Abstract
There are multiple ways to develop and deploy a SQL Server database in Visual Studio. SQL Server Database Projects is one of them. It is sometimes faster to use SQL Server Data Projects for small projects versus handwritten migration scripts. However, these projects do not work with Visual Studio Build configurations (VS 2017.15.3.0). In this document, we describe the benefits of these projects and demonstrate how we use PowerShell, pre-built, and post-built scripts to change the behavior of Visual Studio for compiling SQL Server database projects and add the support for multiple configurations such as Debug, Release, etc.
Introduction
SQL Server is a common database tool for many .NET developers who use Visual Studio for developing applications. In general, there are two major ways of deploying SQL Server databases: Migrations and States. In Migrations, the developer writes transitions scripts that takes the database from one state to another state. For example, he uses Create Table to create tables in the first state. Then uses Alter Table to add a new column to this table. In States approach, the developer modifies the same table using a visual tool or just updating the Create Table SQL script. The developer can use a compare tool to compare the previous state to the next state in order to create migration scripts. SQL Server Database Projects is a powerful tool for the database development and deployment using States approach. In the following sections, we discuss the benefits of using SQL Server Database Projects and explain how we added one of the lacking features in these projects.
Benefits of SQL Server Database Projects
SQL Server Database Projects is a powerful tool that has its own pros and cons. In this section, we compare them to other ways of developing and deploying SQL Server databases. If you're fmiliar with database projects, you may skip this section.
Benefits over designer tools (SQL Server Management Studio)
Developing databases using SQL Server Database Projects has many advantages over using a database designer tool such as SQL Server Management Studio:
- The database model can go to the source control along with the code changes. This is very helpful to track the changes when many developers work on the same database.
- Since changes are tracked in the source control, models can be designed and edited by multiple developers at the same time. They can be aware of the conflicts at the earliest possible time.
- Databases can be deployed on multiple targets. For example, one may decide to deploy the database to SQL Azure instead of a local SQL Server.
- It is possible to compare the deployed database with the source code at any point of the time to analyze changes or fix the problems.
- Recreating and republishing the database is very fast. This is very useful for testing purposes in the development phase because it makes it very easy to populate the database with testing data.
- Many syntax errors in the script files can be caught at the compile time. For example, when a developer removes a field from the database, Visual Studio finds all views that use that field and raises compile errors for them. This functionality is not available in SQL Server Management Studio, and the developer may remove a field from a table without changing the related views, and it will cause runtime errors after deployment.
- Static code analysis of scripts becomes possible. There are some potential issues that can be found by performing static analysis. For example, the developer may forget to assign it in one of the execution paths due to the complexity of the code, but output variables of stored procedures should be assigned in all paths. Static code analysis can find this issue and report it in the compile time. It is very useful to solve the issue before shipping the product and debugging a logical error that happens a few months later.
Benefits over Entity Framework Code First
Entity Framework Code First is a very common way of developing SQL Server databases, but it has its own limitations. Here is a list of the advantages of using Database Projects over Code First approach:
- It is not tied to a certain framework like Entity Framework.
- All features of T-SQL can be used in the design and the development of the database.
- It provides a better support for developing stored procedures.
- SQL static code analysis for stored procedures is not possible with Entity Framework.
- Debugging the potential problems in the scripts is usually easier than finding problems in a complex ORM model. The automatically generated scripts of the entity framework may become unpredictable and very hard to handle.
- Performance tuning is a lot easier. For example, it is less likely that the developer forgets to put the maximum length for a field or to define proper indices.
Benefits over the Migration approach
- Changes of a certain database object (table, view, stored procedure) can easily be tracked in the source control.
- Re-creating and republishing the database is easier because visual studio keeps the publish profiles and has easy to use user interfaces for database publishing. In migration approach, the programmer needs to manage this in the code.
- Multiple developers can work on the same database object and merge their changes. It is not easy to change a stored procedure in the migration approach. For example, two developers may change the same stored procedure code and the latest change will override the previous ones.
It is noteworthy to say that using SQL Server Database Projects can be mixed with the Migration approach that is itself an interesting subject to be experienced.
Disadvantage
The biggest disadvantage of the States approach is that there is no straight way to handle data manipulation. When the database is deployed to production, it will contain data. Unfortunately, in the States approach, it is not easy to change this data along with the model changes. For example, let’s say we have “DisplayName” field in a table named “User” that stores the first name and the last name of our users. The product owner asks a new feature to sort the users by their last name. We need to split DisplayName to two columns named “FirstName” and “LastName.” It is easy to add these two columns in the State approach, but there is no easy way to split the data stored in DisplayName field. This was just one example. There are many scenarios that we may not find an easy way in the State approach.
