Accessing SIMD instructions through managed code: the Intel MKL
Preface: Try to bear with some basics and background
The real number 3E-5 is written in the form of scientific notation. It means 3*10-5 (or 10 to the negative 5th power multiplied by 3). Computers are integer machines and are capable of representing real numbers only by using complex codes. The most popular code for representing real numbers is called the IEEE Floating-Point Standard. The term floating point is derived from the fact that there is no fixed number of digits before and after the decimal point; that is, the decimal point can float. There are also representations in which the number of digits before and after the decimal point is set, called fixed-point representations. In general, floating-point representations are slower and less accurate than fixed-point representations, but they can handle a larger range of numbers. Note that most floating-point numbers a computer can represent are just approximations. One of the difficulties in programming with floating-point values is ensuring that the approximations lead to reasonable results. Because mathematics with floating-point numbers requires a great deal of computing power, many microprocessors come with a chip, called a floating point unit (FPU), specialized for performing floating-point arithmetic. FPUs are also called math coprocessors and numeric coprocessors.
Since the earlier microprocessors didn't actually have any floating-point capabilities, they only dealt with integers. Floating-point calculations were done on separate, dedicated hardware, usually in the form of a math coprocessor. But when the integrated circuit chip technology began to sore, the computing industry found that the size of the transistor could be reduced - therefore more transistors could be etched onto the semi-conductor material inside of the physical chip. The decrease in transistor size permitted a floating-point unit directly on the main CPU die. Adding these units to the main CPU die (physical core that functions at the central processing unit) added hardware and floating point instructions into the mix. It would eventually introduce a set of extended (opcode) instructions called SIMD.
Today, modern microprocessors can execute the same instruction on multiple data. This is called Single Instruction Multiple Data (SIMD). SIMD instructions handle floating-point real numbers and also provide important speedups in algorithms. Because the execution units for SIMD instructions usually belong to a physical core, it is possible to run as many SIMD instructions in parallel as available physical cores. As mentioned, the usage of these vector-processing capabilities in parallel can provide important speedups in certain algorithms. The addition of SIMD instructions and hardware to a modern, multi-core CPU is a bit more drastic than the addition of floating point capability. Since their inception, a microprocessor is an SISD device (Single Instruction stream, Single Data stream). SIMD is known as vector processing because its basic unit of organization is the vector:
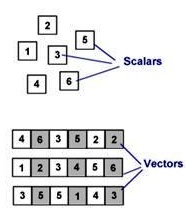
A regular CPU operates on scalars, one at a time. (A superscalar CPU operates on multiple scalars at once, but it performs a different operation on each instruction.) A vector processor, on the other hand, lines up a whole row of these scalars, all of the same type, and operates on them as a unit. So let's take a look at an example that will help us to understand the power of an SIMD instruction. The image below represents the PABSD instruction. This instruction is part of the Supplemental Streaming SIMD Extensions 3 (SSSE 3) introduced with the Intel Core 2 architecture:

The PABSD mnemonic means packed absolute value for double-word. This assembly instruction receives a 128-bit input parameter that contains four 32-bit signed integers. The instruction returns a 128-bit output that contains the absolute value for each of the four 32-bit signed integers, packed in the 128-bit output. You can calculate the absolute values for four 32-bit signed integers with a single call to the PABSD instruction. If you have to calculate the absolute values for 1,000 32-bit signed integers, you can do it with 250 calls to this instruction instead of using a single instruction for each 32-bit signed integer. You can achieve very important speedups. However, because it is necessary to pack the data before calling the SIMD instruction and then unpack the output, it is also important to measure this overhead that adds some code. If you have to calculate the absolute values for four 32-bit signed integers, the additional overhead will reduce the overall speedup. However, if you have to calculate the absolute values for 100 32-bit signed integers, you will usually benefit from the usage of this kind of SIMD instruction.
