Introduction
CXFile represents a collection of file-handling code snippets I have put together over a few years working on NT client/server systems. My main reason for writing these functions was to make it easier to implement such systems - I wanted consistent interfaces, plenty of diagnostics about what was going on, and extensions that go beyond anything in the Win32 API. I also wanted to make it independent of MFC, because some older systems I work on use only Win32 SDK.
CXFile Features
When I started pulling together different pieces of code for CXFile, one of the first things I realized was that I would have to do something about all the TRACE statements that were scattered throughout the code. I am a big fan of using TRACE statements as a way to monitor actual system operation, but I was afraid I would have to yank all TRACE statements out because I did not want to be tied to MFC. I was very reluctant to do this, because alternative is to put debug output statements in application code, which becomes very messy.
Luckily I found an article by Paul Mclachlan, "Getting around the need for a vararg #define just to automatically use __FILE__ and __LINE__ in a TRACE macro". Paul's TRACE replacement is not only free of MFC dependency, it also provides file and line number output, is thread-safe, and is completely encapsulated in one header file. I have made some minor changes to Paul's class (such as adding thread ID to the output), and so I renamed it to XTrace.h to prevent any conflicts.
With the big TRACE problem out of the way, I could now decide how to use TRACE in a consistent manner. I decided I wanted diagnostics of two types: a basic informational-type debug message, that reports values and code flow; and an error diagnostic for API failures and other serious problems. So I use the standard TRACE macro for debug messages, and a new TRACEERROR macro for API failures. It is easy to disable one or both of these macros, by replacing them with usual
#define TRACE ((void)0)
definition, and I have included this capability in
XFile.cpp source.
Now for CXFile features. In addition to basic file operations such as opening/creating, reading, writing, copying, deleting, and renaming files, CXFile includes extended functions:
Data Conversions
Writing Data
When writing files,
CXFile will only write whatever data is in byte buffer that is passed to it, with one exception: if
CXFile object has been constructed with the Unicode flag set to TRUE, or has been opened with the Unicode flag set to TRUE, then
CXFile will write Unicode header (see above) when writing data at beginning of file. This flag should be used only for plain text files.
Reading Data
When reading files,
CXFile will read whatever data is in file, and return it in buffer passed to it. No
CR/LF or any other type of conversion is done.
Zip Files
The zip engine used in
CXFile does not care what type of data is in files that you zip. However, the names of the files being zipped are handled as ANSI internally by zip engine. If you look at
XZip.cpp, the
ZipAdd function is prototyped as
ZRESULT ZipAdd(HZIP hz, const TCHAR *dstzn, void *src, unsigned int len,
DWORD flags)Internally,
dstzn parameter is converted from Unicode to ANSI, and this ANSI string is used as the entry name within the zip archive. The
src parameter is name of source file (that will be compressed by
ZipAdd), and should also be passed as a Unicode string if
_UNICODE is defined.
How To Use
To integrate CXFile class into your app, you first need to add following files to your project:
- XFile.cpp
- XFile.h
- XZip.cpp
- XZip.h
- XTrace.h
The
XTrace.h file is optional, and can be excluded. If you exclude it, comment out
#include "XTrace.h" line from
XFile.cpp, and uncomment
#define TRACEERROR ((void)0) line. The
XZip.cpp and
XZip.h files are also optional, if you do not need
Zip() function. Uncomment line
#define DO_NOT_INCLUDE_XZIP at top of
XFile.cpp.
If you include CXFile in project that uses precompiled headers, you must change C/C++ Precompiled Headers settings to Not using precompiled headers for XFile.cpp and XZip.cpp.
Next, include the header file XFile.h in appropriate project files (stdafx.h usually works well). Now you are ready to start using CXFile. There are many notes concerning usage of various functions in XFile.cpp. Please read all function header for each function you wish to use.
There are two ways to construct CXFile object. Typical way is to specify file name in ctor:
CXfile file("myfile.txt");
file.Printf("This is test %d", nTest);
If you do not specify file name in
ctor, you must call
Open():
CXfile file;
file.Open("myfile.txt");
file.Printf("This is test %d", nTest);
Known Limitations
Demo App
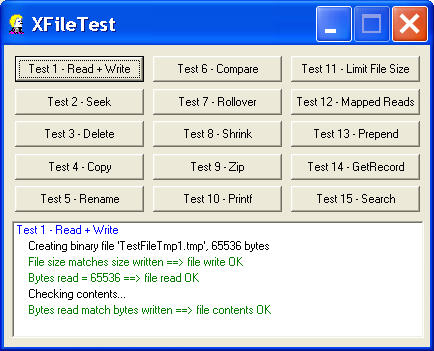
The
XFileTest.exe demo tests the APIs in
CXFile. Here is output from Test 1, that shows a binary file created and then read. Its contents are then checked.
