Introduction
Adaptive Object Modeling is a relatively unrealized concept in object oriented design that has found some roots in advanced development processes. It allows that applications are in continual flux (or their requirements are) from adjustments to business rules, environments and user requirements. Its precepts are that using metadata for business objects, rules and process flows, instead of hard coded, static method code, makes the application more flexible to user/client needs. The AOM design model also requires that certain domain 'facts' are maintained, i.e. that there are controlled interpretations of the effects of the 'immediate' changes from user-generated metadata.
Adaptive solutions offer us a way to make applications more configurable (regarding workflow) to the end users. It is not a 99% solution and, to my knowledge, there is no end-to-end solution that meets all needs, simply because those needs are more directly defined by the business requirements. However, since business requirements change frequently, writing immutable code flow logic leaves very short lives for code. Even the online industry is feeling the need to configure dynamically: if you are a subscriber to most web portals like Yahoo or MSN, you have a user configurable home page where you can decide which items of interest you would like to display on your page. Most portal technologies are indirectly pointing us to a more adaptive model, simply because they are configurable by end-users or power-users.
I see adaptive technologies like Adaptive Object Modeling in the same light as a web portal: some functionality is needed to be coded by developers, like database and business logic, but where and when this logic is implemented should be (following business trends) decided upon by business experts, not developers. Some adaptive models incorporate the non meta-data into their models tightly coupled with their meta-data, which is one way to do it, but I prefer to let the EUD (end user developer) have the hand in how business data is handled, and simply allow the AOM framework to give the actual implementation of when and where back to business experts (which most developers don't have the bandwidth to be).
To better understand and practice the techniques of AOM design, I am writing this and several other articles that explain the usage and conversion (or refactoring effort) from a static code model to AOM design.
This article will deal with several topics dealing with implementing actual data into the AOM model. I used Martin Fowlers book Patterns of Enterprise Application Architecture for the basic architecture, but after conversing with Martin and working with the examples in the book, I brewed it down to a few key features. I did not follow for this example the exact method Martin illustrates on the DataSource and Mapper classes, in fact I eliminated them, since they did not make sense for the example for this article. I did not implement Ghost Loading, and pushed the DataMapper back into the Entity object in the form of delegates from EUD (End User Developer) classes that implement IDataSource. So part of the example will not follow the letter of Martin's book, but is my own extraction of how I see data handling in AOM. I also left off any Unit of Work code from the DomainObject, since that seems a bit self explanatory (I left some code stub methods in the Entity for further expansion, if you like).
Who this article is for
This article is written primarily for architects and business IT development managers, as well as developers who have some advanced reflection and design experience, and anyone familiar with AOM or other like pattern methodologies, who while interested in these patterns, have not seen practical ideas to the patterns usage. This series of articles will be the starting point for a AOM framework that I will be releasing later this year.
Understanding the Players
Let's first look at the part each player performs in this example:
Entity - handles relationships with other entities, handles DomainObjects and is the key piece to workflow management, defined in the meta-data. Also for this example acts as the DataMapper and Registry for the DOs.
DomainObject - (or 'DO' abbreviated) the abstract data class to be inherited from and loaded in the EUD (End User Developer) code. Each DomainObject - a specific type with specific data which is defined by its entity.
Mapper or DataMapper - the class which controls how the DO gets data loaded and updated (not defined in this example).
MapperRegistry - a registry for holding and getting a specific DataMapper (not defined in this example).
Ghost - a class that is instantiated, but not loaded with data. Also this is referred to as a Lazy Load object.
IDataSource - the interface defining data method calls to be implemented in the EUD code.
Ghost or Lazy Loading and Data Mapping
The concept of Ghost and Lazy loading has been around for awhile, and Martin in his book gives a much more in depth look at Data Mapping, Lazy Loading and Ghosts than I wanted to do here. Suffice it to say, having objects lying around waiting for data may seem cumbersome, but there are many reasons for doing this. In the AOM model, it simply is a better way to manage DomainObjects as they navigate across the relationships built by accountabilities. Also this is an optimized way to perform caching, Unit of Work processing (or entity transactions for those not familiar with that term), and manage the DomainObject's availability to the Entity and its associations.
