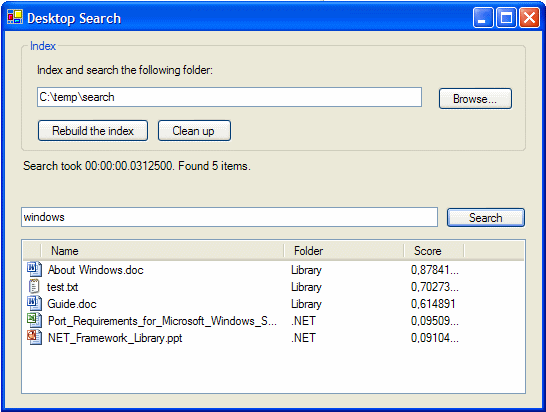
Introduction
Let's take the following exercise: Build a C# application that instantly searches your Documents folder. We need the application to:
- Search the contents of Office documents (Word, Excel, PowerPoint). I.e., XLS, DOC, PPT files.
- Search the contents of HTML documents.
- Search the contents of text documents.
- Search quickly (i.e., give results in less than a second).
- Allow to open the documents directly from the results list.
Update: This Desktop Search application is now part of the Seekafile Server 1.0 - Open-Source Indexing Server. The server provides automatic indexing on the background, and you can search the index through a Windows Forms client search application. See also the Seekafile Server roadmap.
Task 1: Full-Text Indexing
For the indexing and searching, we will use an excellent search engine called DotLucene. It's a C# port of Java Lucene, maintained by George Aroush. It has many great features:
- Very good performance.
- Ranked search results.
- Search query highlighting in results.
- Searches structured and unstructured data.
- Metadata searching (query by date, search custom fields...).
- Index size approximately 30% of the indexed text.
- Can also store fully indexed documents.
- Pure managed .NET in a single assembly.
- Very friendly licensing (Apache Software License 2.0).
- Localizable (support for Brazilian, Czech, Chinese, Dutch, English, French, German, Japanese, Korean, and Russian included in the DotLucene National Language Support Pack).
- Extensible (source code included).
For more details on creating the index and searching, see my previous article: DotLucene: Full-Text Search for Your Intranet or Website using 37 Lines of Code.
Task 2: Parsing Office Documents
As DotLucene can index only plain text, we need to parse the Office documents and extract text from them. Reading their binary structure isn't an easy job. However, on Windows 2000+, we can use the IFilter interface which is a part of the Windows Indexing Service. This is installed by default on all Windows 2000+ systems (no Office installation is required).
The IFilter API is also being used by the Windows Desktop Search (MSN Search Toolbar) and Lookout, so you don't have to be afraid that we will use something obscure to parse the documents. It can also parse other file types if you install the appropriate filter.
Working with the IFilter interface requires a lot of COM interop which is a bit tricky. After tweaking the samples available on the web, I finally had a code that worked correctly in most cases:
public static string Parse(string filename)
{
IFilter filter = null;
try {
StringBuilder plainTextResult = new StringBuilder();
filter = loadIFilter(filename);
STAT_CHUNK ps = new STAT_CHUNK();
IFILTER_INIT mFlags = 0;
uint i = 0;
filter.Init( mFlags, 0, null, ref i);
int resultChunk = 0;
resultChunk = filter.GetChunk(out ps);
while (resultChunk == 0)
{
if (ps.flags == CHUNKSTATE.CHUNK_TEXT)
{
uint sizeBuffer = 60000;
int resultText = 0;
while (resultText == Constants.FILTER_S_LAST_TEXT || resultText == 0)
{
sizeBuffer = 60000;
System.Text.StringBuilder sbBuffer =
new System.Text.StringBuilder((int)sizeBuffer);
resultText = filter.GetText(ref sizeBuffer, sbBuffer);
if (sizeBuffer > 0 && sbBuffer.Length > 0)
{
string chunk = sbBuffer.ToString(0, (int)sizeBuffer);
plainTextResult.Append(chunk);
}
}
}
resultChunk = filter.GetChunk(out ps);
}
return plainTextResult.ToString();
}
finally
{
if (filter != null)
Marshal.ReleaseComObject(filter);
}
}
Assembling the Application
In short:
- The index can only be built from scratch.
- We are not returning the sample of the found document.
- We are skipping the files that can't be parsed successfully.
- We are loading the associated explorer icon for each document in the results.
- You can choose the folder to be indexed; by default, it's your Documents folder.
- The indexed file types are hard-coded (txt, htm/html, doc, xls, ppt).
- The index is stored in your profile in the Local Settings/Application Data/DesktopSearch folder.
- Remember that it is possible to search while the indexing is in progress.
Performance
Some statistics (Athlon XP 2000+, 1GB RAM, Seagate SATA drive 7200 RPM):
- Documents indexed: 1185
- Total size of indexed documents: 120,690,622 bytes
- Rebuilding the index took: 5 minutes 55 seconds
- Index size: 4,339,950 bytes
- Search time (including the rendering on display): from 0.0937 seconds (25 found items) to 0.3125 seconds (213 found items)
To Be Continued...
In the next part of the article, we will extend this simple application with the following features:
- The indexing will be handled by a separate application which will update the index continuously on the background.
- The results will contain a sample of the document with highlighted query words.
- We will index and search the file name and the last modified date.
Resources and Acknowledgements
Search Engine:
Seekafile Server - Open-Source Indexing Server
Office Documents Parsing:
Appearance:


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




