Introduction
Have you ever wanted to execute simple SQL SELECT statements against in-memory collections and lists? Well, I have, and this article presents a mechanism to do that utilizing LINQ and runtime generated and compiled Lambda Expressions. The result is support for runtime query evaluations like:
var result = source.Query<Person, Tuple<string, double>>(
"SELECT Address, Avg(Age) FROM this GROUP BY Address");
var result2 = source.Query<Person, Family>(
"SELECT Address, Avg(Age) AS AverageAge FROM this GROUP BY Address");
var result3 = source.Query<Person>("SELECT * FROM this ORDER BY age");
var result4 = source.Query<Person, string>("SELECT DISTINCT address FROM this")
I'm a big fan of LINQ, especially LINQ to Objects. Code that might be tens of lines long using a foreach iteration and evaluation can often be shortened to 1 or 2 lines. Anything that reduces code lines is a big plus for maintainability and quality. As I've used LINQ more and more in both production and hobby code, I've found that while the Enumerable extension methods are pretty easy to follow and work with, I continue to trip on the "almost SQL" inline LINQ C# keywords. Perhaps I've been at this too long, but my fingers just won't start a query statement with any other word than SELECT.
My personal short comings aside, I've found that LINQ has a more practical limitation, namely those "almost SQL" statements are still tightly coupled to an application's static structure. I was a big fan of the VARIANT back in the day, and have always thought that IDispatchEx never really got a chance to show its real potential outside of Microsoft apps before COM went out of style. Dynamic typing has a lot of advantages especially in increasingly large, complex, and distributed systems. Perhaps, I should switch to Python, but C# pays the bills.
Luckily, Microsoft has been adding dynamic typing features to .NET and C#. C#/.NET 4.0 is adding some interesting features: the F# Tuple type has been made part of the BCL; C# gets a dynamic keyword and access to the Dynamic Language Runtime, and the BCL gets an ExpandoObject allowing even statically typed languages like VB.NET and C# to take on some features of a Duck Typed language. The combination of dynamic and static typing within C# may be a powerful new addition, or it might end up being a Frankenstein with the worst features of both approaches. It will be interesting to see how all of this plays out over time.
But I digress. The real reason for this article is that I've always wanted to write a runtime evaluation engine. .NET 3.5 (with the addition of System.Linq.Expressions) and the dynamic typing features of C# 4.0 have provided the right set of tools. So I gave it a whirl.
What came out the other end lets you take something like this:
var result = from p in source
group p by p.Address into g
where g.Average(p => p.Age) > 40
select new { Address = g.Key, AverageAge = g.Average(p => p.Age) };
and replace it with something like this:
var result = source.Query<Person, dynamic>("SELECT Address, Avg(Age) AS AverageAge
FROM this GROUP BY Address HAVING AverageAge > 40")Why would you want such a thing after Microsoft went to all that trouble creating Linq? Well most of the time you don't. Linq is awesome for the majority of applications where the data model is static and the view the application needs of it changes only slowly over time. It's for those cases where the data model is dynamic or the apps view of the data cannot be defined at compile time that I started poking around with this idea.
Background
The basis for this article begins with a previous installment: Taking LINQ to SQL in the Other Direction. That article describes the basic parsing and evaluation infrastructure used. Much of the underlying code is the same (or at least started it out the same) especially in the area of SQL parsing using the GOLD parser. A limitation in that previous code was that the data being evaluated had to be in the form of an IDictionary<string, object> and that was also how the data was returned to the caller.
It also owes some inspiration to the Dynamic LINQ example that Microsoft published as part of the VS2008 Samples collection.
Caveat Emptor
The attached code and project was created with Microsoft Visual Studio 2010 Beta 2, and some of the new features of C# and .NET 4.0, such as:
The upshot is that you won't be able to play with the attached code using VS.NET 2008 or .NET 3.5.
