_t money;
user_accounts_t(std::string u, int64_t m) : user_name(u), money(m) {}
};
std::map< uint64_t, user_accounts_t > user_accounts;
struct cash_flows_t { uint64_t unique_id, src_id, dst_id, time; int64_t money; };
std::atomic< uint64_t > global_unique_id; std::multimap< uint64_t, std::shared_ptr< cash_flows_t > > cash_flows_src_id;
std::multimap< uint64_t, std::shared_ptr< cash_flows_t > > cash_flows_dst_id;
In terms of RDBMS:
- 1-st table with
user_id field index - it is Index-Organized-Table (Oracle) or Table with Clustered Index (MS SQL). - 2-nd table - it is a table with two indexes organized by one
src_id field and by one dst_id field respectively.
In real tasks, a table can contain millions of entries for customers and billions of entries for monetary flows, in this case the indexes by fields (user_id, src_id, dst_id) speed up search by hundreds of thousands of times, so they are extremely necessary.
Let us suppose that requests to execute three tasks came from three users in three parallel threads:
move_money() - The thread transfers money from one client to another:
- It takes money from one client
- It adds the same amount of money to another client
id-source field index adds a pointer to a money entryid-destination field index adds a pointer to the same money entry (in real tasks this is not necessary, but we will do it as an example)
show_total_amount() - to show the amount of money of all clients:
- In the cycle, we go through each client and sum up all the money
show_user_money_on_time() - to show the amount of a client’s money with the specified user_id at time point:
incoming - sum up all the money that has come to the client from the time point and later (by using the id-source field index)outcoming - sum up all the money that has gone from the client from the time point and later (by using the id-destination field index)user_money - get the current money from the clientuser_ user_money - incoming + outcoming - this is the amount of a client’s money at the time point
We know that any of the threads can be interrupted by the operating system at any time, for example, in order to give the CPU-Core to another thread. The most dangerous thing is that this happens extremely rarely and maybe you will never face it during debugging, but one day, it will happen to a client. And if it leads to data-races, then money can simply disappear from the financial system.
Therefore, we deliberately add wait functions that will put the thread to sleep for a few milliseconds in the most critical places in order to immediately see the errors.
We will make our tables (user_accounts, cash_flows_src_id, cash_flows_dst_id) thread-safe by using safe_ptr<>, but will the entire program become thread-safe after that?
[12] http://coliru.stacked-crooked.com/a/5bbba59b63384a2b
Let's look at the «basic lines» in the output of the program, which are marked with <<<:
Quote:
Init table safe_user_accounts:
at time = 0 <<<
1 => John Smith, 100
2 => John Rambo, 150
- start transaction... show_total_amount()
1 => John Smith, 100
2 => John Rambo, 100
Result: all accounts total_amount = 200 <<<
- start transaction... show_user_money_on_time()
1 => John Smith, 150, at time = 0 <<<
Immediately, two errors are obvious:
- Initially, all (two) users had 250 money together, and the function
show_total_amount() showed only 200, the rest of money equal to 50 disappeared somewhere. - At the point of
time=0, user 1 had 100 money, but show_user_money_on_time() function showed wrong result – user 1 had 150 money at the point of time=0
The problem is that atomicity is observed only at the level of individual tables and indexes, but not in the aggregate, therefore, the consistency is violated. The solution is to lock all used tables and indexes for the duration of all operations that must be performed atomically - this will preserve consistency.
The added lines are highlighted in yellow. Diff:

Correct example: [13] http://coliru.stacked-crooked.com/a/c8bfc7f5372dfd0c
Let's look at the «basic lines» in the output of the program, which are marked with <<<:
Quote:
Init table safe_user_accounts:
at time = 0 <<<
1 => John Smith, 100
2 => John Rambo, 150
Result: all accounts total_amount = 250 <<<
1 => John Smith, 100, at time = 0 <<<
Now everything is correct, the amount of money of all clients is 250, and the amount of money of client 1 was 100 at the point of time 0.
That is to say, we could atomically perform operations not only with one object, but with 3 objects at a time, preserving the consistency of the data for any operations.
But here another problem is possible. If you (or another developer), in one of the functions, lock the mutexes of containers in a different order, then a situation called deadlock is possible - when 2 threads hang forever waiting for each other.
