Introduction
I have spent all of my life avoiding regular expressions. I have spent the last ten years doing so deliberately, and with great effort. Occasionally, I’d break down and read an article on the subject, or buy yet another regular expressions book. In that time, I have learned two foreign languages, because that was easier than learning regular expressions.
But it has all come to naught, I’m afraid. .NET has great support for regular expressions, and it’s hard to do input validation without them. My breaking point came this past week, as I wrote yet another complicated method to validate a comma-delimited list of integers. “Lemme see—I can try to split the string, and use a catch if it fails. Assuming it succeeds, I can walk through the list, and call Int32.TryParse() on each element. If all that succeeds, then the list validates.”
I decided that I’d better add an alarm bell to wake up the user when all that was done! Thinking that there had to be a better way, I dug out my books on regular expressions and started wading through them again. An overwhelming sense of despair hit me faster than you can say “I really, really hate this stuff!” And then I began to ask myself “Why?”
Well, for one thing, just about every article and book out there is geared towards using regular expressions in text searches, rather than input validation. For another, the open-source regular expression tools available on the web are incredibly complicated. This stuff ought to be simple! Well, that’s what we are going to do in this article—make regular expressions simple. By the time you are done, you will be able to write simple validators, and you will know enough about regular expressions to dig into it further without slitting your wrists.
The Regex Tester
The project that accompanies this article contains a little application called Regex Tester. I have also included an MSI file to install the binary, for those who do not want to compile the application themselves.
Regex Tester is so simple as to be trivial. In fact, it took longer to create the icon than it took to code the app! It has a single window:
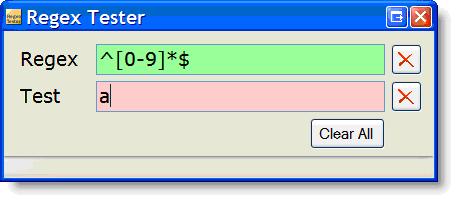
The Regex text box contains a regular expression (a ‘regex’). The one shown here matches a string with an unsigned integer value, with an empty field allowed. The Regex box is green because the regex is a valid regular expression. If it was invalid, the box would be red (okay, pink) like the Test box.
And speaking of the Test box, it’s red because its contents don’t match the pattern in the Regex box. If we entered a digit (or digits) in the Test box, it would be green, like the Regex box.
We’ll use Regex Tester shortly. But first, let’s give some thought to the mechanics of validating user input.
Validating User Input
There are three ways to validate user input:
- Submission validation: We can validate an entire form at one time, when it is submitted.
- Completion validation: We can validate each field as it is completed.
- Key-press validation: We can validate a field as each character is entered.
I recommend against relying on submission validation in a Windows Forms application. Errors should be trapped sooner, as close to when they are entered as possible. Nothing is more annoying to a user than a dialog box with a laundry list of errors, and a form with as many red marks as a badly-written school paper is not far behind. The rule on validation is the same as the rule on voting in my home town of Chicago: “Validate early, and validate often.”
The Validating Event
Windows provides a Validating event that can be used to provide completion validation for most controls. An event handler for the Validating event typically looks something like this:
private void textBox1_Validating(object sender, CancelEventArgs e)
{
Regex regex = new Regex("^[0-9]*$");
if (regex.IsMatch(textBox1.Text))
{
errorProvider1.SetError(textBox1, String.Empty);
}
else
{
errorProvider1.SetError(textBox1,
"Only numbers may be entered here");
}
}
The first line of the method creates a new regular expression, using the Regex class from the System.Text.RegularExpressions namespace. The regex pattern matches any integer value, with empty strings allowed.
The second line tests for a match. The rest of the method sets the error provider if the match failed, or clears it if the match succeeded. Note that to clear the provider, we set it with an empty string.
To try out the code, create a new Windows Forms project, and place a text box and an error provider on Form1. Add a button to the form, just to give a second control to tab to.
Create an event handler for the text box Validating event, and paste the above code in the event handler. Now, type an ‘a’ in the text box and tab out of it. An error ‘glyph’ should appear to the right of the text box, like this:

If you move the mouse over the glyph, a tool tip should appear with the error message. Much more elegant, and far less jarring, than a message box!