Using the Code
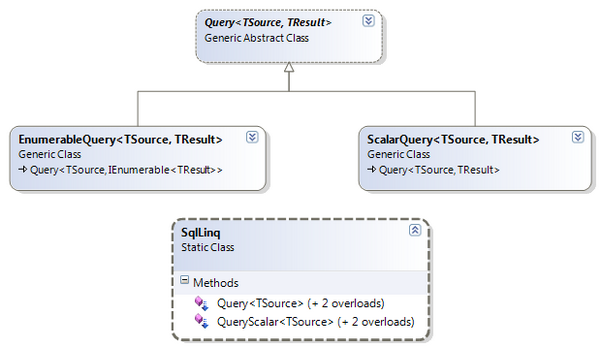
The entry point in the API is a small set of extension methods that extend IEnumerable<T> and take a SQL statement in the form of a string. There are two sets of overloads:
QueryScalar - returns a single scalar value (like an int)Query - returns an IEnumerable<T>
The SQL string is immediately turned into a Query<,> derived object (one for scalar queries, one for enumerable queries). The responsibilities of the Query classes are:
- Parse the SQL text into a parse tree
- Convert the parse tree into expression trees
- Convert and cache the expression trees into lambda functions that can be used to evaluate the data sets
The parsing happens in the base class, and is largely the same as it was in the previous article.
Creating the evaluation functions is a matter of determining which parts of a SQL query are present and generating a lambda for each one:
protected override void OnCompile()
{
if (SyntaxNode.GroupByClause == null)
Select = SyntaxNode.CreateSelector<TSource, TResult>();
else
GroupBySelect = SyntaxNode.CreateGroupBySelector<TSource, TResult>();
if (SyntaxNode.WhereClause != null)
Where = SyntaxNode.WhereClause.CreateEvaluator<TSource>();
if (SyntaxNode.OrderByClause != null)
OrderBy = SyntaxNode.OrderByClause.CreateFunction<TSource>();
if (SyntaxNode.HavingClause != null)
Having = SyntaxNode.HavingClause.CreateEvaluator<TResult>();
with a resulting evaluation method that executes each lambda in turn:
public override IEnumerable<TResult> Evaluate(IEnumerable<TSource> source)
{
if (Where != null)
source = source.Where<TSource>(Where);
if (OrderBy != null)
source = OrderBy(source);
IEnumerable<TResult> result = Enumerable.Empty<TResult>();
if (Select != null)
result = source.Select<TSource, TResult>(Select);
else
result = GroupBySelect(source);
if (Having != null)
result = result.Where<TResult>(Having);
if (SyntaxNode.Columns.Distinct)
return result.Distinct();
return result;
}
Some Notes About the SQL Syntax
The SQL syntax is based on the SELECT portions of SQL 89's DML. INSERT, DELETE, and UPDATE abilities may come later.
In order to support both querying a type's properties and its valuevalue() function built in. This allows queries such as the following to be differentiated:
List<string> l = new List<string>();
l.Add("don");
l.Add("phillip");
l.Add("kackman");
IEnumerable<string> result = l.Query<string>("SELECT * FROM this WHERE value() = 'don'");
IEnumerable<string> result2 = l.Query<string>("SELECT * FROM this WHERE Length > 3");
Also, the this entry in the join chain portion of the FROM clause is merely a placeholder. It refers to the same this that is passed to the extension methods or the IEnumerable<T> passed to the Evaluate methods. In a future update, I'd like to add support for joins across multiple collections, but at the moment, that capability isn't present.
Points of Interest
The most challenging part of this was creating result selectors. SQL return types are polymorphic depending on the query. A SELECT query can return a subset of the input data without a type transformation, with queries such as SELECT * FROM this WHERE Age = 40. It can return a subset of the fields from the input data type: SELECT name, age FROM this. It can return a single value in situations like SELECT Avg(Age) FROM this. Or queries can return completely transformed types that are aggregations of the input data: SELECT name, Avg(age) FROM this GROUP BY name.
The type parameters passed to the Query methods indicate both the type contained in the enumerable and the type to create and return.
public static IEnumerable<TResult> Query<TSource, TResult>
(this IEnumerable<TSource> enumerable, string sql)
Subselection
For a query that will return the same type as passed in, both TSource and TResult will be the same. There is an overload for this case that only takes one type parameter.