In the correct example above, we locked the mutexes in both functions - move_money() and show_user_money_on_time() - in the same order:
lock1(safe_user_accounts)lock2(safe_cash_flows_src_id)lock3(safe_cash_flows_dst_id)
And now let’s see what happens if we lock mutexes in containers in each function in a different order:
move_money()
lock2(safe_cash_flows_src_id)lock3(safe_cash_flows_dst_id)lock1(safe_user_accounts)
show_user_money_on_time()
lock3(safe_cash_flows_dst_id)lock2(safe_cash_flows_src_id)lock1(safe_user_accounts)
Function move_money() locked lock2 and waits until lock3 is freed to lock it. Function show_user_money_on_time() locked lock3 and waits until lock2 is freed to lock it. And they will wait for each other forever.
Example: [14] http://coliru.stacked-crooked.com/a/0ddcd1ebe2be410b
Example:
Quote:
Init table safe_user_accounts:
at time = 0 <<<
1 => John Smith, 100
2 => John Rambo, 150
- start transaction... move_money()
- start transaction... show_total_amount()
1 => John Smith, 100
2 => John Rambo, 150
That is to say, functions move_money() and show_user_money_on_time() were not completed and stopped in deadlock forever.
There are four solutions:
- All developers always lock mutexes in all functions in the same order and they are never wrong - this is a very unreliable assumption
- You initially combine all objects, which will be used atomically, in one structure and use a secure pointer with the type of this structure:
struct all_t { std::map<int,int> m1; std::multimap<int,int> m2; … }; safe_ptr<all_t> safe_all_obj; – but if you initially used these 2 containers only separate safe_ptr<map<int,int>> m1; safe_ptr<multimap<int,int>> m2; and you have already written a lot of code and after that you decide to combine them into one structure protected by a single mutex, then you will have to rewrite all the places where they are used, for example, instead of m2->at(5); you need to write safe_all_obj->m2.at(5); To rewrite a lot of code is not very convenient. - One time, you can combine
safe_ptr<> that are used together, to make them use the same recursive mutex, whereafter it will not matter in which order they are locked; consistency of these objects will always be preserved and will never be deadlock. To do this, you just need to add 1 line - it's very convenient. But this can reduce performance, because now locking of one of the containers always results in locking of all associated containers. You will get consistency even when it is not needed - at the cost of reducing performance. Example: [15] http://coliru.stacked-crooked.com/a/2a6f1535e0b95f7b
All the changes in the code are just one line:
static link_safe_ptrs tmp_link
(safe_user_accounts, safe_cash_flows_src_id, safe_cash_flows_dst_id);
Conclusion – basic lines are shown:
Quote:
Init table safe_user_accounts:
at time = 0 <<<
1 => John Smith, 100
2 => John Rambo, 150
Result: all accounts total_amount = 250 <<<
1 => John Smith, 100, at time = 0 <<<
- You can use the lock at a time for several mutexes of different types with the timeout setting to lock each mutex. And if you cannot lock at least one of the mutexes during this time, then all previously locked mutexes are unlocked, the thread waits for a while and tries to lock all the mutexes one by one again. For this purpose, it is enough to add one line before each using of containers:
lock_timed_any_infinity lock_all
(safe_cash_flows_src_id, safe_cash_flows_dst_id, safe_user_accounts);
and it doesn’t matter in which order you will lock the mutexes of containers. Example: [16] http://coliru.stacked-crooked.com/a/93206f216ba81dd6
That is, even if we lock the mutexes in different sequences:
Thus, with the help of locks, we solved the problem of composability, and absence of eternal deadlocks is guaranteed: https://en.wikipedia.org/wiki/Lock_(computer_science)#Lack_of_composability
You can get this example for Windows/Linux from the link at the top of the article.
Tested on:
- Windows x86_64 (MSVS 2013 and 2015)
- Linux x86_64 (g++ 6.3.0 and clang 3.8.0)
This code is in the online compiler: http://coliru.stacked-crooked.com/a/a97a84ff26c6e9ee
Using safe_ptr<> with rw-lock
To use safe pointer with rw-lock instead of unique-lock, just #include <safe_ptr.h> and write so shared_mutex_safe_ptr<std::map<int,int>>, instead of safe_ptr<std::map<int,int>>. Or better to write contfree_safe_ptr<std::map<int,int>> ptr; that uses much more faster shared-mutex - we describe it in the second article. Then using slock_safe_ptr(ptr)->find(5); or using auto const& ptr_read = ptr; ptr_read->find(5); will be called read-only shared-lock - we describe these ways in the third article.
