Introduction
The goal of Irony, a new open source project, is to build a complete set of libraries and tools for language implementations in the .NET platform. It is currently in its first phase, which includes building the two compiler front-end modules - scanner and parser. This article provides an overview of the technology, and focuses on parser implementation with Irony. The project is hosted at CodePlex.
Irony brings several principal innovations into the field of compiler construction. Like many parser-building tools in use today, Irony produces a working parser from grammar specifications. However, unlike the existing parser builders, Irony does not use a separate meta-language for encoding the target grammar. In Irony, the grammar is encoded directly in C# using BNF-like expressions over grammatical elements represented by .NET objects. Additionally, no code generation is employed - Irony's universal LALR parser uses the information derived from C#-encoded grammar to control the parsing process.
Using the code in the download
The download supplied with this article contains Irony's core assembly, the Grammar Explorer application, and a set of sample parsers: a parser for arithmetic expressions, and parsers based on simplified grammars for Scheme, Python, and Ruby. With Grammar Explorer, you can view the analysis data for sample grammars and test the parsers on source samples. The following image shows a source sample and its parsed syntax tree in the Grammar Explorer:
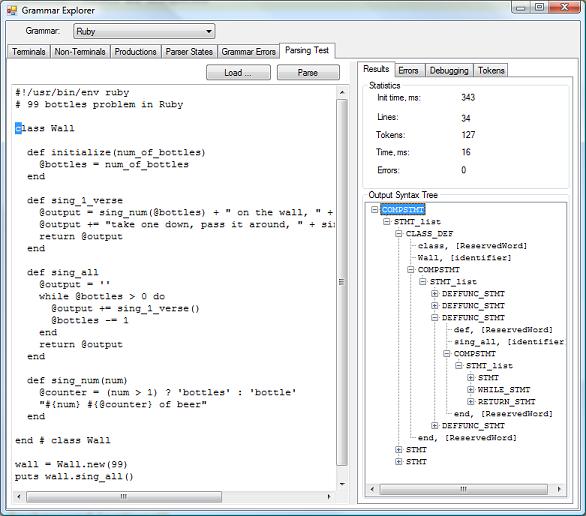
In order to try out the project:
- Download and unzip the source files
- Open the Irony_all.sln solution file in Visual Studio
- Set the GrammarExplorer project as a startup project
- Build and run the application (F5)
- When the Grammar Explorer's window opens, select the grammar in the top combobox and explore the grammar data
- Load source code sample from the Irony.Samples\SourceSamples folder
- Parse the source and explore the output syntax tree
Background
Many modern applications use parsing technologies in one form or another. Compiler development is one area that heavily employs parsers. The other examples are script engines and expression evaluators, source code analysis and refactoring tools, template-based code generators, formatters and colorizers, data import and conversion tools, etc. Therefore, it is important that application developers have reliable and straightforward methods of implementing a parser when one is needed. Unfortunately, this is not the case - with the current state of technology, constructing a parser is still a big challenge.
In the author's opinion, the reason for this is the fact that parser construction technology did not change much since the introduction of LEX/YACC generators in the mid-seventies. Most of the generators in use today are ports or derivatives of these original tools. Many things have changed, new languages and technologies have been introduced, OOP being probably the most prominent example. But somehow, these advances didn't make into parser construction technology. Same plain C-style generated code, even in Java- or C#- targeted parsers, with the same global variables and even the same yy- naming conventions.
Irony is an attempt to fix the situation, to bridge the existing gap, and to bring the power of a modern language environment like C# and .NET into the parser and compiler construction field.
Simple Expression Parser
To illustrate how Irony's approach is different, let's use it to build a parser for simple arithmetic expressions. We will target expressions that contain only numbers, variables, parenthesis, and the arithmetic operators +, -, *, /, and **.
The first step is to write a formal grammar for the expression language using the Backus-Naur Form (BNF) notation:
Expr -> n | v | Expr BinOp Expr | UnOp Expr | ( Expr )
BinOp -> + | - | * | / | **
UnOp -> -
ExprLine -> Expr EOF
Our grammar has four non-terminals: Expr, BinOp, UnOp, and ExprLine - shortcuts for expression, binary operation, unary operation, and expression line. The ExprLine is the top-level element of our grammar representing the complete expression terminating with the EOF (end-of-file) symbol.
