









Researchers from Northeastern University, University of Massachusetts, Amherst and Czech Technical University in Prague, published a paper on the Impact of Programming Languages on Code Quality which is a reproduction of work by Ray et al published in 2014 at the Foundations of Software Engineering (FSE) conference. This work claims to reveal an association between 11 programming languages and software defects in projects that are hosted on GitHub.
The original paper by Ray et al was well-regarded in the software engineering community because it was nominated as the Communication of the ACM (CACM) research highlight.
And the above mentioned researchers conducted a study to validate the claims from the original work. They used the experimental repetition method, which was partially successful and found out that association of 10 programming languages with defects is true. Then they conducted an independent reanalysis which revealed a number of flaws in the original study. And finally the results suggested that only four languages are significantly associated with the defects, and the effect size (correlation between two variables) for them is extremely small.
Let us take a look at all the 3 researches in brief:
2014 FSE paper: Does programming language choice affect software quality?
The question that arises from the study by Ray et al. published at the 2014 Foundations of Software Engineering (FSE) conference is, What is the effect of programming language on software quality? The results reported in the FSE paper and later repeated in the followup works are based on an observational study of a corpus of 729 GitHub projects that are written in 17 programming languages. For measuring the quality of code, the authors have identified, annotated, and tallied commits that are supposed to indicate bug fixes.
Then the authors fitted a Negative Binomial regression against the labeled data for answering the following research questions:
RQ1 Are some languages more defect prone than others?
The original paper concluded that “Some languages have a greater association with defects than others, although the effect is small.” The conclusion was that Haskell, Clojure, TypeScript, Scala and Ruby were less error-prone whereas C, JavaScript, C++, Objective-C, PHP, and Python were more error-prone.
RQ2 Which language properties relate to defects?
The original study concluded that “There is a small but significant relationship between language class and defects. Functional languages have a smaller relationship to defects than either procedural or scripting languages.” It could be concluded that functional and strongly typed languages showed fewer errors, whereas the procedural, unmanaged languages and weakly typed induced more errors.
RQ3 Does language defect proneness depend on domain?
A mix of automatic and manual methods has been used for classifying projects into six application domains. The paper concluded that “There is no general relationship between domain and language defect proneness”. It can be noted that the variation in defect proneness comes from the languages themselves which makes the domain a less indicative factor.
RQ4 What’s the relation between language & bug category?
The study concluded that “Defect types are strongly associated with languages. Some defect type like memory error, concurrency errors also depend on language primitives. Language matters more for specific categories than it does for defects overall.”
It can be concluded that for memory, languages with manual memory management have more errors. Also, Java stands out as the only garbage collecting language that is associated with more memory errors. Whereas for concurrency, Python, JavaScript, etc have fewer errors than languages with concurrency primitives.
Experimental repetition method performed to obtain similar results from the original study
The original study used methods of data acquisition, data cleaning, and statistical modeling. The researchers then planned for experimental repetition. Their first objective was to repeat the analyses of the FSE paper and obtain the same results. They used an artifact coming from the original authors that had 3.45 GB of processed data and 696 lines of R code for loading the data and performing statistical modeling.
According to a repetition process, a script generates results and match the results in the published paper. The researchers wrote new R scripts for mimicking all of the steps from the original manuscript. They then found out that it is essential to automate the production of all tables, numbers, and graphs to iterate multiple times.
Researchers concluded that the repetition was partly successful and according to them:
- RQ1 produced small differences but had qualitatively similar conclusions. The researchers were mostly able to replicate RQ1 based on the artifact provided by the authors. The researchers found 10 languages with a statistically significant association with errors, instead of the eleven reported
- RQ2 could have been repeated but they noted issues with language classification.
- They noted that RQ3 could not be repeated as the code was missing and also because their reverse engineering attempts failed.
- RQ4 could not be repeated because of irreconcilable differences in the data. Another reason was that the artifact didn’t contain the code which implemented the NBR for bug types.
The Reanalysis method confirms flaws in the FSE study
Their second objective was to carry out a reanalysis of RQ1 of the FSE paper. i.e., Whether some languages are more defect prone than others? The reanalysis differs from repetition as it proposes alternative data processing and statistical analyses for addressing methodological weaknesses of the original work. The researchers then used methods such as data processing, data cleaning, statistical modeling.
According to the researchers, the p-values for Objective-C, JavaScript, C, TypeScript, PHP, and Python fall outside of the “significant” range of values. Thus, 6 of the original 11 claims have been discarded at this stage. Controlling the FDR increased the p-values slightly, but did not invalidate additional claims. The p-value for one additional language, Ruby, lost its significance and even Scala is out of the statistically significant set.
And a smaller p-value (≤ 0.05) indicates stronger evidence against the null hypothesis, so the null hypothesis can be rejected in that case. In the table below, grey cells are indicating disagreement with the conclusion of the original work and which include, C, Objective-C, JavaScript, TypeScript, PHP, and Python. So, the reanalysis has failed to validate most of the claims and the multiple steps of data cleaning and improved statistical modeling have also invalidated the significance of 7 out of 11 languages.
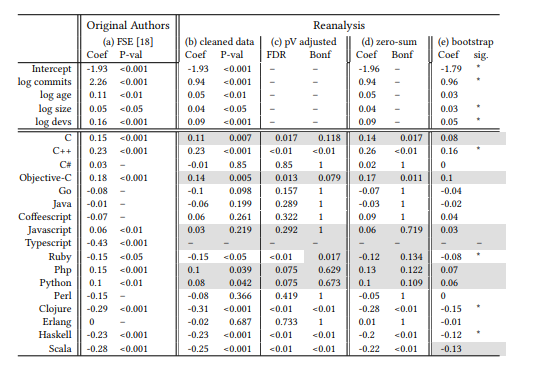 Image source: Impact of Programming Languages on Code Quality
Image source: Impact of Programming Languages on Code Quality
The researchers conclude that the work by the Ray et al. has aimed to provide evidence for one of the fundamental assumptions in programming language research, that is language design matters. But the researchers have identified numerous problems in the FSE study that has invalidated its key result.
The paper reads, “Our intent is not to blame, performing statistical analysis of programming languages based on large-scale code repositories is hard. We spent over 6 months simply to recreate and validate each step of the original paper.”
The researchers’ contribution provides thorough analysis and discussion of the downfalls associated with statistical analysis of large code bases. According to them, statistical analysis combined with large data corpora is a powerful tool that might even answer the hardest research questions but the possibility of errors—is enormous.
The researchers further state that “It is only through careful re-validation of such studies that the broader community may gain trust in these results and get better insight into the problems and solutions associated with such studies.”
Check out the paper On the Impact of Programming Languages on Code Quality for more in-depth analysis.
Read Next
Samsung AI lab researchers present a system that can animate heads with one-shot learning


