Introduction
This is essentially a playground for an optimizing compiler that uses regular expressions instead of traditional source code as its input format, and produces a specialized bytecode for matching. The bytecode can be run by the included Pike Virtual Machine in order to match text.
This perhaps isn't the fastest C# NFA regex engine around yet, but it does support Unicode and lazy expressions, and is getting faster due to the optimizing compiler.
Update: Added final optimization (root optimization) to compiler.
Update 2: Significantly improved optimization. Will now do pure DFA if it can.
Conceptualizing this Mess
Overview
A Pike Virtual Machine is a technique for running regular expressions that relies on input programs to dictate how to match. The VM is an interpreter that runs the bytecode that executes the matching operation. The bytecode itself is compiled from one or more regular expressions.
Basically, a Pike VM is a little cooperatively scheduled concurrent VM to run that bytecode code. It has some cleverness in it to avoid backtracking. It's potentially extremely powerful, and very extensible but this one is still a baby and very much a work in progress. The VM itself is solid, but the regular expressions could use a little bit of shoring up, and it could use some more regex features, like anchors.
Features
- An assembler for assembling bytecode from
Lex's assembly language - A disassembler for transforming bytecode back into assembly language
- An optimizing compiler for turning regular expressions into bytecode
- A linker so that you can link different program portions together
- A virtual machine implementation for running matches
When using the assembler, these instructions are available:
Macros/Other
<label>: Represents a label/branch target - this is an alias for an address within the programregex (<expression>) Expands a regular expression to code; Indicates a line comment. Anything after the semicolon to the end of the line is ignored by the assembler
Instructions
match <symbol> indicates that if the machine got here, this is a match and it should return the integer symbol id indicated.jmp <label1>, <label2>, [<label3>, ... <labelN>] indicates that the machine should branch to all of the indicated target labels and try them prioritized by order.any matches any single character and advances.char "<char>" matches the specified character and advances.set ("<firstChar>".."<lastChar>" | "<char>") { , ("<firstChar>".."<lastChar>" | "<char>") } matches any character within the specified ranges and advances.nset ("<firstChar>".."<lastChar>" | "<char>") { , ("<firstChar>".."<lastChar>" | "<char>") } matches any character not within the specified ranges and advances.ucode <cat> matches any character of the specified integer Unicode category and advances.nucode <cat> matches any character not of the specified Unicode category and advances.save <slot> saves the current input position in the indicated integer slot.
Here is an example of using it to lex a simple set of symbols:
- an id of the form
[A-Z_a-z][0-9A-Z_a-z]* - an integer of the form
(0|\-?[1-9][0-9]*) - or space of the form
[\t\n\v\f\r ]
split id, int, space, error
id:
save 0
set "A".."Z", "_", "a".."z"
id_loop: split id_part, id_done
id_part: set "0".."9", "A".."Z", "_", "a".."z"
jmp id_loop
id_done: save 1
match 0
int:
save 0
split int_zero, int_nonzero
int_zero:
char "0"
jmp int_done
int_nonzero: split int_neg, int_pos
int_neg: char "-"
int_pos: set "1".."9"
int_loop:
split int_part, int_done
int_part: set "0".."9"
jmp int_loop
int_done: save 1
match 1
space:
save 0
set "\t", "\n", "\v", "\f", "\r", " "
save 1
match 2
error:
save 0
any
save 1
match -1
We'll typically never write out assembly wholesale like this. We will either use regular expressions as part of a lexer spec, or we might even embed some assembly in a lexer spec, but the above is assembly for a whole lexer spec. It's not complete on its own since it lacks a symbol table to go with it but the code is valid and this way, you get to see it top to bottom. Normally, part of this code is rendered for you when we link our lexer spec.
Anyway, in the end, this stuff gets parsed and then compiled down to an int[][] array containing our instructions. We can feed that, along with our symbol table and other information to Tokenizer to get it to fire up and lex for us.
