Introduction
While .NET provides a BinaryReader and BinaryWriter, these classes are insufficient to handle structures and nullable value types. Conversely, the BinaryFormatter is an unwieldy and bloated solution. What is needed is something that produces a compact serialized data stream while also supporting nullable data values, both in the classic C# 1.0 sense (boxed value types) and in the nullable value type C# 2.0 sense. Also, the whole issue of null vs. DBNull.Value, which nullable types in C# 2.0 still don't address:
DateTime? dt = null;
dt = DBNull.Value;
needs to be dealt with (meaning, the serializer needs to preserve whether the boxed value type is null or DBNull.Value).
So, this is what the raw serializer/deserializer does. It is a replacement for the BinaryFormatter when you are serializing (possibly nullable) value types into a known format, and deserializing those values with the same format.
The Problem: The Binary Formatter
The BinaryFormatter is a horribly inefficient beast for transmitting data. It creates a large "binary" file and it sucks up huge amounts of memory because it isn't a stream, and it can crash your application. For example, a typical use is to package up the contents of a DataTable:
DataTable dt=LoadDataTable();
BinaryFormatter bf=new BinaryFormatter();
FileStream fs=new FileStream(filename, FileMode.Create);
bf.Serialize(fs, dt);
fs.Close();
- I tried this with a table consisting of some 200,000 records and the
BinaryFormatter crashed with an "out of memory" exception.
- I tried this with a smaller table and discovered that the resulting binary file was 10 times larger than the estimated data size.
- During formatting, it sucks up a lot of memory, making the usability of this class problematic in the real world when you don't know what sort of physical memory the system might have.
- Even though the
BinaryFormatter takes an output stream, it clearly does not stream the data until the stream is closed.
These problems were cause for concern, so I decided to look at a more lean implementation, and one that was not susceptible to crashing and consuming huge amounts of memory.
An Overview Of The Raw Serializer
Some articles are harder to figure out how to start than others. This is one in which I've waffled a lot. In the initial version, I spent about half the article talking about why I wrote a raw serialization class. Ultimately, I decided that the discussion was too much. Then, in writing the article, I realized I wasn't handling the reader and writer portions of the code symmetrically--the writer was using a dictionary to look up the writer method while the reader implemented a switch statement. Hmmm. I also realized that the implementation boxed the value types for writing, and required unboxing on the part of the caller for reading. This functionality is necessary for serializing a DataTable, but it's a performance hit if you're serializing known types. Given that the primary purpose of these classes (for me, at least) is to serialize/deserialize a DataTable efficiently, I considered leaving this implementation decision alone, but then decided it wouldn't necessarily be what other people needed, so I decided to add the methods necessary to avoid boxing/unboxing. Finally, I realized I needed to explore and understand C# 2.0's nullable types and how they should be supported.
When all is said and done, I figured a diagram of the various code paths (starting with the green boxes) would be a good start to helping the reader understand what is going on:
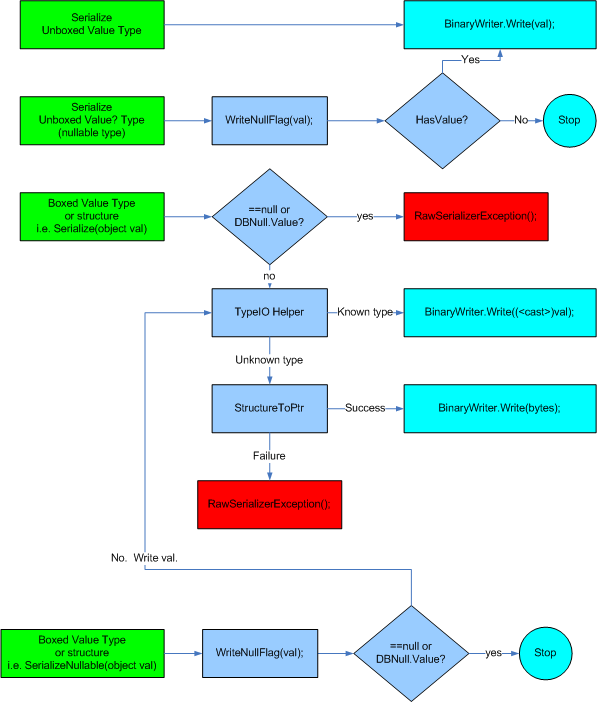
You may ask yourself, why not just expose the BinaryReader/Writer so that the caller can use the appropriate Read/Write methods directly when nullable support isn't required? This question has some merit as the current implementation introduces what might be considered to be an unnecessary method call. However, the point of encapsulation is to allow the interface, in this case the RawSerializer class, to vary without affecting the caller. If, in the future, I want to use some stream other than the BinaryReader/Writer, or add additional functionality to the read/write methods, I can do so safely, knowing that the encapsulation of the BinaryReader/Writer isn't broken.