Our grammar references several terminals: n (number), v (variable), and symbols for arithmetic operators and parenthesis. Terminal symbols are elements that are predefined for grammar rules - they don't have a definition in the grammar. Terminals represent primary indivisible words (tokens) in the input stream and are produced by an input pre-processor called the Scanner or Lexer. Non-terminals, on the other hand, are compound elements, and their internal structure is defined by BNF expressions.
To define this grammar in Irony, we create a new class inherited from the Irony.Compiler.Grammar base class:
using System;
using System.Collections.Generic;
using System.Text;
using Irony.Compiler;
namespace Irony.Samples {
public class ExpressionGrammar : Irony.Compiler.Grammar {
public ExpressionGrammar() {
Terminal n = new NumberTerminal("number");
Terminal v = new IdentifierTerminal("variable");
NonTerminal Expr = new NonTerminal("Expr");
NonTerminal BinOp = new NonTerminal("BinOp");
NonTerminal UnOp = new NonTerminal("UnOp");
NonTerminal ExprLine = new NonTerminal("ExprLine");
Expr.Expression = n | v | Expr + BinOp + Expr | UnOp + Expr |
"(" + Expr + ")";
BinOp.Expression = Symbol("+") | "-" | "*" | "/" | "**";
UnOp.Expression = "-";
ExprLine.Expression = Expr + Eof;
this.Root = ExprLine;
RegisterOperators(1, "+", "-");
RegisterOperators(2, "*", "/");
RegisterOperators(3, Associativity.Right, "**");
PunctuationSymbols.AddRange(new string[] { "(", ")" });
}
}
}
The entire grammar is defined in the class constructor. First, we define terminal and non-terminal variables that we will use in grammar rules. We use standard classes defined by Irony. The name parameter in the constructor is used to identify the terminal in listings of grammar data that you see in Grammar Explorer. Notice that we do not need to explicitly create terminals for operator symbols and parenthesis - we will use the string symbols directly in grammar expressions. The Irony grammar processor discovers all these symbols automatically and transforms them into symbol terminals.
Next comes the main part - encoding the grammar rules. Non-terminal objects have a property Expression which is assigned an expression over other terminals and non-terminals. We use C# expressions that look very similar to the original BNF - Irony overloads "+" and "|" operators for syntax element classes so we can write BNF expressions directly in C#!
A few comments on the code. In the expression for BinOp, the first "+" symbol is wrapped into a Symbol(...) method. This method converts "+" into an instance of SymbolTerminal class, so the C# compiler understands correctly the meaning of the first | operation and invokes the overload defined in Irony. Without this wrapper, the compiler would not know how to interpret an expression string | string. The string needs to be wrapped just once when both the initial operands are strings; other operators in the same expression will use the result of the previous operation as an operand - which will be an instance of one of Irony's syntax classes - and operator overloading would work automatically.
The last statement in step 3 sets the ExprLine as the root element of our grammar by assigning it to the Root property of our grammar. This is an entry point into our grammar for Irony; starting from this non-terminal, it can discover the entire grammar tree through the hierarchy of expressions.
Finally, we specify operators' precedence and associativity - this information will be used by the parser to identify the correct grouping of operations. The last statement marks parenthesis as punctuation symbols - they will be excluded from the output syntax tree. Once we have the syntax tree, we don't need such symbols anymore as the order of operations is encoded explicitly in the tree structure.
The following is an example of how to use this grammar to parse an expression:
ExpressionGrammar grammar = new ExpressionGrammar();
LanguageCompiler compiler = new LanguageCompiler(grammar);
string expr = "a + b * 3.14 / (2.0 * x + y**z**2)";
AstNode rootNode = compiler.Parse(expr);
The following image shows the parsed expression tree as it appears in the Grammar Explorer:

The following sections provide a more detailed information on the parsing process as it is implemented in Irony.