Why SQL Server Database Projects?
The Migration approach still seems to be the best way to deploy and update the databases in production (online databases). However, we had a successful experience of using the State approach for small short-term projects. Based on our previous experiences, it is more time consuming to write and test migration scripts and making a decent automation for the deployment of the script to the testing and production environment. So, the development using the State approach is sometimes faster than writing migration scripts.
We have used the State approach in some of our recent projects because of the following reasons:
- The project had a hard, short deadline. We needed to use the fastest possible way to develop the project. Thus, all developers should contribute to the database development.
- It was an on-premise application and the client needed to have good control of the database after the deployment. Thus, using stored procedures for accessing and modifying the database was unquestionable.
We had only one deliverable at the end of the project. All project files should be shipped in one package at the end of the project. It means that we didn’t need online updating or changing the client’s data.
Problem Definition
Database Projects have many features, but they lack the feature of using Visual Studio build configuration in the compile process. Therefore, it is not possible to have different configurations such as Debug, Release, etc. This limitation makes it harder to deploy the database with multiple seed data (or even schema structure). Having this feature can be very helpful even for small projects. For example, it is good to fill the Debug database up with random data for testing but keep only hardcoded data in the Release database.
Solution
Visual Studio projects can perform tasks before and after the build process by calling pre-build and post-build scripts. To explain the solution, we present a step-by-step example. We start with a blank SQL Server Database Project.
First, we create three folders in it (see Figure 1):
- Compare: it is used to store the compare files. Compare files are useful to compare the schema with the published databases.
- Deploy: we store our deployment scripts (Debug, Release, etc.) in this folder.
- Objects: all database objects such as tables and stored procedures are located in this folder.
One of the rather useful features of SQL Database Projects is that it allows the developers to organize their files in any way they need. In other words, the proposed folder structure is not mandatory, and you may define your own structure that fits your project requirements. This structure is different from the default Database Projects’ structure, but we found it very helpful when there are going to be many objects in the database. The principal is that each entity will have all the related files such as table creation, stored procedures, triggers, etc. in the same folder. If a stored procedure performs an action on multiple tables, it should be stored in the folder of the main object that is changing. For example, if “spCompanyInsert” inserts company data in the company table and insert default data for mapping of the users or group, it should be stored in the Company table.
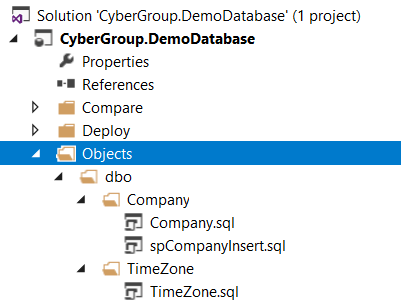
Figure 1. Folder Structure for Database Objects
We add a sample company table (Company.sql) and another table to keep time zone information (TimeZone.sql).
Deploy Folder
In this section, we describe how we can add configuration features by adding post-deployment scripts. The first step is to create the folder structure like the one is shown Figure 2 in and add all necessary files.

Figure 2. Deploy Folder Structure
We explain the files, their purposes and configurations and in more detail in the following:
Common.PostDeployment.sql
“Common” folder contains the script files that should be in the build process of any configuration. We can use this to insert seed data for both Debug and Release configurations. For example, insert statements for TimeZone table can be stored in a file named “Common.PostDeployment.sql” file.
Debug.PostDeployment.sql
The scripts that we need to run for creating our local databases can be stored in “Debug” folder; these scripts may contain seed data for testing purposes. For example, we can insert random data in our Company table in a file named “Debug.PostDeployment.sql.”
Release.PostDeployment.sql
All scripts for the production release can be stored in “Release” folder. For example, we can insert the real seed data that should be used for our Company table.
Script.PostDeployment.sql
We add a post-deployment script to the project to replace its content by our Release or Debug scripts. This script has a special Build Action property named “PostDeploy” that can be set from Visual Studio Properties window shown in Figure 3. There shouldn’t be any content in this file.