IEnumerable<int> source = TestData.GetInts();
IEnumerable<int> result = source.Query<int>("SELECT * FROM this WHERE value() > 3");
In this case, the selector is a simple identity lambda:
public static Expression<Func<TSource, TResult>> CreateIdentitySelector<TSource, TResult>()
{
ParameterExpression arg = Expression.Parameter(typeof(TSource), "arg");
return Expression.Lambda<Func<TSource, TResult>>(arg, arg);
}
Single Properties
For selecting single properties from the source type, a lambda is created that returns the value of that property from each source object. This doesn't require the creation and initialization of new objects:
IEnumerable<Person> source = TestData.GetPeople();
IEnumerable<int> result = source.Query<Person, int>("SELECT Age FROM this WHERE age > 40");
...
public static Expression<Func<TSource, TResult>>
CreateSinglePropertySelector<TSource, TResult>(string propertyName)
{
ParameterExpression param = Expression.Parameter(typeof(TSource), "item");
return Expression.Lambda<Func<TSource, TResult>>(
Expression.PropertyOrField(param, propertyName), param);
}
Multiple Properties
Returning multiple properties requires creating new instances of TResult and populating them with the result data. There are three approaches to doing this.
In most cases, it is expected that the return type has read/write properties for each of the fields in the SELECT statement. In this case, if the source property name is not the same as the result property, the AS keyword can be used to map the two. In the example below, the Person class has a property named Address, while OtherPerson has Location:
var result = source.Query<Person, OtherPerson>("SELECT name, address AS location FROM this")
...
public static Expression<Func<TSource, TResult>> CreateMemberInitSelector<TSource, TResult>
(IEnumerable<string> sourceFields, IEnumerable<string> resultFields)
{
ParameterExpression arg = Expression.Parameter(typeof(TSource), "arg");
var bindings = new List<MemberAssignment>();
int i = 0;
foreach (string field in resultFields)
{
MemberInfo member = typeof(TResult).GetPropertyOrField(field);
MemberExpression memberExpression =
Expression.PropertyOrField(arg, sourceFields.ElementAt(i++));
bindings.Add(Expression.Bind(member, memberExpression));
}
var init = Expression.MemberInit(Expression.New(typeof(TResult)), bindings);
return Expression.Lambda<Func<TSource, TResult>>(init, arg);
}
As a side note: all property names are evaluated in a case insensitive fashion. If TSource or TResult has Property and property, exceptions will be thrown.
A special selector is created for the Tuple type which has a constructor that takes an argument for each constituent property. The order of fields in the Select statement must match the order of arguments in the constructor declaration.
var result = source.Query<Person, Tuple<string, string>>("SELECT name, address FROM this")
...
public static Expression<Func<TSource, TResult>>
CreateConstructorCallSelector<TSource, TResult>
(IEnumerable<string> fields, Type[] constructorTypes)
{
ParameterExpression arg = Expression.Parameter(typeof(TSource), "arg");
var bindings = fields.Select(field => Expression.PropertyOrField(arg, field));
ConstructorInfo constructor = typeof(TResult).GetConstructor(constructorTypes);
NewExpression _new = Expression.New(constructor, bindings);
return Expression.Lambda<Func<TSource, TResult>>(_new, arg);
}
Dynamic and Expando
Another special selector is created when dynamic is specified as TResult. In this case, you will always get a collection of ExpandoObjects back. ExpandoObject implements IDictionary<string, object> to store the set of dynamically assigned properties, and this interface is used to populate the return objects. It is via this mechanism that this API goes from statically to dynamically typed. Something I noticed about the ExpandoObject is that its property names are case sensitive. I don't know if that's good or bad, but for some reason, I expected them not to be, since it would seem to mesh more with a dynamically typed environment.
var result = source.Query<Person, dynamic>("SELECT age, address FROM this")
...