The TextChanged Event
But we can actually do better than that. Add an event handler for the text box TextChanged event, and paste the code from the Validating event into it. Now, run the program, and type an ‘a’ into the text box. The error glyph appears as soon as you type the ‘a’! Now, try this: type ‘1111a’ into the text box. Nothing happens so long as you are typing digits; but as soon as you type the ‘a’, the error glyph appears!
The TextChanged event provides us with a means for performing key-press validation. This type of validation provides the user with immediate feedback when an invalid character is typed. It can be paired with completion validation to provide a complete check of data entered by the user. We will use several examples of key-press-completion validation later in this article.
Validation Sequence
I generally recommend using key-press validators to ensure that no invalid characters are entered into a field. Pair the key-press validator with a completion validator to verify that the contents of the control match any pattern that may be required. We will see several examples of this type of validation, using floating point numbers, dates, and telephone numbers, later in the article.
Submission validation will still be required for some purposes, such as ensuring that required fields are not left blank. But as a rule, it should be relied on as little as possible.
Validating with Regular Expressions
Now that we have seen how to validate, let’s build some regular expressions to use as validators. We will start with the simplest expressions, then work our way up to some fairly sophisticated ones.
A regular expression is nothing but a coded string that describes a pattern. For example, consider the following:
*.doc
That’s not even a real regular expression. It’s from Microsoft Word, specifically the Open File dialog box. It is a coded string that means “Show me any file with a ‘.doc’ extension. Regular expressions work the same way. The Microsoft Word example also points out an important point: don’t expect regex symbols to mean the same things you may have seen elsewhere. As we will see shortly, the asterisk character has a different meaning in regular expressions than it does elsewhere. That’s true of most other symbols, as well.
Okay—at this point, fire up Regex Tester, because we are going to be using it from this point forward.
A validator’s two best friends are ‘^’ and ‘$’. These two symbols mark the beginning and end of a line, respectively. Enter this into the Regex box of Regex Tester:
^$
The Regex box turns green, indicating that the regex is valid. The Test box is also green, indicating that an empty string is allowed. Now type something, anything, in the Test box. It doesn’t matter what you type, the Test box will turn red. That’s because our regex reads as follows: “Match any string that has a beginning-of-line, followed immediately by an end-of-line.” In other words, match an empty string and nothing else.
In other words, the ‘^’ character denotes the beginning of our validation string, and the ‘$’ character denotes its end. These two symbols are the key to validation using regular expressions. They require a match to be complete and exact. That’s different from a search, where the target string need only be contained somewhere in the text being searched.
To see how this works, try this: Enter:
^4$
into the Regex box. The regex reads: “Match any string that has a beginning-of-line, followed by the character ‘4’, followed immediately by an end-of-line.” Since the input we are validating would nearly always consist of a single line, the regex can be read “Match any string that has a beginning-of-string, followed by the character ‘4’, followed immediately by an end-of-string.” Or, more simply, “Match any string that has the character ‘4’, and nothing else.”
After you enter the regex, the empty Test box is red, because the regex doesn’t match an empty string. Let’s experiment with the regex:
- Now type ‘4’ (no quotes, you get the idea) into the Test box. It turns green.
- Replace the ‘4’ with any other character, and the box turns red. Only a ‘4’ is allowed.
- Delete the other character, and type a ‘4’ in the Test box. It turns green. Add a second character—anything you like. The Test box turns red. Only a single character is allowed.
Now, let’s modify the regex by taking away its ‘^’ and ‘$’ characters. Click the Clear button to clear both boxes, and type ‘4’ (you remembered about the no quotes, didn’t you?) into the Regex box. It turns green, indicating a valid regex. Now, we have the same regex as before, except without the beginning-of-line and end-of-line specifications. It reads: “Match any string that contains a ‘4’.”
Now, let’s experiment with the modified regex:
- Type a 4 into the Test box, just as before. It, too, turns green, indicating a match.
- Type any character after the ‘4’ in the Test box. The Test box remains green! That’s because the string still contains a ‘4’.
- Delete the characters in the Test box and type in any character. The Test box turns red, since the string doesn’t contain a ‘4’. Now type in a ‘4’. The box turns green.