Additional Background
Composability and Deadlocks
As we used locks for thread-safety above, our algorithms are called lock-based.
Is all really well in terms of absence of deadlocks in lock-free containers, algorithms based on Transactional Memory, and are there deadlocks in modern RDBMS: MSSQL (lock-based IL) and Oracle (multi-version concurrency control)?
Lock-free algorithms do not allow changing several containers atomically at a time. RDBMS have the same problems with deadlock as lock-based algorithms, and they often solve them either through locks timeouts or locks graphs. And a new transaction-safe section in C++ standard does not allow you to safely use complex algorithms, such as std::map<>.
Lock-free algorithms do not have the property of composable operations - joint atomic use of several lock-free algorithms. That is to say, several lock-free data structures cannot be changed or read at a time. For example, you can use lock-free containers of associative arrays from libCDS, and they will be individually thread-safe. But if you want to atomically perform operations with several lock-free containers at a time and maintain consistency, then you cannot do this because their API does not provide the functions of lock-free operations simultaneously on multiple containers. While you are changing or reading one container, another one will already be changed at that time. To avoid this, you will need to use locks, and in this case, it will be containers based on locks, which means that they will have all the problems of lock-based algorithms, namely the possibility of problem of deadlocks. In addition, locks are sometimes used in case of using only one container:
In transactional RDBMS, such as MSSQL (lock-based) and Oracle (multi-version concurrency control), locks are also used, and that is why there are problems with deadlocks, which, for example, can be solved automatically by building a locks graph and finding circular wait, or by setting the lock wait time select col from tbl where id in (....) for update wait 30; If the latent time has elapsed or a deadlock has been found in the locks graph, the rollback of one of the transactions occurs - that is to say, cancellation of all changes that have already been made by that transaction, unlock of all that was locked; and then you can try to execute the transaction from the very beginning (and so many times):
Oracle Database Online Documentation 11g Release 1 (11.1) - Deadlocks: https://docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#i5337
Oracle locks: https://docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#i5249
As you can see, exclusive incompatible locks are used by any expressions: Insert/Update/Delete/Select-For-Update
MSSQL Detecting and Ending Deadlocks: https://technet.microsoft.com/en-us/library/ms178104(v=sql.105).aspx
MS SQL locks: https://technet.microsoft.com/en-us/library/ms186396(v=sql.105).aspx
In turn, Transactional Memory, unlike Lock-free containers, can work atomically with a lot of containers/data. That is to say, Transactional Memory has the Composable operations feature. Inside, either pessimistic locks (with deadlock conflict probability) or optimistic locks are used (more likely conflicting modifications with competitive modifications). And in case of any conflicts, the transaction is automatically cancelled and repeated from the very beginning, which entails multiple repeating of all operations - and this causes heavy overhead costs. They are trying to reduce overhead costs by creating Hardware Transactional Memory at the CPU level, but so far there are no realizations showing acceptable performance, although Intel has already added Hardware Transactional Memory to the Haswell CPU. They also promise to include Transactional Memory in C++ standard, but only in the future, so far, it is only used as experimental one and without support for working with std::map. That is to say, so far, everything is good only in theory. But in the future, this is likely to replace the usual methods of synchronization.
Eventually
- Lock-based algorithms are not composed, if such an option is not provided upon their realization; but this option can be realized, and we successfully realized it in the previous sections.
- Lock-free algorithms are not composed, and their composing without locking is a very complicated task; but with locks, such an algorithm is no longer lock-free and there is a risk of eternal deadlocks.
- RDBMS: MSSQL (lock-based IL) and Oracle (MVCC) - there are possible deadlocks, which are removed through locks graphs or timeouts.
- Transactional memory from the experimental part of C++ standard has so far been limited to using only in the simplest algorithms and does not allow the use of algorithms, such as in
std::map<> methods, or more complicated.