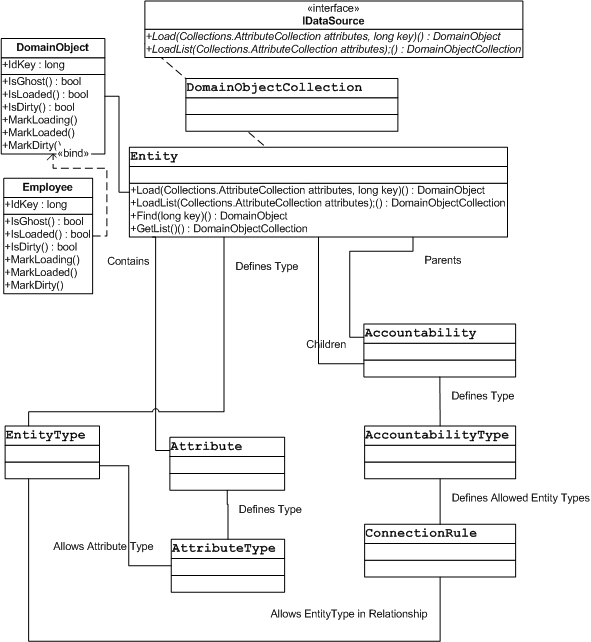
Here we see the UML for the basic Data Mapping pattern, based on the Fowler model as a reference:

Let's first look at the DomainObject's loading methods and how we load the DomainObject into the entity. In my model for the AOM, I skip a lot of Fowlers pieces, so don't get confused. For instance, I don't really make use of Lazy Loading or Ghost Loading. I want to get that clear, and the reason behind my decision not to do so is because I wanted a simpler implementation directly inside the Entity and I wanted the Entity to handle the data interface, instead of inside the DO and mapper classes. If you have been reading my article on Entity relationships, and looking at the example here, you may have realized that, the entity relationships handle the workflow of the entity, and the entities handle the actual data objects for its type. So the entity is handling a particular type of DO as a single object or a list of objects. In this way, we can allow each entity to handle its particular DomainObject type, and retrieve that data from the EUD (End User Developer) code.
Looking at the theoretical model based on the Fowler book, the data retrieval methods seems to be a method we might find on the Mapper or MapperRegistry via the IDataSource, and the update inside the DomainObject class' accessors or modifiers. but for this example, I removed the mapper and included all the functionality for the Mapper and MapperRegistry in the entity. I felt this reduced the complexity of the example. It also allowed me to use IDataSource directly to find the wanted EUD (End User Developer) methods through delegates. These delegates are Load & LoadList:
namespace DomainObjects.Operational
{
public delegate DomainObject Load(Collections.AttributeCollection attributes,
long key);
public delegate Collections.DomainObjectCollection
LoadList(Collections.AttributeCollection attributes);
......
public interface IDataSource
{
DomainObject Load(Collections.AttributeCollection attributes, long key);
DomainObjectCollection LoadList(Collections.AttributeCollection attributes);
}
Load & LoadList are defined in the DomainObjects.Operational namespace. They are simple pointers to IDataSource methods of the same name. We map them up inside the entity in the Interpreter.Factory.OperationalXMLFactory factory class (since we are using XML meta-data):
LINE:340 --- entity.Loader =
new DomainObjects.Operational.Load(dataSource.Load);
LINE:341 --- entity.ListLoader =
new DomainObjects.Operational.LoadList(dataSource.LoadList);
NOTE: Again, remember delegates are useful to gain access to a method without instantiating the actual class or making them static. So they are both thread safe, in that multiple threads can access them without collisions, and they act as methods that are instantiated from the class, without the actual class instantiation. This is useful to get pointers to the methods of a class implementing an interface like IDataSource without having to instantiate that class.
Here, we see the Find and GetList methods on the Entity. Notice, in the Find method we look for a loaded object, and if not present, we call the delegate Loader on the entity pointing to the IDataSource.Load method held in the entity by the Load delegate. We then load the DO (DomainObject) from the EUD code via this separated interface, and add it to the entity's registry. GetList loads a list of DOs based on the entity type. The actual loading of the DOs happens in the EUD code, since we are allowing the EUD code to manage all the business specific data.
class Entity....
