Introduction
The class CBackProp encapsulates a feed-forward neural network and a back-propagation algorithm to train it. This article is intended for those who already have some idea about neural networks and back-propagation algorithms. If you are not familiar with these, I suggest going through some material first.
Background
This is part of an academic project which I worked on during my final semester back in college, for which I needed to find the optimal number and size of hidden layers and learning parameters for different data sets. It wasn't easy finalizing the data structure for the neural net and getting the back-propagation algorithm to work. The motivation for this article is to save someone else the same effort.
Here's a little disclaimer... This article describes a simplistic implementation of the algorithm, and does not sufficiently elaborate on the algorithm. There is a lot of room to improve the included code (like adding exception handling :-), and for many steps, there is a lot more reasoning required than I have included, e.g., values that I have chosen for parameters, and the number of layers/the neurons in each layer are for demonstrating the usage and may not be optimal. To know more about these, I suggest going to:
Using the code
Typically, the usage involves the following steps:
- Create the net using
CBackProp::CBackProp(int nl,int *sz,double b,double a) - Apply the back-propagation algorithm - train the net by passing the input and the desired output, to
void CBackProp::bpgt(double *in,double *tgt) in a loop, until the Mean square error, which is obtained by CBackProp::double mse(double *tgt), gets reduced to an acceptable value. - Use the trained net to make predictions by feed-forwarding the input data using
void CBackProp::ffwd(double *in).
The following is a description of the sample program that I have included.
One step at a time...
Setting the objective:
We will try to teach our net to crack the binary A XOR B XOR C. XOR is an obvious choice, it is not linearly separable hence requires hidden layers and cannot be learned by a single perception.
A training data set consists of multiple records, where each record contains fields which are input to the net, followed by fields consisting of the desired output. In this example, it's three inputs + one desired output.
double data[][4]={ 0, 0, 0, 0,
0, 0, 1, 1,
0, 1, 0, 1,
0, 1, 1, 0,
1, 0, 0, 1,
1, 0, 1, 0,
1, 1, 0, 0,
1, 1, 1, 1 };
Configuration:
Next, we need to specify a suitable structure for our neural network, i.e., the number of hidden layers it should have and the number of neurons in each layer. Then, we specify suitable values for other parameters: learning rate - beta, we may also want to specify momentum - alpha (this one is optional), and Threshold - thresh (target mean square error, training stops once it is achieved else continues for num_iter number of times).
Let's define a net with 4 layers having 3,3,3, and 1 neuron respectively. Since the first layer is the input layer, i.e., simply a placeholder for the input parameters, it has to be the same size as the number of input parameters, and the last layer being the output layer must be same size as the number of outputs - in our example, these are 3 and 1. Those other layers in between are called hidden layers.
int numLayers = 4, lSz[4] = {3,3,3,1};
double beta = 0.2, alpha = 0.1, thresh = 0.00001;
long num_iter = 500000;
Creating the net:
CBackProp *bp = new CBackProp(numLayers, lSz, beta, alpha);
Training:
for (long i=0; i < num_iter ; i++)
{
bp->bpgt(data[i%8], &data[i%8][3]);
if( bp->mse(&data[i%8][3]) < thresh)
break; }
Let's test its wisdom:
We prepare test data, which here is the same as training data minus the desired output.
double testData[][3]={ 0, 0, 0,
0, 0, 1,
0, 1, 0,
0, 1, 1,
1, 0, 0,
1, 0, 1,
1, 1, 0,
1, 1, 1};
Now, using the trained network to make predictions on our test data....
for ( i = 0 ; i < 8 ; i++ )
{
bp->ffwd(testData[i]);
cout << testData[i][0]<< " "
<< testData[i][1]<< " "
<< testData[i][2]<< " "
<< bp->Out(0) << endl;
}
Now a peek inside:
Storage for the neural net
I think the following code has ample comments and is self-explanatory...
class CBackProp{
double **out;
double **delta;
double ***weight;
int numl;
int *lsize;
double beta;
double alpha;
double ***prevDwt;
double sigmoid(double in);
public:
~CBackProp();
CBackProp(int nl,int *sz,double b,double a);
void bpgt(double *in,double *tgt);
void ffwd(double *in);
double mse(double *tgt);
double Out(int i) const;
};
Some alternative implementations define a separate class for layer / neuron / connection, and then put those together to form a neural network. Although it is definitely a cleaner approach, I decided to use double *** and double ** to store weights and output etc. by allocating the exact amount of memory required, due to:
- The ease it provides while implementing the learning algorithm, for instance, for weight at the connection between (i-1)th layer's jth Neuron and ith layer's kth neuron, I personally prefer
w[i][k][j] (than something like net.layer[i].neuron[k].getWeight(j)). The output of the ith neuron of the jth layer is out[i][j], and so on. - Another advantage I felt is the flexibility of choosing any number and size of the layers.