We only need one Tokenizer class in the project no matter how many lexers we have - we just feed Tokenizer different programs to run different lexes with it. That being said, the generator does create one Tokenizer derived class for each lexer program, but that's as a convenience, so your code doesn't have to manually fill Tokenizer before using it. If this isn't clear yet, go ahead and wait as it will be demonstrated.
But How Does it Work?!
I cover the inner workings of the Pike VM in this article so be sure to read it. It's interesting stuff, at least if you're my kind of geek. This article is mainly about the optimizing compiler.
Basically, what we want to do ideally is to turn the instructions presented above into something much faster. Here is the canonical ideal that implements a "pure" DFA match but is otherwise the same as the above:
save 0
switch case "A".."Z","_","a".."z":id_part, case "0":int_done,
case "-":int_neg,case "1".."9":int_digits,case "\t", "\n", "\v", "\f", "\r", " ":space,
default:error
id_part:
switch case "0".."9","A".."Z","_","a".."z":id_part, default:id_done
id_done:
save 1
match 0
int_neg:
set "1".."9"
int_digits:
switch case "0".."9":int_digits, default:int_done
int_done:
save 1
match 1
space:
save 1
match 2
error:
any
save 1
match -1
A DFA match is the fastest possible match the Pike VM can perform, and it can only do so because I added a special instruction to it called switch, which we use nearly everywhere above. Essentially what we want is to eliminate all the jmp instructions we possibly can, particularly jmps with multiple operands, and this includes the default of the switch. This keeps our fiber count down which keeps the number of times we visit a character down. We want to visit a character only once. However, every fiber has to visit the same character in turn (even though some don't actually examine it) so the number of fibers is ultimately the arbiter of performance. One would be ideal but this engine won't get there due to the necessity of storing save states.
Like most optimizing compilers, in order to optimize, we need to create an execution graph for the regular expression(s) we want to compile. This is a directed graph that gives us a view of the "flow" of the code. Because these are regular expressions, we can use classic NFA and DFA directed graphs to represent our execution flow:

After we parse, it's relatively easy to convert the abstract syntax tree we get back from the parser to an NFA like the above (representing "id"). From there, we can do the classic minimization technique to get ourselves an equivelent DFA:
This is valuable because each epsilon transition (the gray dashed lines) resolves to a jmp instruction, and remember we do not want those, especially ones with multiple operands. Once we have a DFA, we can simply resolve each transition (the black lines) to a case in a switch (each state is a switch) then goto the code for the relevant destination state. It's straight DFA. This is why I added the switch instruction in the first place.
The trouble is supporting the root lexer state, in which we have might have lazy regular expressions. We cannot represent the lazy regular expressions in an execution graph so we cannot optimize them. Furthermore, they complicate the start state since they can't be part of the DFA. We must instead use jmp to go to each expression's start states, which is a big performance hit, especially for large lexers, since it creates a lot of fibers.
Because of this, even for optimized graphs, we would typically have jmp instructions at the beginning, like this:
L0000: save 0
L0001: jmp L0002, L0008, L0013, L0016
L0002: set "A".."Z", "_", "a".."z"
L0003: jmp L0004, L0006
L0004: set "0".."9", "A".."Z", "_", "a".."z"
L0005: jmp L0003
L0006: save 1
L0007: match 0
L0008: switch case "-":L0009, case "0":L0011, case "1".."9":L0010
L0009: switch case "1".."9":L0010
L0010: switch case "0":L0011, case "1".."9":L0010
L0011: save 1
L0012: match 1
L0013: switch case "\t".."\r", " ":L0014
L0014: save 1
L0015: match 2
L0016: any
L0017: save 1
L0018: match -1
There's an optimization opportunity here however, wherein we can take groups of expression that can be optimized and turn them into one composite expression. Basically we're creating miniature DFA lexers inside the larger NFA lexer. This cuts our root jmps down to only the states that need it. Doing this was tricky as it had to be done in such a way as to preserve order. Here's what the resulting code looks like though:
L0000: save 0
L0001: jmp L0002, L0014
L0002: switch case "\t".."\r", " ":L0003, case "-":L0005, case "0":L0009, case "1".."9":L0006, case "A".."Z", "_", "a".."z":L0011
L0003: save 1
L0004: match 2
L0005: switch case "1".."9":L0006
L0006: switch case "0".."9":L0006, default:L0007
L0007: save 1
L0008: match 1
L0009: save 1
L0010: match 1
L0011: switch case "0".."9", "A".."Z", "_", "a".."z":L0011, default:L0012
L0012: save 1
L0013: match 0
L0014: any
L0015: save 1
L0016: match -1
Now we're cooking with gas! That's nearly a "pure" DFA, and would be save for the error condition checking at L0001/L0014. I considered optimizing that out as well but in practice the performance of this is already almost as good as the full DFA.