In short, the ‘^’ and ‘$’ characters specify an exact match. In most validations, we need exact matches; that’s why the ‘^’ and ‘$’ characters are so important. You will almost always use them in regex validators.
Some Useful Validations
So far we haven’t done any validations that we can really use. So, let’s build up to that now. Enter the following in the Regex box:
^[0-9]$
Now, type any single digit into the Test box. The box is green. But if you type another digit, it turns red. That’s because the regex reads: “Match any string that consists of a single digit between 0 and 9.” The ‘[0-9]’ code (called a character class) specifies a single digit, which can be any digit between zero and nine.
Let’s add some flexibility. Add an asterisk after the closing bracket of the character class, so that the regex looks like this:
^[0-9]*$
The regex now reads: “Match any string that consists of a sequence of zero or more digits”. Notice that the Test box is green—that means empties are allowed, as indicated by our “zero or more” reading of the regex.
To verify, type in any number of digits in the Test box. It stays green. But type in any other character, and the box turns red. What we have just done is create a regex that can validate a text box as containing an integer.
Clear the boxes, and enter the same regex again. Now, replace the asterisk with a plus sign. Now the regex reads: “Match any string that consists of a sequence of one or more digits”. Empty strings are now disallowed.
When you change the asterisk to a plus sign, the empty Test box should turn red, since empties are no longer allowed. Otherwise, the box behaves just as it did before. The only difference between the asterisk and the plus sign is that the asterisk allows empties, and the plus sign doesn’t. As we will see later, these symbols can be applied to an entire regex, or to part of a regex. We will see how, when we look at grouping.
Optional Elements
The validators we worked with in the last section will validate integers, but not real numbers. Use either of the preceding regexes, and enter the following number: ‘123.45’. The box turns red as soon as you enter the decimal point. So, we need some way to accommodate decimals.
Let’s try this regex:
^[0-9]+\.$
The backslash-period that we added changes the meaning of the regex to: “Match any string that contains a sequence of one to any number of digits, followed by a decimal point.” By the way, we had to enter backslash-period because the period is a special character in regular expressions. Putting the backslash in front of the period ‘escapes’ it, indicating that we mean a literal period, and not the special character.
Type ‘123.45’ into the Test box. This time, the box should be red until you enter the decimal point. Then it turns green, until you enter the 4, when it turns red again. Clearly, we have some more work to do.
The Test box turned red until you hit the decimal point because it is a required character. No matter how many numbers you enter, they must be followed by a decimal point. That would work fine for a completion validator, but it won’t work for a key-press validator. In that case, we want to allow the period, but not require it.
The solution is to make the period optional. We do that by putting a question mark after the period, like this:
^[0-9]+\.?$
Try it in Regex Tester, entering 123.45 once again. The Test box will stay green until you type the ‘4’, at which point it will turn red again. We have taken care of the decimal-point problem, but we still need to do something about the numbers that follow it.
Our problem is that the decimal point is the last item specified in the pattern. That means, nothing can come after it. But we want more numbers to come after it! Then we should add them to our pattern, like this:
^[0-9]+\.?[0-9]*$
Try that pattern in the Regex box, and type ‘123.45’ in the Test box. The box should be red when it is empty, but green when an integer or a real number is typed into it. Note that for the decimal portion of the number, we used an asterisk, instead of a plus sign. That means, the decimal portion can have zero elements—we have, in effect, made the decimal portion of the number optional, as well.
There is only one problem that remains. Let’s assume we have a text box that we need to validate for a real number, and that an empty is not allowed for this text box. Our current validators will do the job for a completion validator, but not for a key-press validator. Why not?
Try this: select after the number in the Test box, then backspace until you remove the last digit. When you do, the box turns red. That means, if the user starts entering a number, then deletes it by backspacing, a glyph is going to pop up. To the user, that’s a bug. What it means for us is that we need slightly different regexes for the two validators. The key-press regex should disallow empties, but the completion regex needs to allow them.
To do that, change the plus sign in the regex to an asterisk, so that the regex looks like this:
^[0-9]*\.?[0-9]*$
Now, the Test box is green, even when it is empty. Use this modified regex in the key-press validator. This approach gives us the best of both worlds; the user gets immediate feedback while entering the number, and empties are flagged as errors without getting in the user’s way.