Figure 3. Properties Window of Script.PostDeployment.sql
prebuild.ps1
We add a PowerShell script to change the content of our Script.PostDeployment.sql file by Debug or Release scripts. Here is the content of this file:
We add a PowerShell script to change the content of our Script.PostDeployment.sql file by Debug or Release scripts. Here is the content of this file:
Param (
[string] $ProjectDir = "",
[string] $ConfigurationName = ""
)
$ErrorActionPreference = "Stop"
write-host '----------Creating PostDeployment script Started ------------'
write-host ('ProjectDir=' + "$ProjectDir")
write-host ('ConfigurationName=' + "$ConfigurationName")
sp ("$ProjectDir" + "Deploy\Script.PostDeployment.sql") IsReadOnly $false
Get-Content ("$ProjectDir" + "Deploy\Common\*.sql"),("$ProjectDir"+ "\Deploy\"+ "$ConfigurationName" + "\*.sql") > ("$ProjectDir" +"Deploy\Script.PostDeployment.sql")
write-host '----------Creating PostDeployment script Successful ------------'
exit $LastExitCode
“$ProjectDir” and “$ConfigurationName” are two parameters are defined as an input for the script. $ProjectDir is a string that contains the directory path where the project is located. $ConfigurationName has the configuration setting from Visual Studio such as “Debug” or “Release.” Both values are set in Visual Studio Pre-Build Events commands.
The purpose of the statement “$ErrorActionPreference = ‘Stop’” is to stop the build if any error happens in the compiling. As “Script.PostDeployment.sql” may be read-only, we need to make it writable first by using “sp” command. Afterward, the content of the file will be replaced by the merging all script files in “Deploy\Common” folder and “Deploy\Debug” or “Deploy\Release.” In this example, we have only one file under each folder, but as you can see in the script, it merges all the files. You need to be careful about the execution order if you are going to have more than one file in those folders. At last, we exit PowerShell by the putting the exit code of the last command (“exit $LastExitCode”). If we don’t pass exit codes for errors, Visual Studio will continue deploying the erroneous scripts. So, if you are going to modify this behavior, make sure that you consider error exit codes.
The next step is to configure the project’s pre-built and post-build commands to integrate with our Visual Studio build process. This configuration is shown in Figure 4. We add the following command in the Pre-build Events section:
powershell -NoProfile -ExecutionPolicy RemoteSigned ^& '$(ProjectDir)Deploy\prebuild.ps1' -ProjectDir '$(ProjectDir)' -ConfigurationName '$(ConfigurationName)'
Figure 4. Project Build Events Dialog
This runs our “prebuild.ps1” script in PowerShell with the provided configuration. Extra switches let Visual Studio run PowerShell without being in Administration mode. As pre-build changes the content of our Script.PostDeployment.sql file, and we don’t need to store these changes in the source control, we need to replace this file with its old content (empty content). We can do this by using a copy command in Post-Build event:
COPY "$(ProjectDir)\Deploy\Empty.PostDeployment.sql" "$(ProjectDir)\Deploy\Script.PostDeployment.sql" /y
Publish File
It is time to publish the database to our local SQL Express. We create a publish file by right-clicking on the project and selecting “publish…” menu. This is shown in Figure 5.
Figure 5. Publish Menu
The publish dialog appears. Click on “Edit” button and select your SQL Express. Then write the database name under “Database Name:” field. Let’s call the database “CyberGroup.Demo.” The good thing is that the Publish dialog will create the database in SQL Express if it does not exist. This dialog is shown in Figure 6.
Figure 6. Publish Dialog
The Publish dialog has many advanced settings. For example, it can recreate the database every time we need a new deployment. To change these settings, we need to click on the “Advanced…” button. This dialog is shown in Figure 7. As this is our local development database, we would like to select “Always re-create database” to recreate everything from scratch every time we publish the database project. This simplifies the development process significantly. The developers do not need to worry about the migrations and changes of field names or database objects. They can easily recreate the database every time there is a change in the database. This may not seem to be a good idea for big databases, but it works very well for small databases. In addition, it is possible to break big databases to smaller ones by creating separate database projects; this process is out of the scope of this paper.
Figure 7. Publish Profiles Advanced Settings
We use “Save Profile” to save the file with name “CyberGroup.DemoDatabase.local.publish.xml” in the project root folder. The file name is not important. We store it in root to easily find it every time we need a new publish. This file can also go to the source control to let other developers deploy the project on their machines.
The magic is set. All we need to do now is set Visual Studio to build in Debug or Release mode and run the publish file (by double-clicking) from the root folder.
Summary
Visual Studio SQL Server Database Projects speed up the development of small databases. We have used it successfully in the past. Unfortunately, these projects lack many features. One of the most useful, needed features was to configure the build process based on Visual Studio build configurations such as Debug, Release, etc. We decided to add this feature and share our experience with you in this paper. We did this by modifying Pre-Build and Post-Build events and using PowerShell scripts.
History
First version published 12/30/2018 (Thanks to Brad Darby for proofreading and editing).