Still, we can do better. What we have to do now is find cases where this jmp <next address>, <error label> followed by the switch happen at the beginning of the code, because this is a pattern that crops up whenever the rest of the machine is a pure DFA. So we look for those cases, eliminate the jmp, and replace it with a default case on the switch going to the <error label>.
I also fixed the FA emit routine to stop spitting out duplicate save/match code. Combined this leads to ideal DFAs wherever they're possible. The optimized code looks precisely like the code from the DFA above except perhaps in a different order - and order doesn't matter for DFAs, only for NFAs becuase DFAs cannot be ambiguous. We know this because of various mathematical proofs around finite automata but I'm not going to cover the math here.
Let's move on to the code.
Using the Code
The core class is called Lex and it exposes all of the primary services of the lexing engine, from the compiler to the interpreter/VM.
Usually, you'll use it to build lexers, like this:
var program = Lex.CompileLexerRegex(false,
@"[A-Z_a-z][A-Z_a-z0-9]*",
@"0|(\-?[1-9][0-9]*)",
@"[ \t\r\n\v\f]"
);
You can then Run(), RunWithLoggingAndStatistics(), or Dissassemble() the program.
As an alternative, you can also enter assembly code with even less work:
var program = Lex.AssembleFrom(@"..\..\program.lasm");
With a little more work, it's possible to intermix assembly code with compiled regex code. You can either use the regex() macro itself inside the assembly code, or you can use the Lex API to link various bits of code you get from assembling and compiling:
var intAsm = Lex.AssembleFrom(@"..\..\int.lasm");
var prog = Lex.LinkLexerParts(true,new KeyValuePair<int,int[][]>[] {
new KeyValuePair<int,int[][]>(0,Lex.CompileRegexPart(@"[A-Z_a-z][A-Z_a-z0-9]*")),
new KeyValuePair<int,int[][]>(1,intAsm),
new KeyValuePair<int,int[][]>(2,Lex.CompileRegexPart(@"[ \t\r\n\v\f]"))
});
We're constructing KeyValuePair<int,int[][]>s to pass into LinkLexerParts() where the Key is the desired match symbol id and the Value is the program fragment.
Basically, what we're doing here is compiling pre-linked bits of regex and linking it with intAsm:
switch case "0":int_done, case "-":int_pos, case "1".."9":int_loop
int_pos: set "1".."9"
int_loop:
jmp int_part, int_done
int_part: set "0".."9"
jmp int_loop
int_done:
Note that there's no save or match instructions in here. They are added by the linker. Your job is to produce the code that would go between those instructions.
Running the machines is simple:
var lc = LexContext.Create("my test input");
while (LexContext.EndOfInput != lc.Current)
{
lc.ClearCapture();
var acc = Lex.Run(prog, lc);
Console.WriteLine("{0}: {1}",acc,lc.GetCapture());
}
acc will be the match symbol id or -1 for error.