So, the end result is hopefully a better, more complete implementation. I must say, writing an article describing one's code is a really powerful code review technique!
Raw Serializer
The following describes what the raw serializer generally can handle, and caveats you should be aware of when using it.
Value Types, Structures, And Nullable Values
These classes serialize and deserialize native value types, including compliant structures (structures consisting of native types and which the marshaller can determine the size of) directly to binary values. The RawSerializer class, and its complement, the RawDeserializer, are not themselves streams, however they encapsulate the BinaryWriter and BinaryReader classes, which are streams, and thus allow the raw serializer to work with stream contexts.
Because the serializer supports only value types, it is not a general purpose serialization engine like the BinaryFormatter. However, in cases where all you are serializing is value types, then this set of classes will generate a much more efficient output because it writes only the raw binary data.
The class supports serialization of DateTime? and Guid? nullable value types directly. Other nullable structures will go through the boxing mechanism and require you to explicitly use the SerializeNullable(...) method. For deserialization, you have to explicitly state the appropriate deserialization method, such as int? DeserializeNInt() as opposed to int DeserializeInt(). Other nullable structures need to use the object DeserializeNullable(Type t) method and explicitly unbox the return value.
Version Information
Unlike the BinaryFormatter, there is no version management to ensure that the deserializer matches the format of the serialized data. You can certainly add version information, but be aware that this is a very dumb, low-level set of functions--it expects the deserializer to know the correct value types and whether they are nullable or not, and in the right order. If you get the order wrong or type mismatches, the deserializer will generate erroneous data and most likely will blow up trying to decode the input stream. Again, type information could have been added--in fact, the standard value types could be encoded along with the null flag byte, but I chose not to do that specifically to reduce the resulting data set size. If you feel you want that added layer of protection, feel free to add it in.
Null Support
The serializer supports both null and DBNull.Value values, however, these are optional. If you need to support null values, an extra byte is added to the value, which is used to indicate whether the value is null or DBNull.Value. Clearly, the deserializer also needs to specify whether it is expecting null values--the serialization and deserialization must always be synchronized with regards to both value types and nullability (there's a new word!).
One optimization I was considering, but chose not to implement, was a bit field header for each row in the DataTable, in which the bit fields would indicate whether their associated fields were null or not. This would save, for example, four bytes for every eight fields (2 bits being required to manage "not null", "null", or "DBNull.Value"). Not that great of a savings, especially if you opt to use the remaining 6 bits per field to describe an encoded field type as discussed above. So, I opted for the simple solution rather than programming myself (and you) into a corner.
Understanding The Difference Between A Boxed Value Type And A Nullable Value Type
The salient difference between a boxed value type (object foo) and a nullable value type (int? foo) is that the boxed value type supports null and DBNull.Value "values", whereas the nullable value type only supports null. The boxed value type serialization is useful when serializing data that has originated from a database and therefore may have DBNull.Value values.
Example Usage
Before getting into the code, I'm going to illustrate using these classes via some unit tests (the code has comprehensive unit tests, for the examples here, I'm looking picking specific ones). These unit tests are written using my AUT engine. This will give you a sense of what you can accomplish with the serializer. Each test has a setup routine that initializes the serializer, the deserializer, and a memory stream:
[TestFixture]
public class ValueTypeTests
{
MemoryStream ms;
RawSerializer rs;
RawDeserializer rd;
[SetUp]
public void Setup()
{
ms = new MemoryStream();
rs = new RawSerializer(ms);
rd = new RawDeserializer(ms);
}
...
}
Simple Value Type Serialization
[Test]
public void Int()
{
int val=int.MaxValue;
rs.Serialize(val);
rs.Flush();
ms.Position=0;
val=rd.DeserializeInt();
Assertion.Assert(val==int.MaxValue, "int failed");
}
This first test illustrates a straightforward serialization of an integer. As expected, the memory stream length is four bytes.