Validator pairs
The preceding examples point out the need for validator pairs. In many cases, we need a key-press validator to ensure that no invalid characters are entered, and a separate completion validator to ensure that the field matches whatever pattern is required.
Groups and Alternates
By now, you should be getting the hang of simple validators. Regular expressions are as powerful as you want them to be—they constitute a language all their own. But as you have seen, you can get started with just a few elements. Here are some other handy elements of regular expression syntax:
Groups: Parentheses are used to group items. Here is a regex for the comma-delimited list of integers I mentioned earlier:
^([0-9]*,?)*$
Here is how to read it: “Match any string that contains zero or more groups of integers. Each group consists of zero or more digits, and may be followed by a comma.” The parentheses set the boundaries for the group. Note that the asterisk after the closing parenthesis means the entire group may repeat zero or more times.
Alternates: Sometimes, we need ‘either-or’ logic in our validations. For example, we may want to allow commas, or commas followed by spaces. We can’t do that with our current regex. In the Test box, try entering a space after one of the commas. The Test box turns red, because space characters aren’t allowed by the pattern.
We can modify the pattern to allow spaces, by using a feature known as alternates. Alternates are specified by using the pipes (|) character within a group. Here is how the last regex looks when we allow a comma-space combination as an alternative to a simple comma:
^([0-9]*(,|, )?)*$
Note that there is a space after the second comma in the regex. The group with the commas now reads: “…followed by a comma, or a comma and a space…”
Now, type in a comma-delimited list of integers with a space after each comma. The Test box stays green, so long as you enter only a single space after each comma.
But suppose you want to let the user type an unlimited number of spaces after each comma? Here is an opportunity to test yourself. See if you can modify the last regex to allow unlimited spaces. Don’t peek at the answer until you have given it a try.
The simple answer is to add an asterisk after the space in the alternate group:
^([0-9]*(,|, *)?)*$
That regex will work, but we can tweak it a bit to make it more elegant. The comma-space-asterisk alternate means: “Followed by a comma, followed by zero or more spaces.” But that makes the first alternate redundant. And that means, we can delete the first alternate entirely, which brings us to the final answer:
^([0-9]*(, *)?)*$
Again, note the space after the comma. This solution is both shorter and easier to understand than our original solution.
Hopefully, this exercise gives you a feel for the process of developing a regular expression. They are not ‘written’; instead, they are built, layer-by-layer, like a pearl in an oyster. A tool like the Regex Tester lets you continually test the expression as you develop it.
Other Types of Data
Other types of data are actually easier to validate, because their patterns are more fixed. Let’s take a look at a couple of them.
Dates: As with numbers, we need two validators: a key-press validator, and a completion validator. The key-press validator can be pretty simple, if we limit how our user enters the date. Let’s say that we want to validate for the U.S. date format mm/dd/yyyy. Here is a validator that will do that:
^([0-9]|/)*$
The regex reads: “Match any string that contains a sequence of zero or more characters, where each character is either a digit or a slash.” This validator will give the user immediate feedback if they enter an invalid character, such as an ‘a’.
Copy that regex to Regex Tester and give it a try. Note that the validation fails if the user enters dashes, instead of slashes, between the parts of the date. How could we increase the flexibility of our regex to accommodate dashes? Think about the question for a minute before moving on.
All we need to do is add a dash to the alternates group:
^([0-9]|/|-)*$
We could add other alternates to make the regex as flexible as it needs to be.
The completion validator does a final check to determine whether the input matches a complete date pattern:
^[0-2]?[1-9](/|-)[0-3]?[0-9](/|-)[1-2][0-9][0-9][0-9]$
The regex reads as follows: "Match any string that conforms to this pattern: The first character can be a 0, 1, or 2, and it may be omitted. The second character can be any number and is required. The next character can be a slash or a dash, and is required…” And so on. This regex differs from the ones we used before in that it specifies each character of the pattern—the pattern is more of a template than a formula.