Most modern microprocessors can execute SIMD instructions, but these instructions are part of different extended instruction sets. At the time of this writing, the most advanced Intel CPU includes support for the following SIMD instruction sets:
- MMX - MultiMedia eXtensions
- SSE - Streaming SIMD Extensions
- SSE2 - Streaming SIMD Extensions 2
- SSE3 - Streaming SIMD Extensions 3
- SSSE3 - Supplemental Streaming SIMD Extensions 3
- SSE4.1 - Streaming SIMD Extensions 4.1
- SSE4.2 - Streaming SIMD Extensions 4.2
- AES-NI - Advanced Encryption Standard New Instructions
- AVX - Advanced Vector eXtensions
OK. So how do I figure out which SIMD instructions my Operating System supports? I am writing this article on a SONY VAIO laptop running on an Intel Core 2 Duo processor. I simply go to www.cpuid.com to download CPU-Z, a free utility developed by CPUID. Here is the output obtained by running CPU-Z:
The instruction field in this example contains the following values: MMX, SSE (1, 2, 3, 3S), EM64T, VT-x. The output informs me that I can run managed code while using a performance library to call functions that will use SIMD instructions. For now, let's take a look at how SIMD can parallelize data. Examine the image below:
An SIMD machine exploits a property of the data stream called data parallelism. In this context, you get data parallelism when you have a large mass of data of a uniform type that needs the same instruction performed on it. A classic example of data parallelism is inverting an RGB picture to produce its negative. You have to iterate through an array of uniform integer values (pixels), and perform the same operation (inversion) on each one -- multiple data points, a single operation. Modern, superscalar SISD machines exploit a property of the instruction stream called instruction-level parallelism (ILP). This means that you execute multiple instructions at once on the same data stream. So an SIMD machine is a different class of machine than a normal microprocessor. SIMD is about exploiting parallelism in the data stream, while superscalar SISD is about exploiting parallelism in the instruction stream. .NET Framework 4.0, however, does not provide the mechanisms to call SIMD instructions. This, in turn, means that the TPL does not contain any constructs to call SIMD instructions.
We can, however, still call SIMD instructions in our C# code by incorporating an independent library. Intel provides the Integrated Performance Primitives library (IPP) and the Intel Math Kernel Library. Intel MKL is a library of highly optimized math routines for science, engineering, and financial applications. The math routines use multiple threads and SIMD instructions to achieve the best performance according to the underlying hardware. So let's configure our development environment to integrate with this library.
Using C# source code to interoperate with the Intel Math Library
Note to the reader: this section of the article does not explain the constructs of the Intel MKL - it merely demonstrates how to call and link the Intel Math Kernel Library (Intel MKL) functions to C# programs. This provides functions that call SIMD instructions. The interested user should download the Intel C++ ComposerXE-2011 and install it to integrate into an already installed version of Microsoft Visual Studio 2010. The Intel C++ Composer 2011 ships an Intel C++ compiler, as well as a few performance libraries like the Intel TBB, the Integrated Performance Primitives (IPP), and the Intel MKL. The provided source code files have been obtained from the Intel Software web site.
Visual Studio ships a command prompt that already has the environmental variables set to run the Microsoft Visual C++ compiler. If you go to your Start menu and click the Visual Studio folder, you will see a subfolder named Visual Studio tools. Launch the command prompt and type in "vcvars32.bat". The output of that command will verify that you can run the cl.exe compiler, and more importantly, the nmake utility. At the prompt, make a new directory by typing "md c:\Examples". Extract the downloadable C# files into this directory. Examples are provided for calling the BLAS, LAPACK, DFTI (the FFT interface), the PARDISO direct sparse solver, and the vector math library (VML). Now because these are C# source code files, we will need to set the path for the C# compiler:
set PATH=%PATH%;.;C:\Windows\Microsoft.NET\Framework\v4.0.30319
If we launch the nmake utility at this point, we would get an error around the middle of the build. So even though our files reside in a VC++ command line environment and our environmental path has been set in order to use the csc.exe C# compiler driver, we must also set the path in order to use the Intel C++ command line compiler, icl.exe. A typical installation of the Intel ComposerXE-2011 suite will create a directory path similar to this one:
C:\Program Files\Intel\ComposerXE-2011\bin\ia32
This is where the icl.exe compiler resides. We must, however, execute the iclvars.bat command, a command of which resides in the bin directory. We must also set that environmental path and run the command " iclvars.bat ia32". Notice the image below:
set PATH=%PATH%;.;C:\Program Files\Intel\ComposerXE-2011\bin
We run the "iclvars.bat ia32" command. After that we run the build script using nmake:
nmake ia32 MKLROOT="C:\Program Files\Intel\ComposerXE-2011\mkl"
This is the output of executing the build script:
Text has been wrapped to avoid page scrolling
Add path of the MKL libraries to the lib environment variable
set lib=%MKLROOT%\ia32\lib;%lib%
MKL entries for custom dll
Workaround for pardiso
_fseeki64.c
Build MKL custom dll
nmake mkl.dll MACHINE=IX86
MKL_LIB="mkl_intel_c_dll.lib mkl_intel_thread_dll.lib
mkl_core_dll.lib" MSLIB=user32.lib
'mkl.dll' is up-to-date
Add path of the mkl.dll and path of the MKL binaries
to the path environment variable
set path=c:\codeExamples;%MKLROOT%\ia32\bin;%path%
Build and run examples
nmake /a dgemm.exe dgeev.exe dfti_d1.exe pardiso.exe vddiv.exe
Compile dgemm.cs
csc .\dgemm.cs
Microsoft (R) Visual C# 2010 Compiler version 4.0.30319.1
Copyright (C) Microsoft Corporation. All rights reserved.