Boxed Serialization
[Test]
public void Int()
{
int val = int.MaxValue;
rs.Serialize((object)val);
rs.Flush();
ms.Position = 0;
val = rd.DeserializeInt();
Assertion.Assert(val == int.MaxValue, "int failed");
}
In this test, we're serializing a boxed value and deserializing it knowing the desired type. This test exercises a different pathway through the serializer. It also is a segue to the next test. Again, the memory stream length is 4 bytes.
Boxed Nullable Value Types
[Test]
public void BoxedNullable()
{
object anInt = 5;
object aNullInt = null;
rs.SerializeNullable(anInt);
rs.SerializeNullable(aNullInt);
rs.Flush();
ms.Position = 0;
anInt = rd.DeserializeNullable(typeof(int));
aNullInt = rd.DeserializeNullable(typeof(int));
Assertion.Assert((int)anInt == 5, "non-null nullable failed.");
Assertion.Assert(aNullInt == null, "null nullable failed.");
}
In this test, two boxed ints are serialized, the first with a value and the second assigned to null. The SerializeNullable method is used to tell the serializer that the value type is potentially null. After serialization, the memory stream length is 6 bytes. Why? The first value is serialized with a flag byte, thus taking 5 bytes. The second value, being null, simply gets the flag byte.
Nullable Value Types
[Test]
public void Int()
{
int? val1=int.MaxValue;
int? val2=null;
rs.Serialize(val1);
rs.Serialize(val2);
rs.Flush();
ms.Position=0;
val1=rd.DeserializeNInt();
val2=rd.DeserializeNInt();
Assertion.Assert(val1==int.MaxValue, "non-null nullable int failed");
Assertion.Assert(val2==null, "null nullable int failed");
}
Here, we're using the new nullable value type supported in C# 2.0. The resulting memory stream length is also 6 bytes. Notice the different deserialization method being used to return the appropriate nullable value type. You could also deserialize this into an object of type int:
[Test]
public void IntObject()
{
int? val1 = int.MaxValue;
int? val2 = null;
rs.Serialize(val1);
rs.Serialize(val2);
rs.Flush();
ms.Position = 0;
object obj1 = rd.DeserializeNullable(typeof(int));
object obj2 = rd.DeserializeNullable(typeof(int));
Assertion.Assert((int)val1 == int.MaxValue, "non-null nullable int failed");
Assertion.Assert(val2 == null, "null nullable int failed");
}
Data Tables
The following unit test demonstrates how a DataTable might be serialized. I have intentionally not included this code in the raw serializer class, as the method for serializing a DataTable will probably be application specific.
The Test Data
The test fixture's DataTable is initialized with the following data:
[TestFixtureSetUp]
public void FixtureSetup()
{
dt = new DataTable();
dt.Columns.Add(new DataColumn("pk", typeof(Guid)));
dt.Columns.Add(new DataColumn("LastName", typeof(string)));
dt.Columns.Add(new DataColumn("FirstName", typeof(string)));
dt.Columns.Add(new DataColumn("MiddleInitial", typeof(char)));
dt.Columns["pk"].AllowDBNull = false;
dt.Columns["LastName"].AllowDBNull = false;
dt.Columns["FirstName"].AllowDBNull = false;
dt.Columns["MiddleInitial"].AllowDBNull = true;
DataRow dr=dt.NewRow();
dr["pk"]=Guid.NewGuid();
dr["LastName"]="Clifton";
dr["FirstName"]="Marc";
dr["MiddleInitial"] = DBNull.Value;
dt.Rows.Add(dr);
dr=dt.NewRow();
dr["pk"]=Guid.NewGuid();
dr["LastName"]="Clifton";
dr["FirstName"]="Ian";
dr["MiddleInitial"] = DBNull.Value;
dt.Rows.Add(dr);
dr=dt.NewRow();
dr["pk"]=Guid.NewGuid();
dr["LastName"]="Linder";
dr["FirstName"]="Karen";
dr["MiddleInitial"] = 'J';
dt.Rows.Add(dr);
dt.AcceptChanges();
}
Serializing And Deserializing The DataTable
The following is the unit test that validates the serialization of the data table. Note how the AllowDBNull property is being used to determine whether the object being serialized should allow for nulls. You'll also see that I'm serializing the table name, the number of columns and rows, and also the column name and type. This information comprises the header for the actual table data. Also note that the assembly qualified name is being used. In this example, it means that you would need the same version of .NET on the receiving end as was used to serialize the data. By using just the name, one could have one version of .NET serializing the data and another deserializing it. It's up to you and what you're trying to achieve, which is again why this code isn't part of the raw serialization classes in the download.