Frequently Asked Questions
- Why use CXFile at all? Why not just use the Win32 file APIs?
Aside from the extended functions like Zip(), Shrink(), and Rollover(), the main reason is to have better error reporting. Instead of having to check the return code, and then do error reporting yourself after each API call, all you have to do is check the return code - CXFile does the error reporting for you.
- I don't want to run my app under the debugger all the time, just to get the TRACE output. How can I see all this error reporting?
You can use the excellent free utility DebugView from Sysinternals. This allows you to see all TRACE output from your debug builds. One very nice feature of DebugView that I cannot live without is the ability to filter the output, and colorize any line that contains a particular string. For example, you can set the filter to color any line containing "error" with red background and white text. You can probably guess what my filters are from this screenshot:

- Can I use XFile in non-MFC apps?
Yes. It has been implemented to compile with any Win32 program.
- When I try to include XFile.cpp in my MFC project, I get the compiler error
XFile.cpp(2611) : fatal error C1010: unexpected end of file while looking for precompiled header directive. How can I fix this?
When using XFile in project that uses precompiled headers, you must change C/C++ Precompiled Headers settings to Not using precompiled headers for XFile.cpp and XZip.cpp. Be sure to do this for All Configurations.
- When I try to build the demo app, I get the linker error
LINK : fatal error LNK1104: cannot open file "mfc42u.lib" Error executing link.exe. How can I fix this?
The default installation options of Visual C++ v6.0 don't install the Unicode libraries of MFC, so you might get an error that mfc42u.lib or mfc42ud.lib cannot be found. You can fix this either by installing the Unicode libs from the VC++ install CD, or by going to Build | Set Active Configuration and selecting one of the non-Unicode configurations.
You can configure the Visual Studio toolbars to include the Select Active Configuration combobox. This lets you see at a glance what configuration you are working with.
- I am trying to use mapped reads, but I get a debug assertion in XFile.cpp. What's wrong?
Check the TRACE output. If you see a line that says WARNING: file offset is not a multiple of system's virtual memory, then you are trying to use an invalid file offset. With mapped reads, the file offset (and therefore the read buffer size) must be a multiple of the system's virtual memory allocation granularity, or the next call to MapViewOfFile() will fail. Here is what MSDN says about this:
| The combination of the high and low offsets must specify an offset within the file that matches the system's memory allocation granularity, or [MapViewOfFile] fails. That is, the offset must be a multiple of the allocation granularity. Use the GetSystemInfo function, which fills in the members of a SYSTEM_INFO structure, to obtain the system's memory allocation granularity. |
You can use CXFile::GetAllocationGranularity() to retrieve the system's memory allocation granularity and allocate a buffer. Search for "granularity" in XFile.cpp for more information.
- I don't need the Zip function. Can I exclude XZip.cpp?
Yes. Uncomment the following line at the top of XFile.cpp:
- Can we use XFile and XZip in our (shareware/commercial) app?
Yes, you can use XFile without charge or license fee. It would be nice to acknowledge my Copyright in your About box or splash screen, but this is up to you. XZip has its own licensing requirements. Basically, it is free to use any way you want, but you must acknowledge use in your documentation. See header of XZip.cpp for details.
- Does XFile handle pipes? mailslots? other types of devices?
XFile has not been tested with anything other than files.
Acknowledgments
Revision History
Version 1.2 - 2003 May 15
- Enabled use on Win9x - removed dependency on
MoveFileEx.
- Added
Prepend function.
- Added
GetRecord function.
- Added
GetTotalRecordsRead function.
- Added
Search function
- Added
ClearBuffer function.
- Fixed
SetSizeLimit and Shrink parameters to accept byte array rather than string, and also added parameter for byte array size. This allows sequence of non-text values to be used for delimiter.
- Added
FILE_FLAG_SEQUENTIAL_SCAN flag to CreateFile, suggested by mattb79.
- Added
#define XFILE_ERROR ((DWORD)-1)
- Added
#define XFILE_EOF ((DWORD)-2)
Version 1.1 - 2003 May 5
Usage
This software is released into the public domain. You are free to use it in any way you like. If you modify it or extend it, please to consider posting new code here for everyone to share. This software is provided "as is" with no expressed or implied warranty. I accept no liability for any damage or loss of business that this software may cause.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