CBackProp::CBackProp(int nl,int *sz,double b,double a):beta(b),alpha(a)
{
numl=nl;
lsize=new int[numl];
for(int i=0;i<numl;i++){
lsize[i]=sz[i];
}
out = new double*[numl];
for( i=0;i<numl;i++){
out[i]=new double[lsize[i]];
}
delta = new double*[numl];
for(i=1;i<numl;i++){
delta[i]=new double[lsize[i]];
}
weight = new double**[numl];
for(i=1;i<numl;i++){
weight[i]=new double*[lsize[i]];
}
for(i=1;i<numl;i++){
for(int j=0;j<lsize[i];j++){
weight[i][j]=new double[lsize[i-1]+1];
}
}
prevDwt = new double**[numl];
for(i=1;i<numl;i++){
prevDwt[i]=new double*[lsize[i]];
}
for(i=1;i<numl;i++){
for(int j=0;j<lsize[i];j++){
prevDwt[i][j]=new double[lsize[i-1]+1];
}
}
srand((unsigned)(time(NULL)));
for(i=1;i<numl;i++)
for(int j=0;j<lsize[i];j++)
for(int k=0;k<lsize[i-1]+1;k++)
weight[i][j][k]=(double)(rand())/(RAND_MAX/2) - 1;
for(i=1;i<numl;i++)
for(int j=0;j<lsize[i];j++)
for(int k=0;k<lsize[i-1]+1;k++)
prevDwt[i][j][k]=(double)0.0;
}
Feed-Forward
This function updates the output value for each neuron. Starting with the first hidden layer, it takes the input to each neuron and finds the output (o) by first calculating the weighted sum of inputs and then applying the Sigmoid function to it, and passes it forward to the next layer until the output layer is updated:
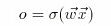
where:
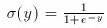
void CBackProp::ffwd(double *in)
{
double sum;
for(int i=0;i < lsize[0];i++)
out[0][i]=in[i];
for(i=1;i < numl;i++){
for(int j=0;j < lsize[i];j++){
sum=0.0;
for(int k=0;k < lsize[i-1];k++){
sum+= out[i-1][k]*weight[i][j][k];
}
sum+=weight[i][j][lsize[i-1]];
out[i][j]=sigmoid(sum);
}
}
}
Back-propagating...
The algorithm is implemented in the function void CBackProp::bpgt(double *in,double *tgt). Following are the various steps involved in back-propagating the error in the output layer up till the first hidden layer.
void CBackProp::bpgt(double *in,double *tgt)
{
double sum;
First, we call void CBackProp::ffwd(double *in) to update the output values for each neuron. This function takes the input to the net and finds the output of each neuron:
where:
ffwd(in);
The next step is to find the delta for the output layer:
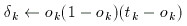
for(int i=0;i < lsize[numl-1];i++){
delta[numl-1][i]=out[numl-1][i]*
(1-out[numl-1][i])*(tgt[i]-out[numl-1][i]);
}
then find the delta for the hidden layers...
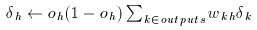
for(i=numl-2;i>0;i--){
for(int j=0;j < lsize[i];j++){
sum=0.0;
for(int k=0;k < lsize[i+1];k++){
sum+=delta[i+1][k]*weight[i+1][k][j];
}
delta[i][j]=out[i][j]*(1-out[i][j])*sum;
}
}
Apply momentum (does nothing if alpha=0):
for(i=1;i < numl;i++){
for(int j=0;j < lsize[i];j++){
for(int k=0;k < lsize[i-1];k++){
weight[i][j][k]+=alpha*prevDwt[i][j][k];
}
weight[i][j][lsize[i-1]]+=alpha*prevDwt[i][j][lsize[i-1]];
}
}
Finally, adjust the weights by finding the correction to the weight.
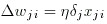
And then apply the correction:
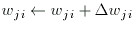
for(i=1;i < numl;i++){
for(int j=0;j < lsize[i];j++){
for(int k=0;k < lsize[i-1];k++){
prevDwt[i][j][k]=beta*delta[i][j]*out[i-1][k];
weight[i][j][k]+=prevDwt[i][j][k];
}
prevDwt[i][j][lsize[i-1]]=beta*delta[i][j];
weight[i][j][lsize[i-1]]+=prevDwt[i][j][lsize[i-1]];
}
}
How learned is the net?
Mean square error is used as a measure of how well the neural net has learnt.
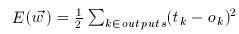
As shown in the sample XOR program, we apply the above steps until a satisfactorily low error level is achieved. CBackProp::double mse(double *tgt) returns just that.
History
- Created date: 25th Mar'06.