public DomainObject Find(long key)
{
DomainObject obj = (DomainObject) _domainObjects[key];
if (obj == null)
{
obj = this.Loader(this.Attributes,key);
_domainObjects.Add(key, obj);
obj.MarkLoaded();
}
return obj;
}
public Collections.DomainObjectCollection GetList()
{
return this.ListLoader(this.Attributes);
}
We decide which DO types get loaded by mapping the appropriate EUD class implementing IDataSource via the meta-data, which returns a class inherited from DomainObject:
<entity name="Employee"
entityType="EmployeeType"
actualAttributes="EmployeeId,FullName"
dataSource="EUDStrategy.EmployeeDataSource"
/>
The Find method skips ghost loading doing this. I wanted to point out this difference in ghost loading or lazy loading and my model. The Entity acts simply as a Registry, holding the DOs of the inherited type from the EUD code. If we ghost loaded this, the Find method would be internal to the Mapper class, which I have excluded for this example, and would hold ghosted DOs and loaded ones. The DOs would get loaded via IDataSource in a slightly different manner, outside of the Find method. I simply create loaded DOs in my entity registry when needed to provide simple caching and allows DO loading directly from the Entity. This also allows a more separated coding layer from the EUD implementation code for IDataSource than the Fowler model, based on where DataSource is used. Also DO updates are not called inside the DO, but the DO is passed back through the Entity to the EUD code delegate which handles it (not implemented in this example).
You could change this by adding back a mapper class and registry object. You might do this if you want to keep track of loaded verses unloaded objects for some reason (there are many reasons to do this), but I didn't do that here. In this example a DomainObject is only a Ghost when not loaded. When loaded, it is immediately marked 'Loaded'. Also there is a IsDirty method, and methods to change the status, based on the enum LoadStatus.
enum LoadStatus {GHOST, LOADING, LOADED, DIRTY};
public bool IsGhost
{
get{return _status == LoadStatus.GHOST;}
}
public bool IsLoaded
{
get{return _status == LoadStatus.LOADED;}
}
public bool IsDirty
{
get{return _status == LoadStatus.DIRTY;}
}
public void MarkLoading()
{
_status = LoadStatus.LOADING;
}
public void MarkLoaded()
{
_status = LoadStatus.LOADED;
}
protected void MarkDirty()
{
_status = LoadStatus.DIRTY;
}
Examining Logical Program Flow
Here, we will examine how the entities handle the DO types. For this example, our inherited DO is EUDStrategy.Employee. We pass the DO, the attributes of the entity as a definition when we create the DO, and then allow the EUD code implementing IDataSource to load each DO, using the passed attributes as a definition for which attributes the object has. We see, if we select the Employee entity from the menu, that this entity's GetList method returns all employees. (I didn't implement the Find method in the client, but you could easily do so). Notice that the attributes are the same as the entity attributes set up in the meta-data: FullName and EmployeeId.
Now if we select any of the more refined types, its particular implementation of IDataSource returns only that data which is appropriate for that type. For the President entity, the PresidentDataSource class is the implementation of IDataSource, which gives us just the data for the President.
After Word
I used this very basic example not to redefine Fowler's work, but to show one way it might fit into the AOM model. As I stated earlier, I skipped a lot that you might find useful in his book, just to make the example a little easier to digest. You may have noticed that this article was simply an expansion of the previous Entity-Relationships and Accountability/Cardinality article, I did this to start to move from the simple 'refactoring from...' format to the more advanced 'this is how...' format. I kind of expect if you bothered to read all the other articles so far, you are comfortable enough by now with refactoring and patterns methodologies to comprehend my writing style shift without getting too confused.
Points of Interest
This is the seventh installment in the series I am writing on real world adaptive object modeling. All examples and the bulk of this article are taken from my professional experience as an architect. The examples given are templates only, and the designer must keep in mind that they are the ones who must decide where different patterns, if any, may be best used in their code.
Deciding to perform a refactoring effort from existing code to a pattern or enhanced design model must be weighed on the necessity and need of the code itself. Patterns and Adaptive Models are only design templates, helpers to accommodate better overall design. I might stress that, making the effort to use advanced design methodologies will strengthen your overall design ability, but like your basic coding skills, it is something learned and cultivated.
Related Articles
Other articles in this series include:
- TypeObject
- Properties
- Strategies
- Entity-Relationships and Accountability/Cardinality
- Ghost Loading, Data Mapping and more...
- Interpreter methodologies (coming soon)
- Discussions on Practical Project usefulness of design.
- Discussions on the AOM framework, UI, and advanced concepts
History
This is the first revision and is the seventh installment in a series.
Credits
Thanks to:
- Joe Yoder and Ralph Johnson, for their various articles on the AOM pattern.
- Martin Fowler, for his interest in my articles and his book Patterns of Enterprise Application Architecture.
- Doga Oztuzun, for his insight and sharing of his relevant project data.
Also to anyone else I have forgotten.