warning CS1668: Invalid search path
'C:\Program Files\Intel\ComposerXE-2011\mkl\ia32\lib'
specified in 'LIB environment variable' --
'The system cannot find the path specified. '
Run dgemm example
dgemm.exe
MKL cblas_dgemm example
alpha=1
beta=-1
Matrix A
1 2 3
4 5 6
Matrix B
0 1 0 1
1 0 0 1
1 0 1 0
Initial C
5 1 3 3
11 4 6 9
Resulting C
0 0 0 0
0 0 0 0
TEST PASSED
Compile dgeev.cs
csc .\dgeev.cs
Microsoft (R) Visual C# 2010 Compiler version 4.0.30319.1
Copyright (C) Microsoft Corporation. All rights reserved.
warning CS1668: Invalid search path
'C:\Program Files\Intel\ComposerXE-2011\mkl\ia32\lib'
specified in 'LIB environment variable' --
'The system cannot find the path specified. '
Run dgeev example
dgeev.exe
MKL LAPACK dgeev example
Matrix A:
-2 -5 1 -1 -3
5 0 -4 -1 9
8 -1 1 6 0
2 0 3 1 -2
-4 -3 4 -4 -2
Matrix A on exit:
-3.74979687498421 3.30457083287809 0 0 0.272727272727273
-10.4969456995383 -3.74979687498421 0 0 0
6.28146648851724 6.68544105675216 -2.34478199802706 0 0
0.961154157305769 -2.58938020040906 -2.97051040398257
2.05286581472406 0
3.08511288713447 -0.862950290140918 -1.09233902416012
6.28154038161816 5.79150993327142
Wr on exit:
-3.74979687498421 -3.74979687498421 -2.34478199802706
2.05286581472406 5.79150993327142
Wi on exit:
5.88964350304832 -5.88964350304832 0 0 0
info on exit: 0
TEST PASSED
Compile dfti_d1.cs
csc .\dfti_d1.cs
Microsoft (R) Visual C# 2010 Compiler version 4.0.30319.1
Copyright (C) Microsoft Corporation. All rights reserved.
warning CS1668: Invalid search path
'C:\Program Files\Intel\ComposerXE-2011\mkl\ia32\lib' specified
in 'LIB environment variable' --
'The system cannot find the path specified. '
Run dfti_d1 example
dfti_d1.exe
Backward transform scale: 0.166666666666667
Initial data:
0 1 2 3 4 5
Resulting data:
0 1 2 3 4 5
TEST PASSED
Compile pardiso.cs
csc .\pardiso.cs
Microsoft (R) Visual C# 2010 Compiler version 4.0.30319.1
Copyright (C) Microsoft Corporation. All rights reserved.
warning CS1668: Invalid search path
'C:\Program Files\Intel\ComposerXE-2011\mkl\ia32\lib'
specified in 'LIB environment variable'
-- 'The system cannot find the path specified. '
Run pardiso example
pardiso.exe
=== PARDISO is running in In-Core mode, because iparam(60)=0 ===
================ PARDISO: solving a symmetric indef. system ================
The local (internal) PARDISO version is : 103000115
1-based array indexing is turned ON
PARDISO double precision computation is turned ON
METIS algorithm at reorder step is turned ON
Single-level factorization algorithm is turned ON
Scaling is turned ON
Summary PARDISO: ( reorder to reorder )
================
Times:
======
Time spent in calculations of symmetric matrix portrait(fulladj): 0.000014 s
Time spent in reordering of the initial matrix(reorder) : 0.000066 s
Time spent in symbolic factorization(symbfct) : 0.000239 s
Time spent in in allocation of internal data structures(malloc) : 0.000108 s
Time spent in additional calculations : 0.002201 s
Total time spent : 0.002628 s
Statistics:
===========
< Parallel Direct Factorization with #processors: > 2
< Numerical Factorization with Level-3 BLAS performance >
< Linear system Ax = b>
#equations: 8
#non-zeros in A: 18
non-zeros in A (): 28.125000
#right-hand sides: 1
< Factors L and U >
#columns for each panel: 128
#independent subgraphs: 0
< Preprocessing with state of the art partitioning metis>
#supernodes: 4
size of largest supernode: 4
number of nonzeros in L 31
number of nonzeros in U 1
number of nonzeros in L+U 32
Reordering completed ...
