Theoretical Background
(from
Unbounded length contexts for PPM
by
John G. Cleary, W. J. Teahan, Ian H. Witten
Prediction by partial matching, or PPM, is a finitecontext statistical modeling
technique that can be viewed as blending together several fixedorder context models to predict
the next character in the input sequence. Prediction probabilities for each context in the
model are calculated from frequency counts which are updated adaptively; and the symbol
that actually occurs is encoded relative to its predicted distribution using arithmetic coding.
The maximum context length is a fixed constant, and it has been found that increasing
it beyond about six or so does not generally improve compression.
The basic idea of PPM is to use the last few characters in the input stream to predict the
upcoming one. Models that condition their predictions on a few immediately preceding
symbols are called finitecontext models of order k, where k is the number of preceding
symbols used. PPM employs a suite of fixedorder context models with different values of
k, from 0 up to some predetermined maximum, to predict upcoming characters.
For each model, a note is kept of all characters that have followed every lengthk
subsequence observed so far in the input, and the number of times that each has occurred.
Prediction probabilities are calculated from these counts. The probabilities associated with
each character that has followed the last k characters in the past are used to predict the
upcoming character. Thus from each model, a separate predicted probability distribution
is obtained.
These distributions are effectively combined into a single one, and arithmetic coding
is used to encode the character that actually occurs, relative to that distribution.
The combination is achieved through the use of escape probabilities. Recall that each model
has a different value of k. The model with the largest k is, by default, the one used for
coding. However, if a novel character is encountered in this context, which means that the
context cannot be used for encoding it, an escape symbol is transmitted to signal the
decoder to switch to the model with the next smaller value of k. The process continues until
a model is reached in which the character is not novel, at which point it is encoded with
respect to the distribution predicted by that model. To ensure that the process terminates,
a model is assumed to be present below the lowest level, containing all characters in the
coding alphabet. This mechanism effectively blends the different order models together in
a proportion that depends on the values actually used for escape probabilities.
PPMD_Coder
PPMD_Coder is based on PPMD var E by Dmitri Shkarin. You can
download the original code here.
I have created a static library around it and an easy to use wrapper class. The constructor
expects 4 parameters:
- The name of the Input file
- The name of the Output file. If empty or NULL and you
Compress a file
the extension ".ppm" will be added, if you Uncompress a file the name stored in the compressed
file will be used. - The memory in MBytes (between 1 and 256) which can be used by the program.
It will be dynamically allocated on the heap so don't use
unrealistic values. After compression you can look at the statistic to see how much memory was used. It's a
good idea to keep the value as low as possible because for decompression the same amount of memory must
be allocated or decompression will fail.
- The Order size (between 2 and 16).
A value of 6 is a good starting point but it's worth trying out higher values.
The memory and order size can also be set later with OrderSize and SubAllocatorSize.
Values which are out of range are adjusted, the return value is the size actually set.
They have only impact on the compression.
Now you can decide what to do: call Compress or Uncompress. Both throw an exception
when an error occurs. Additionally they return TRUE on success or FALSE. Here is an example:
#include "ppmd_coder.h"
...
PPMD_Coder ppmd(szInput);
try
{
ppmd.Compress();
DWORD m1, m2;
ppmd.GetMemoryUsage(m1, m2);
TRACE(_T("Memory used: %i.%i MBytes\n"), m1, m2);
TRACE(_T("Compression ratio: %2.2f\n"), ppmd.GetRatio());
}
catch (exception &e)
{
AfxMessageBox(e.what());
}
Easy, isn't it? Decompression works the same way only that you call ppmd.Uncompress() instead of
Compress() and you must used ppmd.GetRatioUncompressed() to get the right ratio.
Final words
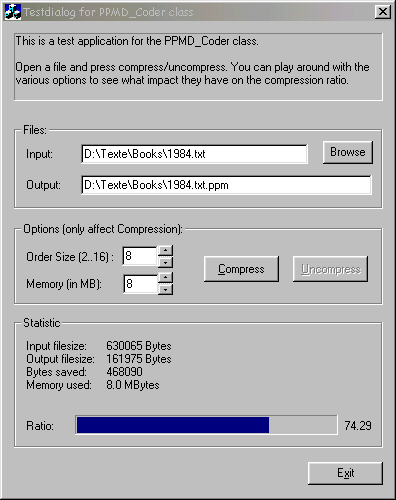
Please have a look at the demo application. It's very simple but allows you to test the class.
With little effort it's possible to support the compression of several files into one archive, check the orginal
code for an example. Some special care must be taken so I advise you to study the code carefully before you do
anything.
Compare the compressed file with other programs (BZip, GZip, Rar, Ace, ...) and you will be surprised how well
the algorithm works. And it's not too slow! The static library could be changed to support some kind of
callback to see how much of the file has been processed yet. Maybe in another version...
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 








 I analized source and i don't know - how it "found" end of compressed data block?
I analized source and i don't know - how it "found" end of compressed data block? 