Irony Parsing Pipeline
A parser is a program that transforms the source text written in an input language into a tree-like representation called an Abstract Syntax Tree (AST), or simply syntax tree. The tree nodes correspond to the syntactic structures of the input language. Schematically, the process may be represented as follows:
source -> PARSER -> syntax tree
Traditionally, this transformation is performed in two steps. First, the module called scanner combines the sequences of input characters into more meaningful combinations called tokens - the words of the input language. Examples of tokens are numbers, string literals, keywords, special characters, etc. The scanner is sometimes called "lexer" or "tokenizer". The tokens produced by a scanner are then passed to the parser proper that actually constructs the syntax tree from the stream of tokens. The processing schema now changes to the following:
source -> SCANNER -> tokens -> PARSER -> syntax tree
This structure is a standard processing pipeline used by all parsing solutions today. In Irony, this standard schema is extended. Irony adds optional processing modules called Token Filters between the scanner and the parser:
source -> SCANNER -> tokens -> (TOKEN FILTER)* -> tokens -> PARSER -> syntax tree
(The Kleene star indicates "zero or more" objects). We will talk more about token filters and what they are used for in one of the following sections. For now, let's talk about the connection between the modules. Irony uses a bit unconventional method to connect the modules - the pipeline is as a chain of C# iterators. Iterators are a very powerful feature introduced in C# 2.0. To illustrate how it works, let's look at a sample token filter. The following code snippet shows a filter's main processing method. The sample filter does nothing, simply passes all the input tokens to the module in the pipeline:
public override IEnumerable<token /> BeginFiltering(CompilerContext context,
IEnumerable<token /> tokens) {
foreach (Token token in tokens) {
yield return token;
}
}
As the comment in the code indicates, we can easily add or exclude tokens to/from the stream. Using iterators for connecting the modules provides much more flexibility and independence in constructing the individual modules while maintaining a high pseudo-parallelism in the execution. The execution point literally jumps from one module to another while processing the input as the tokens are moved along the pipeline.
Let's now discuss each module in the pipeline in more details.
Scanner
The purpose of the scanner is to group input characters into meaningful words represented by objects called tokens. Examples of tokens are: numbers, string literals, keywords, variables, special symbols like parenthesis, comma, operator symbols, etc. The other responsibility of the scanner is to eliminate whitespace and comments from the input stream, leaving only meaningful content. Irony's Scanner class is a general implementation of a scanner. It is to be used by custom language implementations directly, without inheriting into a custom scanner class. The customized behavior for a particular input language is determined by the list of terminal objects that Irony finds in the language grammar rules.
The expression grammar we just built uses two standard terminal classes: NumberTerminal and IdentifierTerminal. The expression grammar also implicitly definea a number of symbol terminals - all string literals in BNF expressions are converted automatically to SymbolTerminal objects. In Irony, the terminal classes are simply token recognizers. The main recognition method is defined in the base Terminal class:
public virtual Token TryMatch(CompilerContext context, ISourceStream source) {
....
}
The ISourceStream interface represents the input character stream. The language implementor can either use the standard terminals provided with Irony, or create custom terminal classes for language-specific tokens. See the examples of the TryMatch implementations in the standard terminal classes in the article's download.
The following is a simplified description of Irony's scanning algorithm. The scanning process starts at the initial (0) position in the source code. First, the scanner skips all characters that represent whitespace. Once a non-space character is reached, the scanner runs through the list of all defined terminals, and for each, calls the TryMatch method. It tries to find the terminal that can construct a token at the current position in the input. If there are more than one terminal and several constructed tokens, the scanner chooses the "longest" token. This winner token is passed (yielded) to the output stream, and the source position is advanced to the character right after the yielded token. After that, the process is repeated at a new position, and until the end of the source file is reached.
The actual implementation also does some optimization. The scanner does not actually run through all terminals all the time - it uses a hash table to quickly lookup the list of terminals that need to be called based on the current character in the input stream. The lookup table is constructed at initialization time from prefixes that each terminal may explicitly declare. This terminal hash table significantly speeds up the scanning process.
In multiple aspects, the Irony scanner operates differently compared to existing compiler toolkits. First, the scanner completely ignores the whitespace, even for indentation-sensitive languages like Python. However, the indentation information is not completely lost - each token produced by the scanner contains the location (row and column) information. The indentation tokens can be recreated, if necessary, from content tokens later in a dedicated token filter. This arrangement simplifies the general-purpose scanner, and separates the indentation-analysis code into a separate layer (token filter), resulting in a better layered architecture.
Secondly, unlike other LEX-like solutions, the Irony scanner does not need to define hundreds of numeric constants for each distinct token type. The Irony parser matches the tokens to grammar elements directly by their content, so the token type is identified by a containing symbol, e.g., "+", therefore, it can be matched by the parser against a "+" terminal referenced in the grammar.