[Test]
public void DataTable()
{
rs.Serialize(dt.TableName);
rs.Serialize(dt.Columns.Count);
rs.Serialize(dt.Rows.Count);
foreach (DataColumn dc in dt.Columns)
{
rs.Serialize(dc.ColumnName);
rs.Serialize(dc.AllowDBNull);
rs.Serialize(dc.DataType.AssemblyQualifiedName);
}
foreach (DataRow dr in dt.Rows)
{
foreach (DataColumn dc in dt.Columns)
{
if (dc.AllowDBNull)
{
rs.SerializeNullable(dr[dc]);
}
else
{
rs.Serialize(dr[dc]);
}
}
}
rs.Flush();
ms.Position = 0;
string tableName = rd.DeserializeString();
int columns = rd.DeserializeInt();
int rows = rd.DeserializeInt();
Assertion.Assert(columns == 4, "Column count is wrong.");
Assertion.Assert(rows == 3, "Row count is wrong.");
DataTable dtIn = new DataTable();
for (int x = 0; x < columns; x++)
{
string columnName = rd.DeserializeString();
bool allowNulls = rd.DeserializeBool();
string type = rd.DeserializeString();
DataColumn dc = new DataColumn(columnName, Type.GetType(type));
dc.AllowDBNull = allowNulls;
dtIn.Columns.Add(dc);
}
for (int y = 0; y < rows; y++)
{
DataRow dr = dtIn.NewRow();
for (int x = 0; x < columns; x++)
{
DataColumn dc=dtIn.Columns[x];
object obj;
if (dc.AllowDBNull)
{
obj = rd.DeserializeNullable(dc.DataType);
}
else
{
obj = rd.Deserialize(dc.DataType);
}
dr[dc] = obj;
}
dtIn.Rows.Add(dr);
}
for (int y = 0; y < rows; y++)
{
for (int x = 0; x < columns; x++)
{
Assertion.Assert(dt.Rows[y][x].Equals(dtIn.Rows[y][x]),
"Deserialized data does not match serialized data");
}
}
}
Encryption Streaming
If you want to tack encryption onto the serialization stream, here's an example of how that works:
[Test]
public void EncryptionStreaming()
{
MemoryStream ms = new MemoryStream();
EncryptTransformer et = new EncryptTransformer(EncryptionAlgorithm.Des);
ICryptoTransform ict = et.GetCryptoServiceProvider(null);
CryptoStream encStream = new CryptoStream(ms, ict, CryptoStreamMode.Write);
RawSerializer rs=new RawSerializer(encStream);
rs.Serialize("Hello World");
((CryptoStream)encStream).FlushFinalBlock();
ms.Position=0;
DecryptTransformer dt = new DecryptTransformer(EncryptionAlgorithm.Des);
dt.IV = et.IV;
ict = dt.GetCryptoServiceProvider(et.Key);
CryptoStream decStream = new CryptoStream(ms, ict, CryptoStreamMode.Read);
RawDeserializer rd=new RawDeserializer(decStream);
string str=(string)rd.Deserialize(typeof(string));
Assertion.Assert(str=="Hello World", "Unexpected return.");
}
Compression Streaming
Or, let's say you want the stream compressed. This example utilizes the compression stream in the .NET 2.0 framework.
[Test]
public void CompressionStreaming()
{
MemoryStream ms=new MemoryStream();
GZipStream comp = new GZipStream(ms, CompressionMode.Compress, true);
RawSerializer rs=new RawSerializer(comp);
rs.Serialize("Hello World");
comp.Close();
ms.Position=0;
GZipStream decomp = new GZipStream(ms, CompressionMode.Decompress);
RawDeserializer rd=new RawDeserializer(decomp);
string str=(string)rd.Deserialize(typeof(string));
Assertion.Assert(str=="Hello World", "Unexpected return.");
}
Compression-Encryption Streaming
And of course, you might want to compress and encrypt your data stream.