The included demo code in LexDemo runs performance tests on various lexer configurations:
var test = "fubar bar 123 1foo bar -243 0 baz 83";
Console.WriteLine("Lex: " + test);
var prog = Lex.CompileLexerRegex(false,
@"[A-Z_a-z][A-Z_a-z0-9]*",
@"0|(\-?[1-9][0-9]*)",
@"( |\t|\r|\n|\v|\f)"
);
Console.WriteLine("Unoptimized dump:");
Console.WriteLine(Lex.Disassemble(prog));
Console.WriteLine();
var progOpt = Lex.CompileLexerRegex(true,
@"[A-Z_a-z][A-Z_a-z0-9]*",
@"0|(\-?[1-9][0-9]*)",
@"( |\t|\r|\n|\v|\f)"
);
Console.WriteLine("Optimized dump:");
Console.WriteLine(Lex.Disassemble(progOpt));
Console.WriteLine();
var progDfa = Lex.AssembleFrom(@"..\..\dfa.lasm");
Console.WriteLine("DFA dump:");
Console.WriteLine(Lex.Disassemble(progDfa));
Console.WriteLine();
var result = -1;
var count = 0f ;
var maxFiberCount = 0;
var avgCharPasses = 0f;
LexContext lc = LexContext.Create(test);
while (LexContext.EndOfInput!=lc.Current)
{
var stats = Lex.RunWithLoggingAndStatistics(prog, lc, TextWriter.Null, out result);
maxFiberCount = stats.MaxFiberCount;
if (stats.AverageCharacterPasses > avgCharPasses)
avgCharPasses = stats.AverageCharacterPasses;
++count;
}
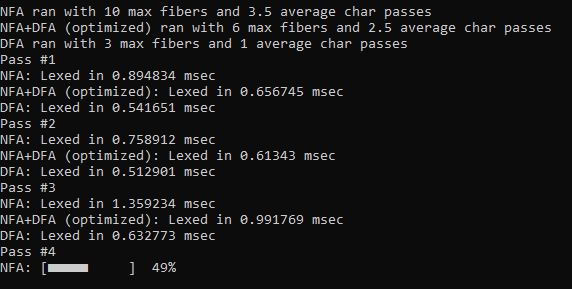
Console.WriteLine("NFA ran with "+maxFiberCount+" max fibers
and " + avgCharPasses+ " average char passes");
count = 0f;
maxFiberCount = 0;
avgCharPasses = 0f;
count = 0;
lc = LexContext.Create(test);
while (LexContext.EndOfInput != lc.Current)
{
var stats = Lex.RunWithLoggingAndStatistics(progOpt, lc, TextWriter.Null, out result);
maxFiberCount = stats.MaxFiberCount;
if (stats.AverageCharacterPasses > avgCharPasses)
avgCharPasses = stats.AverageCharacterPasses;
++count;
}
Console.WriteLine("NFA+DFA (optimized) ran with " +
maxFiberCount+ " max fibers and " + avgCharPasses + " average char passes");
count = 0;
maxFiberCount = 0;
avgCharPasses = 0f;
lc = LexContext.Create(test);
while (LexContext.EndOfInput != lc.Current)
{
var stats = Lex.RunWithLoggingAndStatistics(progDfa, lc, TextWriter.Null, out result);
maxFiberCount = stats.MaxFiberCount;
if (stats.AverageCharacterPasses > avgCharPasses)
avgCharPasses = stats.AverageCharacterPasses;
++count;
}
Console.WriteLine("DFA ran with " + maxFiberCount +
" max fibers and " + avgCharPasses+ " average char passes");
for (var i = 0; i < 5; ++i)
test = string.Concat(test, test);
for (var i = 0; i < 10; ++i)
{
Console.WriteLine("Pass #" + (i + 1));
Console.Write("NFA: ");
Perf(prog, test);
Console.Write("NFA+DFA (optimized): ");
Perf(progOpt, test);
Console.Write("DFA: ");
Perf(progDfa, test);
}
The code is pretty involved but most of what it's doing is bookkeeping and stat dumping. The actual calls to the API are quite simple.
That's about it for now. Be sure to check out the other projects included in this kit, like Lexly, the lexer generator that uses this engine.
History
- 2nd February, 2020 - Initial submission
- 4th February, 2020 - Fixed bug in FA.Parse() - slight optimization improvement (not reflected in article)
Just a shiny lil monster. Casts spells in C++. Mostly harmless.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