Finally, in most cases, the Irony scanner does not need to distinguish between keywords and identifiers. It simply tokenizes all alpha-numeric words as identifiers, leaving it to the parser to differentiate them from each other. Some LEX-based solutions try to put too much responsibility on the scanner and make it recognize not only the token itself, but also its role in the surrounding context. This, in turn, requires extensive look-aheads, making the scanner code quite complex. In the author's opinion, identifying the token role is the responsibility of the parser, not the scanner. The scanner should recognize tokens without using any contextual information.
Token Filters
Token filters are special processors that intercept the token stream between the scanner and the parser. Although the term "filter" might suggest that filters only remove some tokens from the stream, they, in fact, are free to remove from or add tokens to the original stream. So, why does Irony introduce this extra processing layer in addition to the traditional scanner/parser pair? The answer lies in the realization that many processing tasks in scanning and parsing are best handled by an intermediate processor that sits between the parser and the scanner. The following are examples of such tasks:
- Implementing a macro expansion.
- Handling conditional compilation clauses.
- Verifying matching pairs of braces/brackets/parenthesis.
- Handling commented-out code blocks. The Scheme programming language allows commenting out blocks of code by prefixing them with the symbol "#;". This type of comment is difficult to handle in the scanner as it requires parser-like token processing to locate the end of the block. At the same time, the parser is not a good place to handle this either, as a parser normally expects only content tokens, without comments or whitespace. A dedicated token filter is an ideal place for implementing this task - after scanning, but before parsing.
- Handling special documentation comment blocks, e.g., XML documentation in C#. The filter can assemble the documentation block from individual comment lines and attach it to the next content token; later, the information can be associated with the syntax node that starts with this token.
- Handling code outlining for indentation-sensitive languages like Python. Tracking this information in the scanner makes things really complicated, and it does not fit well into a general-purpose scanner. A token filter, on the other hand, can handle it easily. The scanner ignores the whitespace in this case, and the filter injects
NewLine, Indent, and Unindent tokens into the stream based on line/column information of the content tokens.
The list above is certainly not all exhaustive. Importantly, implementations can define or reuse several filters in the pipeline, each responsible for its own task. This results in a clear layered architecture, and opens opportunities for wide code reuse.
Irony defines the base class TokenFilter that can be inherited to implement a custom filter. Irony initially provides two filters: BraceMatchFilter for matching open/close block symbols, and CodeOutlineFilter for handling indentation. Several more general-purpose filters are planned for implementation in the future releases.
Parser
After the token stream produced by the scanner passes the token filters, it is consumed by the parser. Irony implements the so-called LALR(1) parser. This type of a parser is considered to be the most efficient, yet difficult to implement. It requires building huge action/transition tables from the language grammar, so LALR parsers are usually generated by parser generators. Irony does not employ code generation; instead, it constructs the transition graph (equivalent of a table) from the language grammar during initialization and uses a general-purpose parser implementation.
An LALR parser is a Deterministic Finite Automaton (DFA) - an abstract machine with a finite number of internal states. The parser state represents a phase in the analysis process of the input stream. Two states are special: initial state and final state. The parser starts in the initial state and moves from one state to another while consuming input tokens and executing the predefined actions, until it arrives at the final state. In each state, it looks at the input token, retrieves the appropriate action from the action table for the current state and input token, executes the action, and moves to the new state. The new state is derived indirectly from the result of the action. When the parser arrives at the final state, the result of the last Reduce action is an AST node for the entire input. It is the node corresponding to the root non-terminal of the grammar. This node is the root of the syntax tree, and is returned as a result of the parsing.
The two main action types that a parser executes are Shift and Reduce (that's why this kind of a parser is also called a shift-reduce parser). Each action manipulates the parser stack - an internal memory buffer. The parser accumulates input tokens in the stack by "shifting" them from the input. At some point, it recognizes that there is a sequence on top of the stack that represents some language construct with the corresponding non-terminal defined in the grammar. The parser then executes the Reduce action - it creates an AST node object corresponding to the recognized non-terminal, and replaces the sequence in the stack with the created node. The newly constructed node receives a list of its child nodes so it can properly link to them. The stack is effectively "reduced" in size in Reduce actions. Thus, the stack contains either tokens shifted from the input by Shift actions, or AST nodes produced by Reduce actions. In fact, they are all AST nodes because the Token class is a subclass of the AstNode class, so token is a trivial AST node.