[Test]
public void CompressionEncryptionStreaming()
{
MemoryStream ms=new MemoryStream();
EncryptTransformer et = new EncryptTransformer(EncryptionAlgorithm.Des);
ICryptoTransform ict = et.GetCryptoServiceProvider(null);
CryptoStream encStream = new CryptoStream(ms, ict, CryptoStreamMode.Write);
GZipStream comp = new GZipStream(encStream, CompressionMode.Compress, true);
RawSerializer rs = new RawSerializer(comp);
rs.Serialize("Hello World");
comp.Close();
((CryptoStream)encStream).FlushFinalBlock();
ms.Position=0;
DecryptTransformer dt = new DecryptTransformer(EncryptionAlgorithm.Des);
dt.IV = et.IV;
ict = dt.GetCryptoServiceProvider(et.Key);
CryptoStream decStream = new CryptoStream(ms, ict, CryptoStreamMode.Read);
GZipStream decomp = new GZipStream(decStream, CompressionMode.Decompress);
RawDeserializer rd = new RawDeserializer(decomp);
string str=(string)rd.Deserialize(typeof(string));
Assertion.Assert(str=="Hello World", "Unexpected return.");
}
Appendix
Rather than cluttering the beginning of the article with the nuts and bolts and other issues, I decided to put some of that here, in the Appendix:
The Wrong Tool
The BinaryFormatter is simply the wrong tool to use for my client's needs. Here's what MSDN says about it:
The SoapFormatter and BinaryFormatter classes implement the IRemotingFormatter interface to support remote procedure calls (RPCs), and the IFormatter interface (inherited by the IRemotingFormatter) to support serialization of a graph of objects. The SoapFormatter class also supports RPCs with ISoapMessage objects, without using the IRemotingFormatter functionality.
First, we don't need to support remote procedure calls. Second, we don't need the full support of object graph serialization. For example, in our application, the DataTable representing the cached data can be transmitted to the client without any header information at all because there is a separate data dictionary that defines the table columns and flags. (In the code presented here for serializing a DataTable, I do have a header block.)
Before looking at the complexities of serializing a DataTable, let's look at a very simple example--serializing a bool:
using System;
using System.Runtime.Serialization.Formatters.Binary;
using System.IO;
using System.Text;
namespace BinaryFormatterTests
{
class Program
{
static void Main(string[] args)
{
MemoryStream ms = new MemoryStream();
BinaryFormatter bf = new BinaryFormatter();
bool flag = false;
bf.Serialize(ms, flag);
byte[] data = ms.ToArray();
Console.WriteLine("Done.");
}
}
}
This generates 53 bytes:

Where in this is the bool? It turns out it's in the second to the last byte. If set to true, the last three bytes read: 01 01 0b.
What if we add a second bool? How much of this is initial header vs. actual data? Well, it turns out, nothing is initial header. If we serialize a second bool (just add bf.Serailize(ms, flag); twice), the resulting memory stream is now twice as large: 106 bytes!
It gets worse. Let's look at a DataTable now. An empty DataTable takes an initial 1051 bytes to serialize. Adding three column definitions (a GUID and two strings) takes an additional 572 bytes. Each additional row (no data in the strings) takes an additional 85 bytes (for an empty GUID and two empty strings!). And heaven help you if you actually have data in these rows:
static void Main(string[] args)
{
StringBuilder sb=new StringBuilder();
StringWriter sw=new StringWriter(sb);
XmlSerializer xs = new XmlSerializer(typeof(DataTable));
DataTable dt = new DataTable("Foobar");
DataColumn dc1 = new DataColumn("ID", typeof(Guid));
DataColumn dc2 = new DataColumn("FirstName", typeof(string));
DataColumn dc3 = new DataColumn("LastName", typeof(string));
dt.Columns.Add(dc1);
dt.Columns.Add(dc2);
dt.Columns.Add(dc3);
DataRow dr = dt.NewRow();
dr["ID"] = Guid.NewGuid();
dr["FirstName"] = "Marc";
dr["LastName"] = "Clifton";
dt.Rows.Add(dr);
dr = dt.NewRow();
dr["ID"] = Guid.NewGuid();
dr["FirstName"] = "Karen";
dr["LastName"] = "Linder";
dt.Rows.Add(dr);
xs.Serialize(sw, dt);
string str = sb.ToString();
Console.WindowWidth = 100;
Console.WriteLine(str.Length);
Console.WriteLine(str);
}
Adding GUIDs and "Marc", "Clifton" and "Karen", "Linder" to the two rows, the serialized output grows to a whopping 1982 bytes, adding 274 bytes to represent two rows of data that, if ideally stored, shouldn't take up more than 40 bytes or so (60, if you want to use Unicode to represent the strings).