Conclusion: The deadlock problem exists in all types of algorithms and systems that demonstrate high performance, where several data structures are invoked at a time. So we offered two options for its solving for safe_ptr<>.
static link_safe_ptrs tmp_link(safe_user_accounts, safe_cash_flows_src_id, safe_cash_flows_dst_id); - to use one mutex for several containerslock_timed_any_infinity lock_all(safe_cash_flows_src_id, safe_cash_flows_dst_id, safe_user_accounts); - to use locks timeouts; upon expiration of time, to unlock everything and try to lock it again
If only one container and one recursive mutex are used for safe_ptr<>, then deadlock in safe_ptr<> is impossible, as we need at least two recursive mutexes for deadlock (or 1 non-recursive).
Composability of Lock-based Algorithms
In general case, it is considered that the lock-based programs are not composable, i.e., if you simply take two lock-based data structures and atomically change them one by one, you will not get a consistent state at any point of time.
But above, we easily composed three lock-based containers. How did we do it? There is a small clarification in this respect - in bold type:
Perhaps the most fundamental objection [...] is that lock-based programs do not compose: correct fragments may fail when combined. For example, consider a hash table with thread-safe insert and delete operations. Now suppose that we want to delete one item A from table t1, and insert it into table t2; but the intermediate state (in which neither table contains the item) must not be visible to other threads. Unless the implementor of the hash table anticipates this need, there is simply no way to satisfy this requirement. [...] In short, operations that are individually correct (insert, delete) cannot be composed into larger correct operations.
—Tim Harris et al., "Composable Memory Transactions", Section 2: Background, pg.2
https://www.microsoft.com/en-us/research/wp-content/uploads/2005/01/2005-ppopp-composable.pdf
The fact is that the lock-based algorithms cannot be composed unless such a feature is provided upon their realization. That is to say, the lock-based data structures cannot be composed automatically, but they can be composed manually. For example, as we did with the help of lock_timed_any_infinity class, if outside there is an access to their mutex for composition operations.
We realized lock-based template class safe_ptr<T> and (for any T type in it), we made allowance for the necessity to be composed and to solve deadlocks with usage of composition operations: link_safe_ptrs, lock_timed_any_infinity, lock_timed_any_once.
So, why did we choose the locks and their pessimistic option?
- Locks are a standard mechanism for ensuring the thread-safe operating systems and C++ language
- By means of locks, we can realize the composability and consistency of multiple data structures
- Deadlock is possible in pessimistic locks, if you forgot to correctly compose the locks. It is difficult to find such a deadlock, but it is easy solved and occurs rarely. In optimistic locks, in any case, conflicting modifications are possible. They can be found easily, but they require additional C++ code to solve them and occur much more often.
- Tom Kyte is a Senior Technical Architect in Oracle’s Server Technology Division – he is a supporter of pessimistic locks in Oracle DB (Multi-Version Concurrency Control): https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:5771117722373 And what concerns the fact that pessimistic locks can cause situations of lockout and deadlock, he writes the following:
Quote:
I am a huge fan of so called pessimistic locking. The user has very clearly announced their intent to UPDATE THE DATA. The lockouts they refer to are easily handled with session timeouts (trivial) and the deadlock is so rare and would definitely be an application bug (in both Oracle and RDB).
- Deadlock is an error. If you think that it’s better to slow down a few threads rather than stop them completely while you fix your error, then use
lock_timed_any_infinity. Otherwise, if you want to permanently stop your program, then use: link_safe_ptrs and std::lock_guard<>. - There is also no need for automatic escalation of locks. For example, Oracle DB never does this: https://docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#CIHCFHGE
Oracle Database never escalates locks. Lock escalation greatly increases the likelihood of deadlocks.
We will continue to periodically refer to the wide experience of industrial RDBMS when implementing our algorithms in the following articles.
Conclusion
We proved the correctness of Execute Around Pointer Idiom for automatic provision of safe access from different threads - strictly corresponds to the C++ standard. We showed an example of its composability. And also we demonstrated the advantages of using pessimistic locking to ensure thread safety.
History
- 24th April, 2017 - Initial version
- 1st May, 2017 - Added link to GitHub
The author of the YOLOv7/YOLOv4 - the best neural network for object detection.
I use modern C++ and modern CPU/GPU processors to solve tasks that require high performance, which can only be solved now.
I'm interested in HPC, Computer Vision and Deep Learning.
Preferably languages: C++11/14, CUDA C++, Python, SQL


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