Note the first character of the regex: ‘[0-2]’. This character points out that we can limit allowable digits to less than the full set. We can also expand them; for example, ‘[0-9A-F]’ would allow any hexadecimal digit. In fact, we can use this structure, known as a character class, to specify any set of characters we want. For example, the character class ‘[A-Z]’ allows capital letters, and ‘[A-Za-z]’ allows upper or lower-case letters.
Our date regex also points out some of the limitations of regex validation. Paste the date regex shown into Regex Tester and try out some dates. The regex does a pretty good job with run-of-the-mill dates, but it allows some patently invalid ones, such as ‘29/29/2006’, or ‘12/39/2006'. The regex is clearly not ‘bulletproof’.
We could beef up the regular expression with additional features to catch these invalid dates, but it may be simpler to simply use a bit of .NET in the completion validator:
bool isValid = DateTime.TryParse(dateString, out dummy);
We gain the additional benefit that .NET will check the date for leap year validity, and so on. As always, the choice comes down to: What is simpler? What is faster? What is more easily understood? In my shop, we use a regex for the key-press validator, and DateTime.TryParse() for the completion validator.
Telephone numbers: Telephone numbers are similar to dates, in that they follow a fixed pattern. Telephone numbers in the US follow the pattern (nnn) nnn-nnnn, where n equals any digit. But creating a regex for a telephone number presents a new problem: How do we include parentheses in our pattern, when parentheses are special characters that specify the start and end of a group?
Another way of stating the problem is: We want to use parentheses as literals, and not as special characters. To do that, we simply escape them by adding a backslash in front of them. Any special character (including the backslash itself) can be escaped in this manner.
Backslash characters are also used for shortcuts in regular expressions. For example, ‘\d’ means the same thing as ‘[0-9]’. We’ll see it in our next example.
Take a moment, and try your hand at creating key-press and completion validators for a U.S. telephone number. Here is my key-press validator:
^(\(|\d| |-|\))*$
Note that it uses the ‘\d’ shortcut. The regex reads: “Match any string that contains only open-parentheses, or digits, or spaces, or dashes, or close-parentheses.”
The key-press validator will ensure that invalid characters are not entered, but it will not perform a full pattern matching. For that, we need a separate completion validator:
^\(\d\d\d\) \d\d\d-\d\d\d\d$
This validator specifies the positions of the parentheses and the dash, and the position of each digit. In other words, it verifies not only that all characters are valid, but that they match the pattern of a U.S. telephone number.
Neither one of these regular expressions is bulletproof, but they will give you a good starting point for developing your own regular expressions. If you come up with a good one, why not post it as a comment to this article?
Where to Go From Here
We have barely scratched the surface of regular expressions, but we have accomplished what we set out to do. At the beginning of this article, I promised that you would be able to write simple validators, and that you would know enough to dig further into the subject. At this point, you should be able to do both.
There are thousands of regular expression resources on the Web. I would particularly recommend the following two web sites:
- Regular-Expressions.info: This site has a tutorial, examples, and references to other resources.
- RegExLib.com: This site is primarily a library of regular expressions submitted by site users.
Also worthy of note is The 30 Minute Regex Tutorial, an article on CodeProject. It includes a nice regex utility called Expresso. The reason I didn’t write a more sophisticated regex app is because Jim Hollenhorst had already written Expresso. Definitely worth a look.
I’ll be happy to answer any questions posted here, but please keep in mind I don’t claim to be a regular expression guru (just yet). If you’re trying to whip up a particularly complex regex, my answer is likely to be “Beats the heck out of me!”
Instead, you might try the various user forums connected to web sites devoted to regular expressions. Other good resources are NNTP newsgroups—see Google Groups for listings. I don’t believe there are newsgroups dedicated to regular expressions (who in their right mind would hang out there?), but the following groups seem to get a fair number of questions about regular expressions:
- microsoft.public.dotnet.languages.csharp
- microsoft.public.dotnet.languages.vb
- comp.lang.java.programmer
As for me, I’m going to get onto something else while I still can—I am really worried that regular expressions are starting to make sense to me!
David Veeneman is a financial planner and software developer. He is the author of "The Fortune in Your Future" (McGraw-Hill 1998). His company, Foresight Systems, develops planning and financial software.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