Number of nonzeros in factors = 32
Number of factorization MFLOPS = 0
Percentage of computed non-zeros for LL^T factorization
9 %
19 %
45 %
96 %
100 %
================ PARDISO: solving a symmetric indef. system ================
Summary PARDISO: ( factorize to factorize )
================
Times:
======
Time spent in copying matrix to internal data structure(A to LU): 0.000000 s
Time spent in factorization step(numfct) : 0.000126 s
Time spent in in allocation of internal data structures(malloc) : 0.000053 s
Time spent in additional calculations : 0.000001 s
Total time spent : 0.000179 s
Statistics:
===========
< Parallel Direct Factorization with #processors: > 2
< Numerical Factorization with Level-3 BLAS performance >
< Linear system Ax = b>
#equations: 8
#non-zeros in A: 18
non-zeros in A (): 28.125000
#right-hand sides: 1
< Factors L and U >
#columns for each panel: 128
#independent subgraphs: 0
< Preprocessing with state of the art partitioning metis>
#supernodes: 4
size of largest supernode: 4
number of nonzeros in L 31
number of nonzeros in U 1
number of nonzeros in L+U 32
gflop for the numerical factorization: 0.000000
gflop/s for the numerical factorization: 0.000541
Factorization completed ...
========= PARDISO: solving a symmetric indef. system =========
Summary PARDISO: ( solve to solve )
================
Times:
======
Time spent in direct solver at solve step (solve) : 0.000032 s
Time spent in additional calculations : 0.000068 s
Total time spent : 0.000100 s
Statistics:
===========
< Parallel Direct Factorization with #processors: > 2
< Numerical Factorization with Level-3 BLAS performance >
< Linear system Ax = b>
#equations: 8
#non-zeros in A: 18
non-zeros in A (): 28.125000
#right-hand sides: 1
< Factors L and U >
#columns for each panel: 128
#independent subgraphs: 0
< Preprocessing with state of the art partitioning metis>
#supernodes: 4
size of largest supernode: 4
number of nonzeros in L 31
number of nonzeros in U 1
number of nonzeros in L+U 32
gflop for the numerical factorization: 0.000000
gflop/s for the numerical factorization: 0.000541
Solve completed ...
The solution of the system is:
x [0] = -0.0418602012868094
x [1] = -0.0034131241592791
x [2] = 0.117250376805018
x [3] = -0.11263957992318
x [4] = 0.0241722444613714
x [5] = -0.107633340356223
x [6] = 0.198719673273585
x [7] = 0.190382963551205
TEST PASSED
Compile vddiv.cs
csc .\vddiv.cs
Microsoft (R) Visual C# 2010 Compiler version 4.0.30319.1
Copyright (C) Microsoft Corporation. All rights reserved.
warning CS1668: Invalid search path
'C:\Program Files\Intel\ComposerXE-2011\mkl\ia32\lib' specified
in 'LIB environment variable' -- 'The system cannot find the path specified. '
Run vddiv example
vddiv.exe
Vector A
1 2 3
Vector B
2 0 2
CallBack, in function: vdDiv errcode=2 index=1 arg1=2 arg2=0 res=Infinity
CallBack, result correction: 777
Vector Y
0.5 777 1.5
TEST PASSED
If you execute the "dir" DOS command, you will get a list of the executables that are the output of running the build script against the C# files.
References
- "Professional Parallel Programming" by Gaston C. Hiller
- The Intel Web Site Knowledge Base: source of the Intel Example Code
- The MSDN Library from Microsoft - sections on Compiler Intrinsics
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