The final result of the parsing process is a syntax tree for the source text. Normally, each node in the tree would be of a specific type (class) matching the construct it represents. The language implementation would define node classes for all constructs in the language: there will be a node class for the "if" statement, "for" statement, etc. Irony will also predefine some common node types in the future.
In order to know which class is needed to create a node, the parser looks up the type stored in the NodeType property of the NonTerminal object specified in Reduce action. Custom language grammars would normally set this property to appropriate type reference for each non-terminal used in the grammar. If this property is null, then the parser uses the default type GenericNode. Also, additional customization points are provided for AST nodes creation, like the NodeCreator factory method delegate in the NonTerminal class - see the Irony source for more details. Most of the samples in the download use the GenericNode type for all the nodes in the output tree. This is a convenient default node - it has a ChildNodes property that contains a plain list of all child nodes. The sample parser for Scheme in the download provides examples of custom node classes.
Grammar Data
Irony's scanner and parser are implemented as C# classes which are intended to be used as is, without inheriting in custom language implementations. All custom behavior associated with the target language are encoded in the custom grammar class. The list of token filters is also specified in the grammar.
However, Irony does not use the target grammar class directly. Instead, it uses derived information in the GrammarData object that is produced at initialization. This object is used directly by the scanner and the parser. The scanner, in particular, uses the list of all terminals used in the grammar, while the parser uses the State Graph which encodes the behavior of the parsing automaton. Schematically, the information flow looks as follows:
Grammar -> GrammarData -> Terminals -> SCANNER
-> State Graph -> PARSER
The construction of the GrammarData is probably the most complex process in Irony. It uses some sophisticated algorithms well described in compiler construction literature.
LALR Grammars
Any programming language syntax may be expressed in more than one grammar. While these multiple grammars are all equivalent in terms of the language they produce, they are not equally usable by different parsing algorithms. The LALR(1) algorithm used by Irony requires a special kind of grammar - the so-called LALR grammar. All deviations from LALR requirements result in conflicts - situations when the parser wouldn't know what to do, or will have more than one available action. The target grammar therefore must be carefully written and fine-tuned. To make this process easier, Irony provides a Grammar Explorer application that displays grammar analysis data in multiple tabs on the form. This application is included in the download.
One of the tabs in the Grammar Explorer entitled "Grammar Errors" shows all conflicts that were detected during grammar analysis. The language implementor should try to eliminate all errors and warnings by tweaking the grammar, although it is not always possible to eliminate all of them. For ambiguous situations, the parser chooses a preferred action - for example, Shift is preferred over Reduce in shift-reduce conflicts.
Performance
Contrary to the common belief that universal parsers are slow (especially scanners), Irony's parsing is really fast. The initial performance measurements for languages like Python or Ruby give an estimate in between 10 and 20 thousand lines per second for a standard 2GB/2GHz machine, which is impressive, even compared to professional-grade compilers. The initialization time (analyzing the grammar and building the state graph) is about 300 milliseconds, which is acceptable in most cases, but may be a bit too much for production compilers. The initialization time will be reduced in the future by introducing GrammarData serialization to code, so the data will be deserialized at start up instead of rebuilding it from scratch.
Future Development
The ultimate goal of the project is to create a complete set of tools for language implementations on the .NET platform. As for more short term plans, several features are under development:
- Completing the implementation of error recovery mechanisms.
- Implementing a complete set of standard Terminal classes.
- Creating a set of reusable AST Node classes for common syntax constructs.
- Implementing a direct evaluation (interpreter) of the syntax tree, without compiling to IL.
- Creating a basic interactive console.
- Adding support for big integers.
- Implementing back-end parts of the compiler - IL code generation.
- Adding CodeDom support and Visual Studio integration.
- Implementing the
GrammarData serialization to code, so that it can be quickly deserialized from code at start-up like Windows Forms.
More long-term goals include building a runtime infrastructure and implementing back-end parts of the compiler with IL code generation.
Finally, I would like to welcome everybody to participate, both in development of the core feature set, and in language implementations based on Irony.
References
- The "Dragon book": Compilers: Principles, Techniques, and Tools by A.Aho, R.Sethi, J.Ullman.
History
- January 2008 - Initial version.
25 years of professional experience. .NET/c#, databases, security.
Currently Senior Security Engineer, Cloud Security, Microsoft


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