Why Not Use Xml Serialization?
The resulting XML data for my two record example is actually smaller, 1671 bytes, and of course, compresses well because of its high tokenization rate.
But, let's look at a problem with how XML handles null values. Say some of these rows have null values. We're going to look at both DBNull.Value and simply setting the field to null:
DataRow dr = dt.NewRow();
dr["ID"] = Guid.NewGuid();
dr["FirstName"] = "Marc";
dr["LastName"] = DBNull.Value;
dt.Rows.Add(dr);
dr = dt.NewRow();
dr["ID"] = Guid.NewGuid();
dr["FirstName"] = "Karen";
dr["LastName"] = null;
dt.Rows.Add(dr);
The resulting output is:
Hmmm. LastName is completely missing. Now, what happens when we deserialize this into a new DataTable? The result is that the LastName field of both rows is set to type DBNull. While this is appropriate in the context of serializing a database table, it may not be what you want or expect in other contexts! If you test null == DBNull.Value, the result is false! (In fact, the complexity of null, DBNull, and empty strings within the context of control property values, like a TextBox.Text property, and binding these properties directly to DataTable fields, is another article in itself.)
This problem is more insidious than you might think. Take for example this class:
public class Test
{
protected string str=String.Empty;
public string Str
{
get { return str; }
set { str = value; }
}
}
Here, the programmer has initialized "str". However, if "str" is set to null at some point and then serialized, the property is not emitted. On deserialization, "str" is not assigned, and therefore keeps its initial value--in this case, an empty string. Again, not what you might be expecting, and definitely not something that's so obvious you'd think about it as a possible problem.
So, XML serialization is not symmetric because it doesn't handle null references. Depending on your needs, you may find this to be an issue. More importantly though, XML serialization still results in a large file requiring a compression post-process.
Compression vs. Expansion
While I'm on the subject, let me give you some benchmarks: using #ziplib: a 27 MB file takes 33 seconds to compress down to 5.1 MB on my test machine. Clicking "Send To compressed (zipped) folder" on XP, it takes 3 seconds to create a 5.6 MB compressed file. Needless to say, #ziplib isn't very optimized. Nor is compression all that valuable with the typically small datasets that we are working with, especially when looking at the serialization of data packets being sent over a network. However, the expansion of the data resulting from the BinaryFormatter is simply unacceptable. If we use compression, it's because we want to compress that data itself. If we look at XML serialization, we immediately think "oh, that will compress really well", but that is basically wrong thinking because what we're identifying as compressible information is primarily the metadata! The point of raw serialization is to get rid of the metadata!
The Importance Of AcceptChanges
You'll note in the first XML screenshot above, the "hasChanges" attribute. This brings up an important point--make sure you call AcceptChanges on the DataTable before you serialize it, otherwise you get these diffgram entries, which is probably not what you want. By calling AcceptChanges in the BinaryFormatter test above, I save 60 bytes.
Acknowledgements
I would like to thank Justin Dunlap for his help in pointing me in the right direction with regards to the BinaryReader/Writer and his work on the structure marshalling code.
A Final Note
While digging around, I came across a third party library from XCEED that supports compression, encryption, binary serialization, etc. I haven't evaluated their product, but anyone interested in a professional solution should probably look at what they have done, and I'm sure there must be other packages out there as well. There's always a balance though between developer licensing, source code access, and additional features that are part of the library that you don't need and end up being extra baggage, compared to the convenience of a pre-tested, supported product. For "simple" things like raw serialization, I tend to prefer rolling my own, as I end up learning a lot, and frankly, I'd still have to spend the same amount of time writing the test routines to validate that a third party package does what I need. And the result is, I get a short and simple piece of code that I think is easily maintained.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









 I've been sitting on this for a couple of months, and finally found the time this weekend to finish it.
I've been sitting on this for a couple of months, and finally found the time this weekend to finish it.