Introduction
It was really an art to optimize the data retrieval from database and data retrieval optimization is part of every developer's life.
Indexes are one of the best ways of Optimization that SQL Servers provide. Understanding indexes some time may be tough. Here I will walk thorough how index will work on database engine with real life scenario. I hope this will simplify the understanding of indexes.
Background
SQL server Indexes Non-Clustered and Clustered
Real Life Scenario
Consider this real time scenario. One of your friends moved to a new place recently. He invites you for dinner.
Scenario 1: Table Scan
Consider your friend provides you only the area where he resides. Add to that, you are very new to the area. Think about how you will you go to your friends place. Here you need to scan through the full area street by street, lane by lane and think about the time taken for it.
This is something called Table Scan in SQL Server. This is also called heap in SQL Server. You are performing query on table where no index has been defined on the table.
Take the following example of Employee table:
| ID | EMPNO | FName | LName | Email |
| 1 | 1122 | A | B | abc |
| 4 | 4444 | B | C | bcd |
| 3 | 6666 | X | Y | efg |
If you want to get the employee information for empid 4444,then Database Engine needs to check all the rows to get the row. This will become more complex if you have more rows in it.
I have added the Execution plan and time taken to execute query in employee table which has around 160 hundreds of rows.
Time
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 36 ms.
Execution Plan
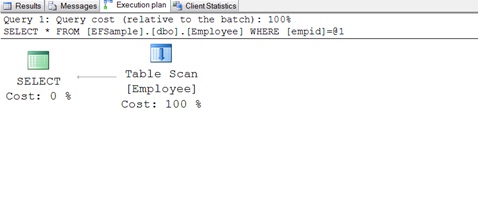
Scenario 2: Clustered Index
Now consider this, you called up your friend and asked for the address. Now you have the address. Now search scope is reduced, instead of area you started searching for street. This will definitely reduce your time.
This is something called Clustered Index in SQL Server. The index will store the data in the physical table in sorted order.
Now if you execute the query, SQL will look for data in sorted order and will return the expected rows in a much better time.
Take the same Employee table explain above. Now consider that you have created a Clustered index:
| ID | EMPNO | FName | LName | Email |
| 1 | 1122 | A | B | abd |
| 3 | 6666 | X | Y | efg |
| 4 | 4444 | B | C | bcd |
If you want to get the employee information for empid 3333, then the Database Engine will do Index Scan as Rows are in sorted order. Now search will be optimized.
I have added an execution plan and the execution time for the Employee table which has around 160 hundreds of rows after creating index. The same query is being executed in this case too.
Check the execution time between both cases. It will be clear how we have optimized the execution.
Time
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 16 ms.
Execution Plan

Scenario 3: Non-Clustered Index
Now consider this case. While getting the address, you asked him for some landmark. You find that his house is just straight opposite to the post office. Now your search will be easier and you just need to look for the post office and you are done. Think about the time taken for this process.
This is how Non-Clustered index will work in SQL server. When Non Clustered Index is created on table, it will store Non Clustered Column and Clustered index as key (as Landmark).
When you execute the query, it will bookmark and return the result.
Take the same Employee table explained above. Now consider that you have created Clustered index:
| ID | EMPNO | FName | LName | Email |
| 1 | 1122 | A | B | abc |
| 3 | 6666 | X | Y | efg |
| 4 | 4444 | B | C | bcd |
Now consider you create Non-Clustered Index on EmpNo column, the NC index will be stored as
| EMPNo | Key(ID) |
| 1122 | 1 |
| 6666 | 3 |
| 4444 | 4 |
Database Engine will execute KeyLookup and based on Key will do a Non clustered seek on parent table to get the desired rows.
I have added an execution plan and the execution time for the Employee table which has around 160 hundreds of rows after creating NC index. The same query is being executed in this case too.
Check the execution time between both cases. It will be clear how we have optimized the execution.
Execution Time
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Execution Plan
Check the execution time between all 3 cases. It will be clear how we have optimized the execution from 36ms to 1ms.
I think this comparison of time will show you how the query got optimized.
You will be able to create a Non Clustered index on multiple columns. For the above sample, if you can also create an index on EmpNo, Fname columns.
Index table will have records similar to this:
| EMPNo | Fname | Key(ID) |
| 1122 | A | 1 |
| 6666 | X | 3 |
| 4444 | B | 4 |
This is called covered Index on Empno and Fname.
The advantage of having covered index is that if you select only first name, then there is no need to refer to the main table(ie) no bookmark is required. Also your filter can be applied on FName too.
This has some limitations like 16 key columns and a maximum index key size of 900 bytes.
Included Index
You can include nonkey columns in a nonclustered index to avoid exceeding the current index size limitations(mentioned above) In the Included Index, NC Index can be created on one key column and select list can be mentioned in Included Column.
Syntax for creating Included Index is:
CREATE INDEX IndexName "
ON TableName (List of Column) "
INCLUDE (List of Columns);
In the same sample, if I created NC index on EMPno and included the columns FName and LName:
EMPNo
| Key(ID)
|
1122
| 1
|
6666
| 3
|
4444
| 4
|
Note: I created the Inner Table for logical understanding but in SQL Server it will be stored on leaf nodes.
Make all other columns that cover the query included nonkey columns. In this way, you will have all columns needed to cover the query, but the index key itself is small and efficient.
text, ntext, and image data types are not allowed in the Included Index.
Points of Interest
Bad Indexes
Now consider this while giving the landmark, your friend has provided some wrong information. Say he gave too many landmarks like opposite to Post office, beside the coffee shop, or he gives direction the other way like instead of opposite to post office he says behind the post office. This will definitely confuse and become more complex in the address search.
The same may happen in SQL Server too. If you create Index on column which is not at all used in any filter condition or joins, or create NC index without Clustered Index, it will lead to performance degradation.
You also need to consider the Transaction on tables. Index may end up degrading your transactions.
Conclusion
So I hope this will give some basic idea on Indexes on SQL server. Use Power Index in your application to get the best out of the database.
Happy coding.
History
- 4th December, 2009: Initial post
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