public static Expression<Func<TSource, TResult>> CreateExpandoSelector<TSource, TResult>
(IEnumerable<string> sourceFields, IEnumerable<string> resultFields)
{
ParameterExpression arg = Expression.Parameter(typeof(TSource), "arg");
var bindings = new List<ElementInit>();
MethodInfo addMethod = typeof(IDictionary<string, object>).GetMethod(
"Add", new Type[] { typeof(string), typeof(object) });
int i = 0;
foreach (string field in resultFields)
{
MemberExpression memberExpression =
Expression.PropertyOrField(arg, sourceFields.ElementAt(i++));
bindings.Add(Expression.ElementInit(addMethod,
Expression.Constant(field),
Expression.Convert(memberExpression, typeof(object))));
}
var expando = Expression.New(typeof(ExpandoObject));
return Expression.Lambda<Func<TSource, TResult>>(
Expression.ListInit(expando, bindings), arg);
}
Grouping
By far the most challenging selector was GROUP BY. This involves not only a type transformation between TSource and TResult but the calculation of properties on the return type as opposed to only assignment. It took me a while to wrap my head around how to do this without calculating and caching some intermediate state for each aggregate. In the end, I created a type, GroupByCall, to cache the delegate for each aggregate at compile time for later invocation during evaluation.
var result = source.Query<Person, Family>(
"SELECT Address, Avg(Age) AS AverageAge FROM this GROUP BY Address")
...
public static Expression<Func<IEnumerable<TSource>, IEnumerable<TResult>>>
CreateGroupBySelector<TSource, TResult>(string groupByField,
Type keyType, IEnumerable<AggregateNode> aggregates)
{
var keyLambdaArg = Expression.Parameter(typeof(TSource), "keyLambdaArg");
var keyLambda = Expression.Lambda(
Expression.PropertyOrField(keyLambdaArg, groupByField), keyLambdaArg);
var group = Expression.Parameter(typeof(IEnumerable<TSource>), "group");
GroupByCall<TSource, TResult> groupingCall =
new GroupByCall<TSource, TResult>(groupByField);
foreach (AggregateNode aggregate in aggregates)
{
var aggregateExpression = aggregate.GetCallExpression(
typeof(IEnumerable<TSource>), typeof(TSource), group);
groupingCall.Aggregates.Add(aggregate.Alias,
Expression.Lambda(aggregateExpression, group).Compile());
}
var key = Expression.Parameter(keyType, "key");
var groupingFunc = Expression.Call(Expression.Constant(groupingCall),
"GroupingFunc", new Type[] { keyType }, key, group);
var resultSelectorLambda = Expression.Lambda(groupingFunc, key, group);
var data = Expression.Parameter(typeof(IEnumerable<TSource>), "data");
var groupByExpression = Expression.Call(typeof(Enumerable), "GroupBy",
new Type[] { typeof(TSource), keyType, typeof(TResult) },
data, keyLambda, resultSelectorLambda);
return Expression.Lambda<Func<IEnumerable<TSource>,
IEnumerable<TResult>>>(groupByExpression, data);
}
Joining
The updated code also supports simple inner joins between to IEnumerables. Given that the outer enumerable needed to be identified in the SQL test I invented a "that" keyword. Perhaps a little hokey but it satisfied my curiosity that this could be done.
[TestMethod]
public void JoinAndGroup()
{
IEnumerable<Person> source = TestData.GetPeople();
IEnumerable<Family> families = TestData.GetFamilies();
var answer = from p in source
join f in families on p.Address equals f.Address
group f by f.Name into g
select new Tuple<string, int>(g.Key, g.Count());
var result = source.Query<Person, Family, Tuple<string, int>>("SELECT that.Name, COUNT(*)" +
"FROM this INNER JOIN that ON this.Address = that.Address GROUP BY that.Name", families);
Assert.IsTrue(result.Any());
Assert.IsTrue(answer.Any());
Assert.IsTrue(result.SequenceEqual(answer));
}
Conclusion
The attached unit tests contain plenty of examples for different combinations of the above, but most of the basic syntax of SQL SELECT should work. I've had a lot of fun with this code thus far, and am planning on updating it with additional functionality. Hopefully, you find it useful or at the very least interesting.
History
- Initial upload - 11/11/2009.
- Added joins, bug fixes, misc other stuff - 5/8/2013
- Fixed some bugs with nullable type comparisons - 5/25/2013
- Added ability to use ExpandoObject as enumerable source and join target - 8/2/2013

